







介绍一下LSTM模型的结构以及源码,用作自己复习的材料。
LSTM模型所对应的源码在:\PyTorch\Lib\site-packages\torch\nn\modules\RNN.py文件中。
上次上一篇文章介绍了RNN序列模型,但是RNN模型存在比较严重的梯度爆炸和梯度消失问题。
本文介绍的LSTM模型解决的RNN的大部分缺陷。
首先展示LSTM的模型框架:
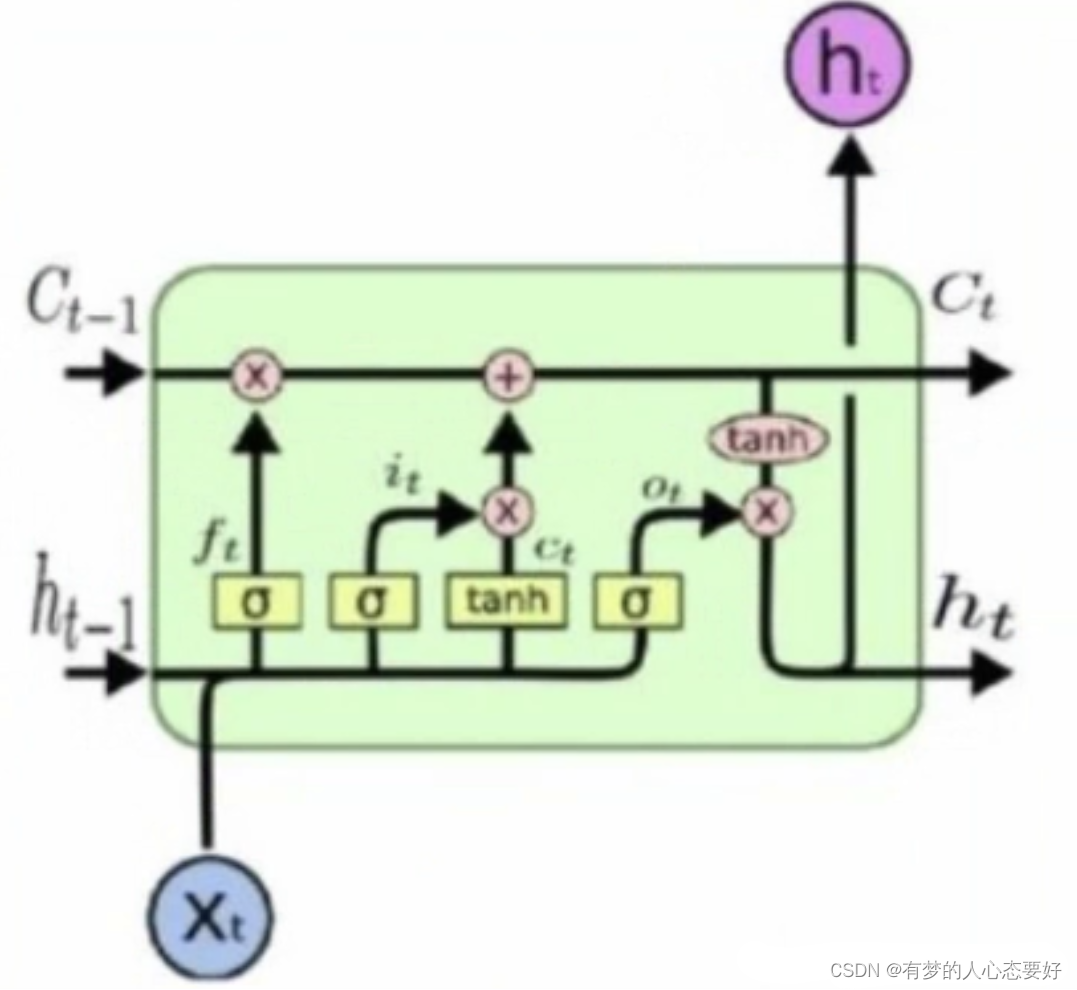
下面是LSTM模型的数学推导公式:
表示
时刻的隐藏状态,
表示
时刻的记忆细胞状态,
表示
时刻的输入,
表示在时间
的隐藏状态或在时间
的初始隐藏状态。
分别是输入门、遗忘门、单元门和输出门。
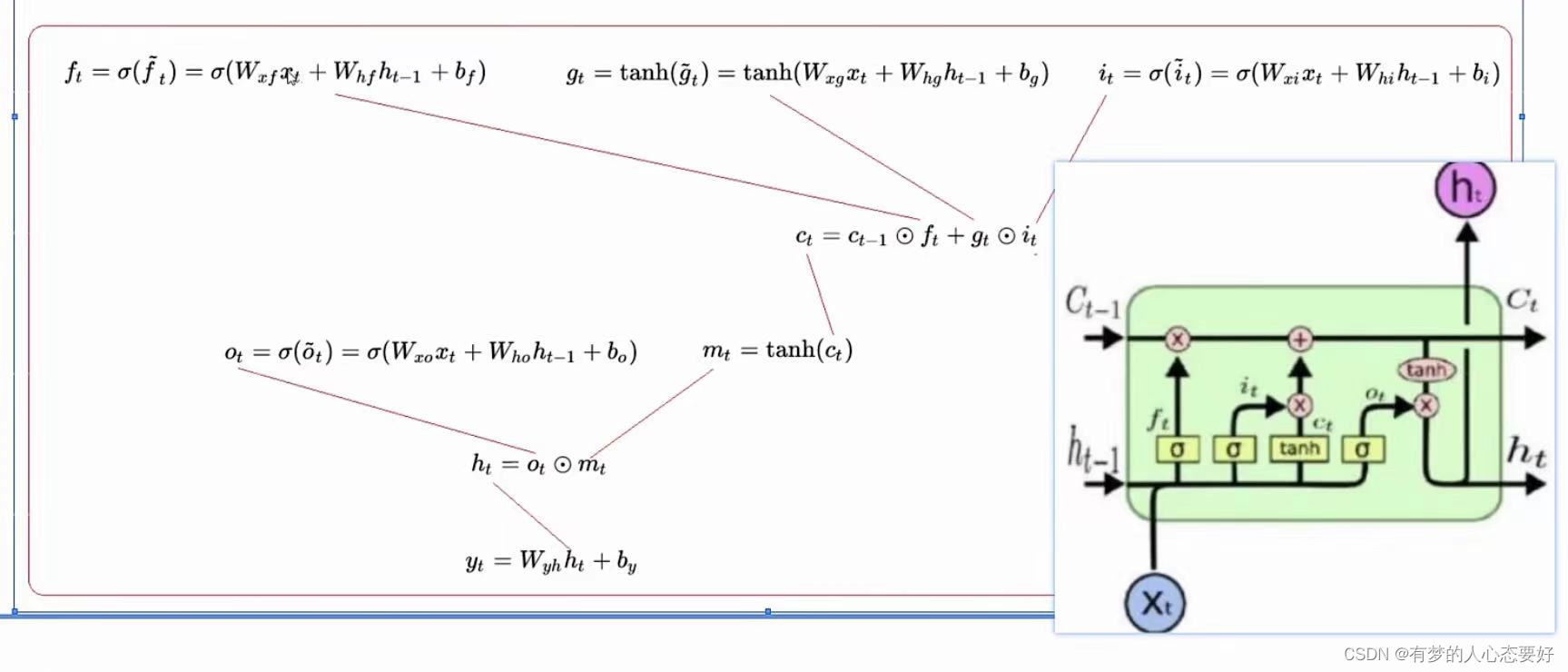
这张图片比较好的介绍了各个门之间的交互关系以及输入输出,大家可以放大看一下。
接下来展示GRU的框架模型:

下面是GRU的数学推导公式:
表示
时刻的隐藏状态,
表示
时刻的输入,
表示在时间
的隐藏状态或在时间
的初始隐藏状态。
分别表示重置门更新门和新建门

上面的图片可以更直观的看到GRU中是如何迭代的。
接下来我们看一下源码中LSTM和GRU类的初始化(只介绍几个重要的参数):
torch.nn.LSTM(self, input_size, hidden_size, num_layers=1,
bias=True, batch_first=False, dropout=0.0,
bidirectional=False, proj_size=0, device=None,
dtype=None)torch.nn.GRU(self, input_size, hidden_size, num_layers=1,
bias=True, batch_first=False, dropout=0.0,
bidirectional=False, device=None, dtype=None)- input_size:输入数据中的特征数(可以理解为嵌入维度 embedding_dim)。
- hidden_size:处于隐藏状态 h 的特征数(可以理解为输出的特征维度)。
- num_layers:代表着RNN的层数,默认是1(层),当该参数大于零时,又称为多层RNN。
- bidirectional:即是否启用双向LSTM(GRU),默认关闭。
LSTM与GRU都是特殊的RNN,因此输入输出可以参考的上一篇介绍RNN的文章,在这里直接进行代码举例。
lstm1 = nn.LSTM(input_size=20,hidden_size=40,num_layers=4,bidirectional=True)
lstm2 = nn.LSTM(input_size=20,hidden_size=40,num_layers=4,bidirectional=False)
gru1 = nn.GRU(input_size=20,hidden_size=25,num_layers=4,bidirectional=True)
gru2 = nn.GRU(input_size=20,hidden_size=25,num_layers=4,bidirectional=False)
tensor1 = torch.randn(5,10,20) # (batch_size * seq_len * emb_dim)
tensor2 = torch.randn(5,10,20) # (batch_size * seq_len * emb_dim)
out_lstm1,(hn, cn) = lstm1(tensor1) # (batch_size * seq_len * (hidden_size * bidirectional))
out_lstm2,(hn, cn) = lstm2(tensor2) # (batch_size * seq_len * (hidden_size * bidirectional))
out_gru1,h_n = gru1(tensor1) # (batch_size * seq_len * (hidden_size * bidirectional))
out_gru2,h_n = gru2(tensor1) # (batch_size * seq_len * (hidden_size * bidirectional))
print(out_lstm1.shape) # torch.Size([5, 10, 80])
print(out_lstm2.shape) # torch.Size([5, 10, 40])
print(out_gru1.shape) # torch.Size([5, 10, 50])
print(out_gru2.shape) # torch.Size([5, 10, 25])维度已经在注释中给大家标注上了!














 1914
1914











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









