







1.Azkaban实战
Azkaba内置的任务类型支持command、java
Command类型单一job示例
1、创建job描述文件
vi command.job
#command.job
type=command
command=echo 'hello'2、将job资源文件打包成zip文件
zip command.job
3、通过azkaban的web管理平台创建project并上传job压缩包
首先创建project
上传zip包,例如:
zip包中的内容如下:
上传界面:

4、启动执行该job
可以查看脚本的内容:
执行工作流:

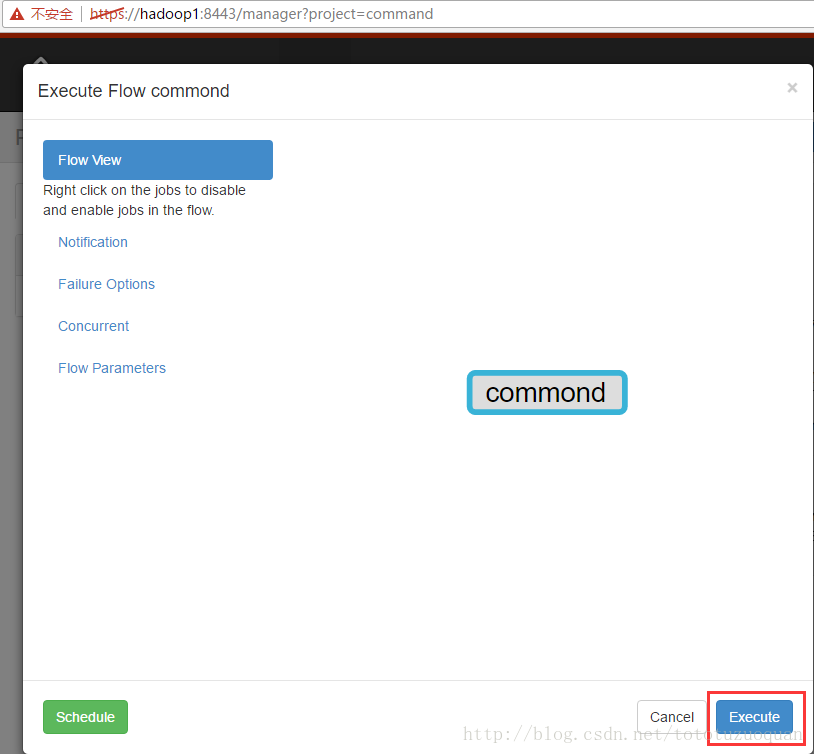
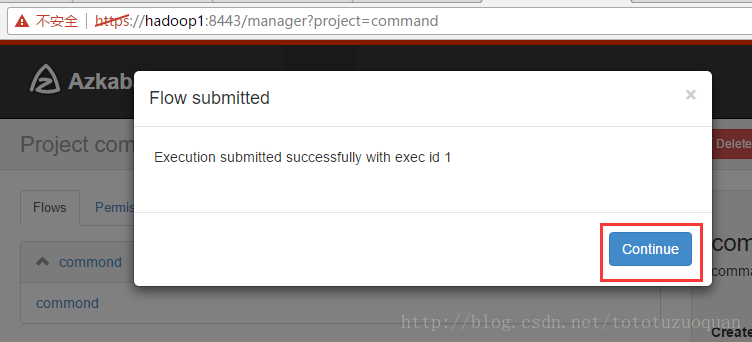
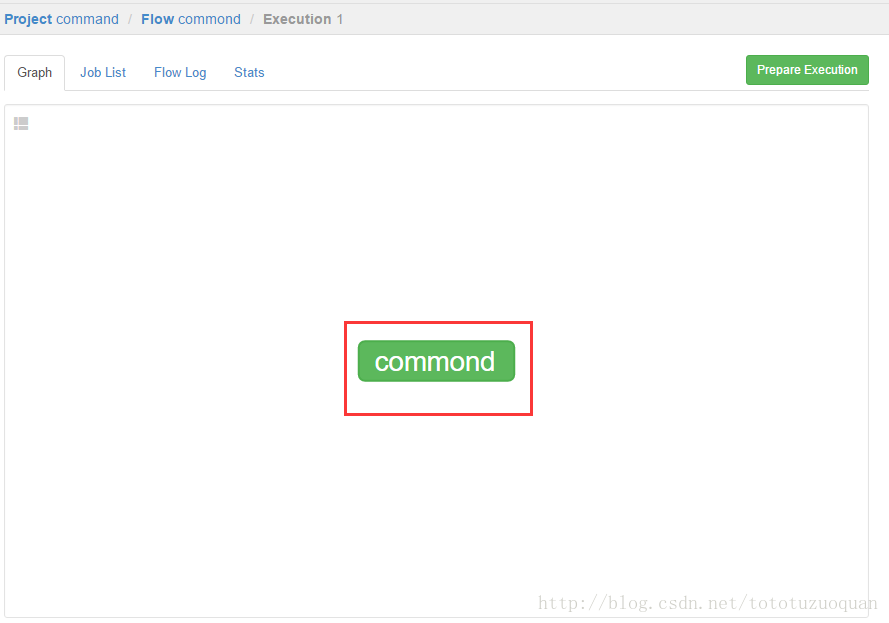
上面的已经变成了绿色了,表示已经执行完成了。
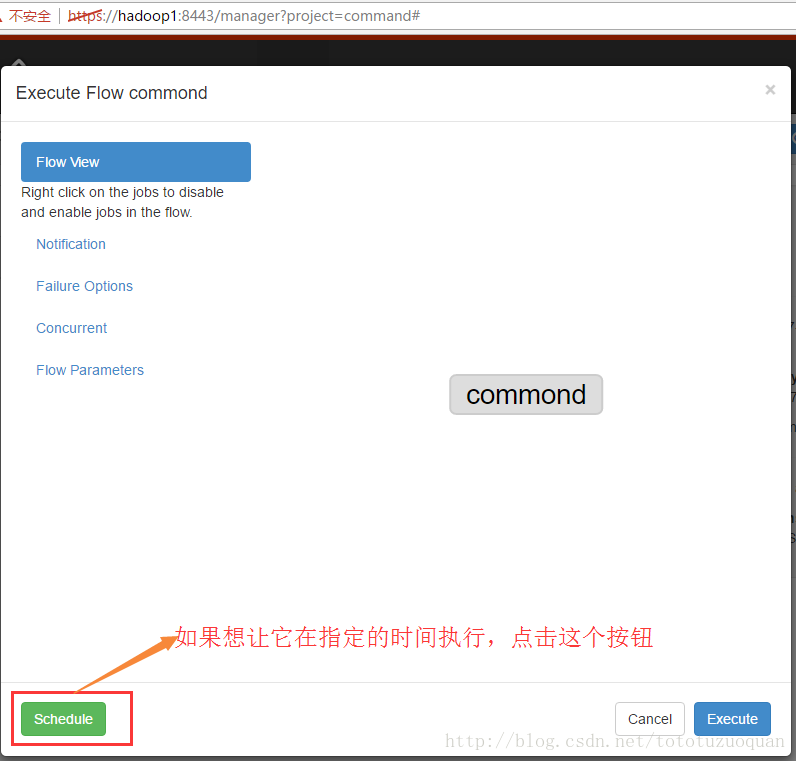
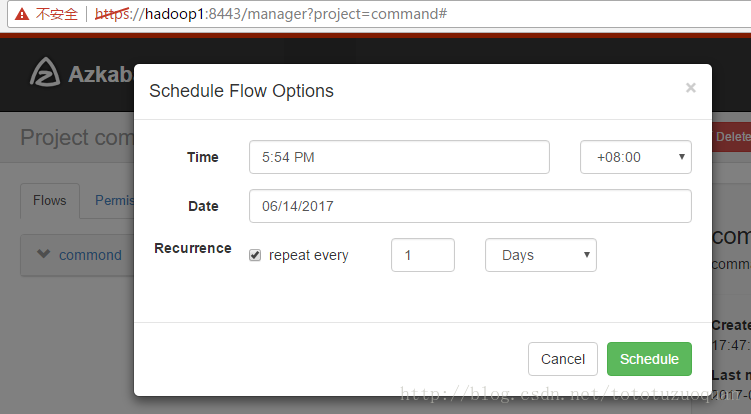
上面的repeat表示每天执行一次
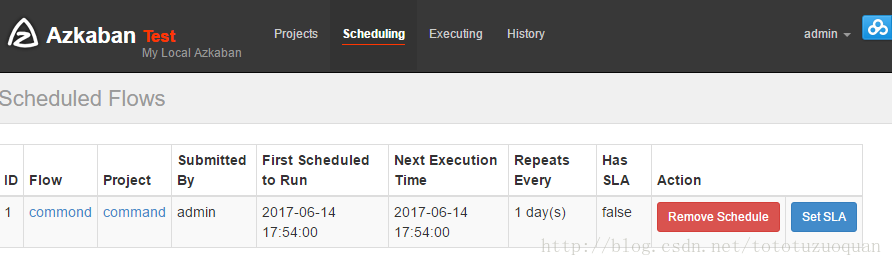
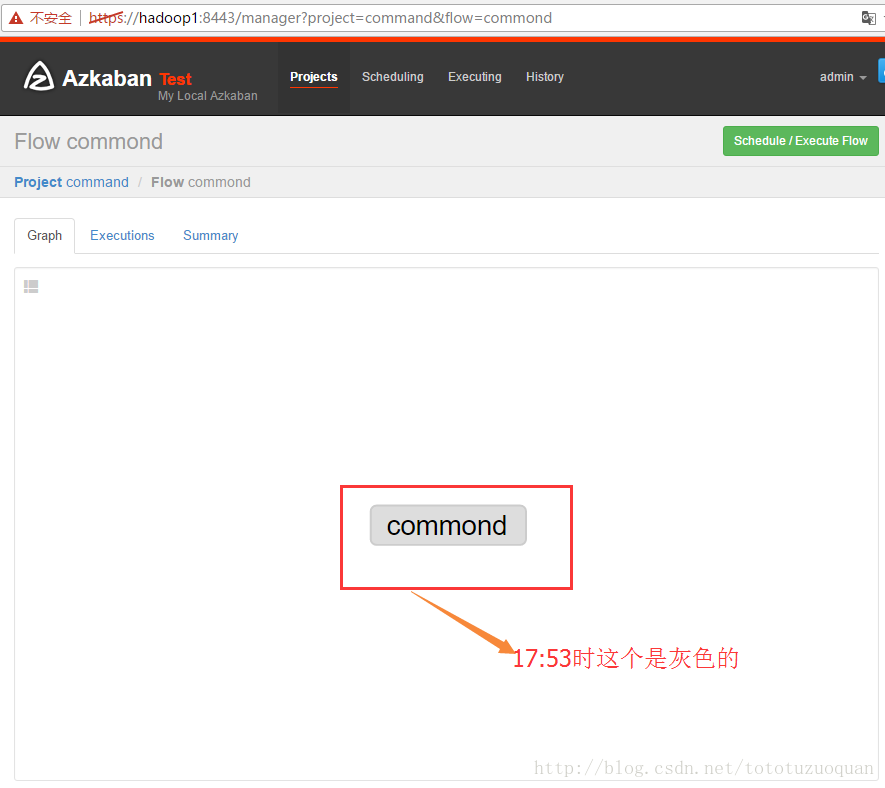
1.2.通过任务执行shell脚本
编写command.job文件
内容如下:
#command.job
type=command
command=sh hello.sh上面的command=sh hello.sh表示的意思是执行hello.sh脚本,其中hello.sh的脚本如下:
#!/bin/bash
echo 'hello' > /home/tuzq/software/azkabandata/hello.txt按照上面的案例,上传上去,并且执行。
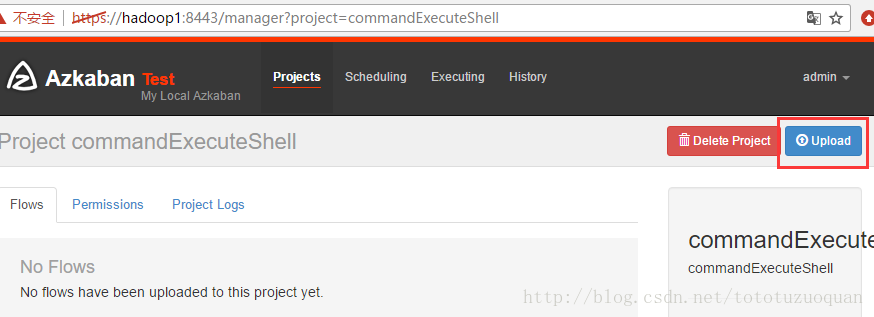
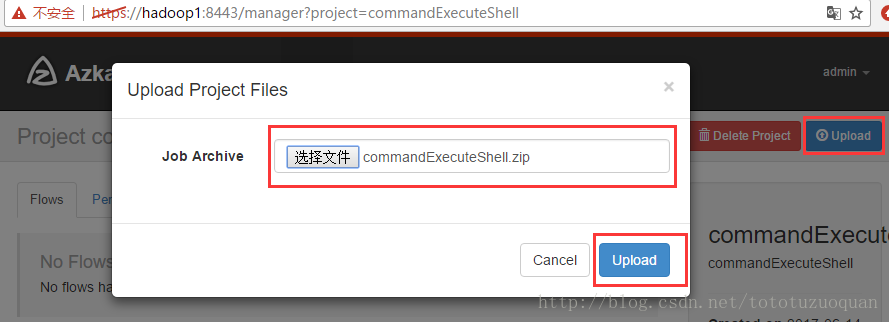
上传任务的脚本
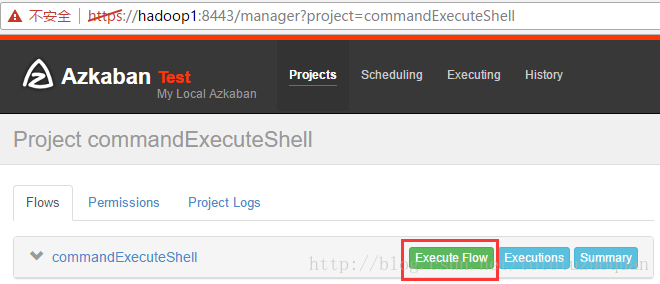
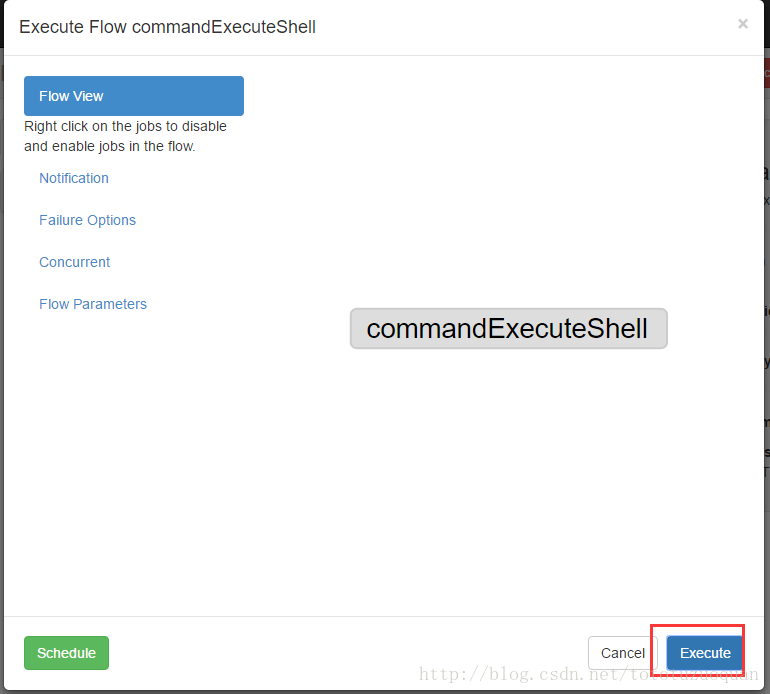
执行工作流:
进入/home/tuzq/software/azkabandata查看是否有文件:
[root@hadoop1 azkabandata]# cd /home/tuzq/software/azkabandata
[root@hadoop1 azkabandata]# ls
hello.txt
[root@hadoop1 azkabandata]# cat hello.txt
hello
[root@hadoop1 azkabandata]#1.3.Command类型多job工作流flow
1、创建有依赖关系的多个job描述
第一个job:foo.job
# foo.job
type=command
command=echo foo第二个job:bar.job依赖foo.job
# bar.job
type=command
#表示这个命令依赖foo这个任务
dependencies=foo
command=echo bar2、将所有job资源文件打到一个zip包中
3、在azkaban的web管理界面创建工程并上传zip包
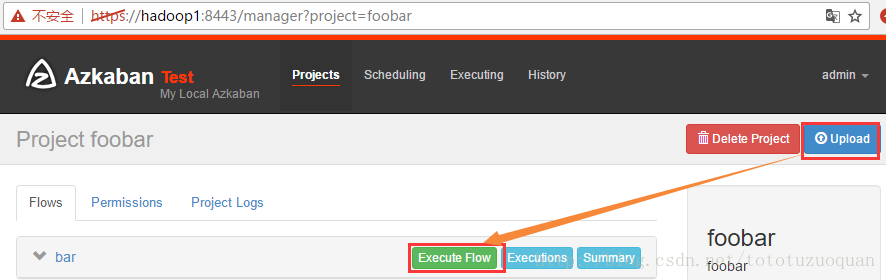
4、启动工作流flow
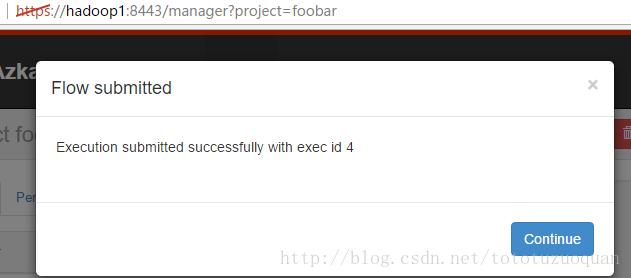
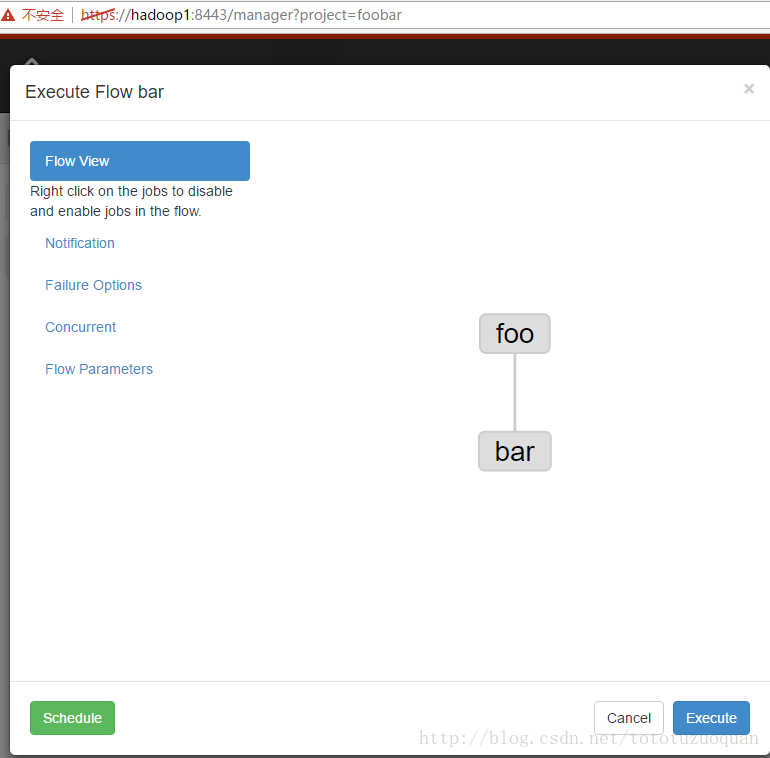


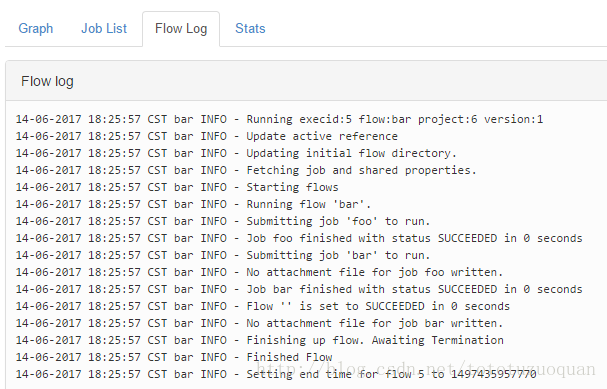
1.4.HDFS操作任务
1、创建job描述文件
# fs.job
type=command
command=/home/tuzq/software/hadoop-2.8.0/bin/hdfs dfs -mkdir /azaz2、将job资源文件打包成zip文件
3、通过azkaban的web管理平台创建project并上传job压缩包
4、启动执行该job
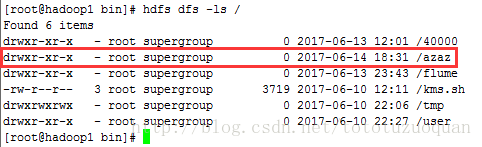
通过上满的结果可以证明,可以通过job来自行hdfs的命令
1.5.MAPREDUCE任务
Mr任务依然可以使用command的job类型来执行
1、创建job描述文件,及mr程序jar包(示例中直接使用hadoop自带的example jar)
# mrwc.job
type=command
command=/home/tuzq/software/hadoop-2.8.0/bin/hadoop jar hadoop-mapreduce-examples-2.8.0.jar wordcount hdfs://hadoop1/wordcount/input hdfs://hadoop1/wordcount/azout2、将所有job资源文件打到一个zip包中
其中hadoop-mapreduce-examples-2.8.0.jar 在$HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.8.0.jar
3、在azkaban的web管理界面创建工程并上传zip包
上传之后的准备工作是:
将wordcount/input上传到hdfs,命令如下:
[root@hadoop1 software]# hdfs dfs -put wordcount /
[root@hadoop1 software]# hdfs dfs -ls /
Found 8 items
drwxr-xr-x - root supergroup 0 2017-06-13 12:01 /40000
drwxr-xr-x - root supergroup 0 2017-06-14 18:31 /azaz
drwxr-xr-x - root supergroup 0 2017-06-13 23:43 /flume
drwxr-xr-x - root supergroup 0 2017-06-14 18:46 /input
-rw-r--r-- 3 root supergroup 3719 2017-06-10 12:11 /kms.sh
drwxrwxrwx - root supergroup 0 2017-06-14 18:43 /tmp
drwxr-xr-x - root supergroup 0 2017-06-10 22:27 /user
drwxr-xr-x - root supergroup 0 2017-06-14 18:47 /wordcount
[root@hadoop1 software]# hdfs dfs -ls hdfs:/wordcount/input
Found 9 items
-rw-r--r-- 3 root supergroup 604 2017-06-14 18:47 hdfs:///wordcount/input/1.txt
-rw-r--r-- 3 root supergroup 604 2017-06-14 18:47 hdfs:///wordcount/input/2.txt
-rw-r--r-- 3 root supergroup 604 2017-06-14 18:47 hdfs:///wordcount/input/3.txt
-rw-r--r-- 3 root supergroup 604 2017-06-14 18:47 hdfs:///wordcount/input/4.txt
-rw-r--r-- 3 root supergroup 604 2017-06-14 18:47 hdfs:///wordcount/input/5.txt
-rw-r--r-- 3 root supergroup 27209520 2017-06-14 18:47 hdfs:///wordcount/input/a.txt
-rw-r--r-- 3 root supergroup 27209520 2017-06-14 18:47 hdfs:///wordcount/input/aaa.txt
-rw-r--r-- 3 root supergroup 27787264 2017-06-14 18:47 hdfs:///wordcount/input/b.txt
-rw-r--r-- 3 root supergroup 26738688 2017-06-14 18:47 hdfs:///wordcount/input/c.txt其中1.txt中内容类似:
4、启动job
现象:
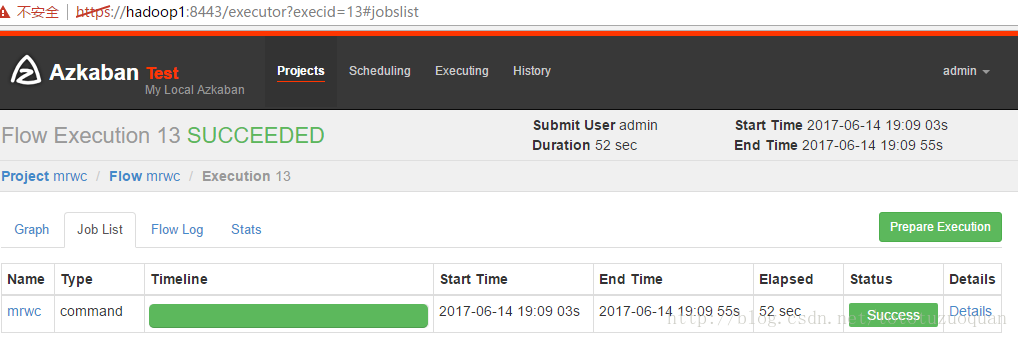
执行完成之后的状态是:
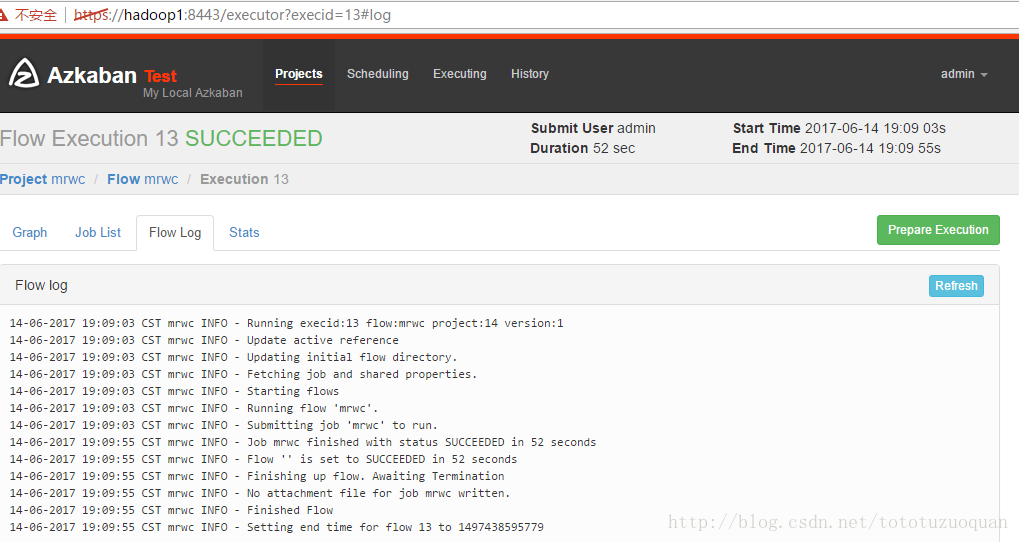

查看hdfs上的内容:
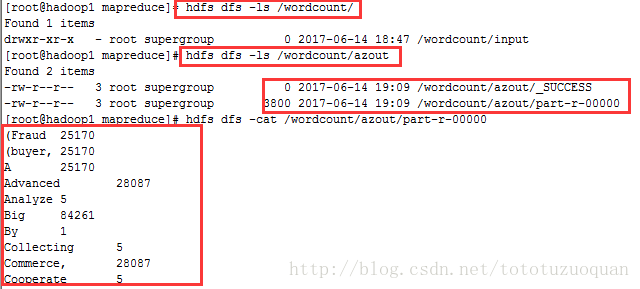
开始的时候发现在/wordcount下只有input这个文件夹,当执行完成之后,发现有了azout这个文件夹。
综上所述,说明通过azkaban在hdfs上生成了文件
1.5.HIVE脚本任务
创建job描述文件和hive脚本
Hive脚本: test.sql
use default;
drop table aztest;
create table aztest(id int,name string) row format delimited fields terminated by ',';
load data inpath '/aztest/hiveinput' into table aztest;
create table azres as select * from aztest;
insert overwrite directory '/aztest/hiveoutput' select count(1) from aztest; Job描述文件:hivef.job
#hivef.job
type=command
command=/home/tuzq/software/hive/apache-hive-1.2.1-bin/bin/hive -f 'test.sql'2、将所有job资源文件打到一个zip包中
3、在azkaban的web管理界面创建工程并上传zip包
4、启动job
准备工作(在hdfs上创建一个hive执行sql后依赖的文件夹):
[root@hadoop1 apache-hive-1.2.1-bin]# hdfs dfs -mkdir -p /aztest/hiveoutput
执行完成之后效果如下:
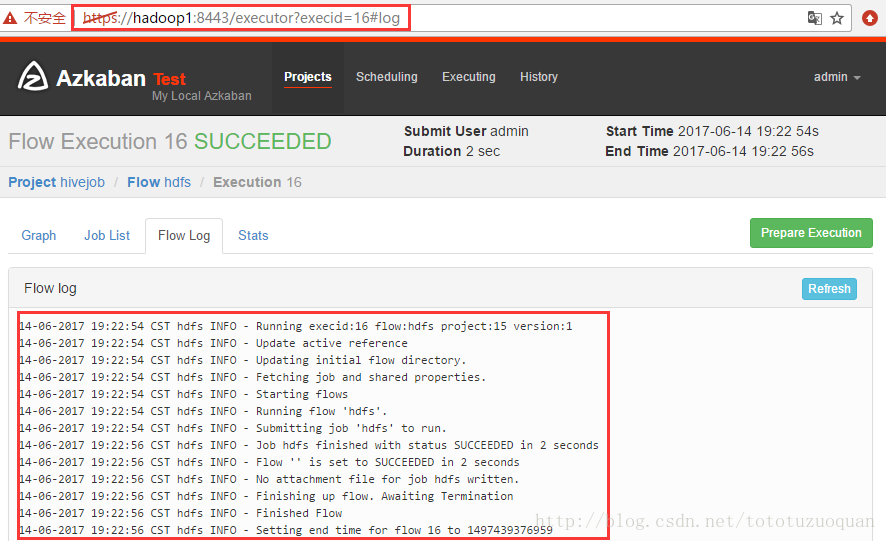
特别注意的是:如果执行错了,可以查看任务的日志输出:
















 2145
2145

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











