







前言
最近受一篇2015年文章《时间序列用户生命周期的聚类方法》的启发,阅读了很多时间序列聚类相关的方法,用消费行为的时间序列尝试去对用户行为进行分群,虽然现阶段的效果不如预期,就当总结希望后续能有所交流~
基于日消费总额的时间序列聚类
为了更好地保留用户消费行为时间序列特征(包含全局特征&局部特征),采用基于时间序列形状的方式以计算序列相似度进行用户行为区分,其中尝试了两个方向:
一、方法说明
1.DTW
DTW即Dynamic Time Warping,是动态时间规整算法,利用DTW的原因是用户在不同时间点上消费行为存在不一致性,为保证存在相似序列的用户能有效地归类

2.KShape
KShape 是一种时间序列聚类算法,由论文《k-Shape: Efficient and Accurate Clustering of Time Series》提出,该算法的核心是迭代增强过程,可以生成同质且较好分离的聚类。该算法采用标准的互相关距离衡量方法,基于此距离衡量方法的特性,提出了一个计算簇心的方法,在每一次迭代中都用它来更新时间序列的聚类分配
二、实验说明
实验利用日消费总额时间序列(如图),基于tslearn工具包(具体用法可见其官方文档:https://tslearn.readthedocs.io/en/stable/)完成聚类实验
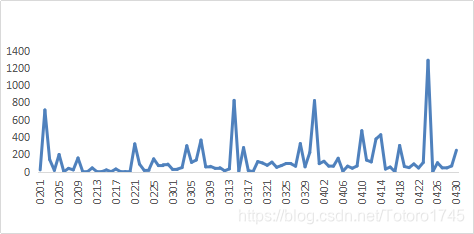
1.输入数据
源数据的格式如下:user, date1, date2, date3, …, daten,可利用tslearn的to_time_series_dataset方法对数据进行处理
import pandas as pd
import numpy as np
from tslearn.utils import to_time_series_dataset
data = pd.read_csv('data.csv')
input_data = to_time_series_dataset 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 692
692











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









