







在学习LMAX的disruptor(无锁环形消息队列)时,接触到了CPU-cacheline伪共享的概念.
总结:
当使用颗粒度很小的atomic来代替锁时,由于cpu高速缓存是成块的对内存进行预读,从而在更改atomic时,导致其他核心缓存进行无必要的刷新,降低了性能.(本核心修改的atomic同时存在于其他核心的缓存中,而修改之后值需要在核心间进行同步,来保证原子性)
这里引用查询到的博文:伪共享(False Sharing)
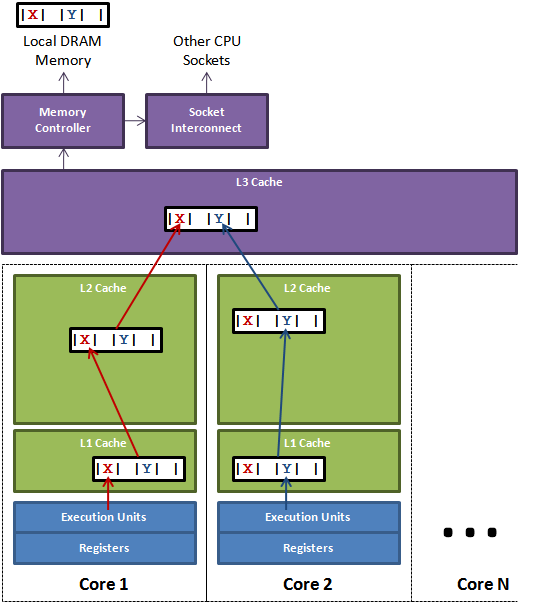
缓存系统中是以缓存行(cache line)为单位存储的。缓存行是2的整数幂个连续字节,一般为32-256个字节。最常见的缓存行大小是64个字节。当多线程修改互相独立的变量时,如果这些变量共享同一个缓存行,就会无意中影响彼此的性能,这就是伪共享。缓存行上的写竞争是运行在SMP系统中并行线程实现可伸缩性最重要的限制因素。有人将伪共享描述成无声的性能杀手,因为从代码中很难看清楚是否会出现伪共享。
为了让可伸缩性与线程数呈线性关系,就必须确保不会有两个线程往同一个变量或缓存行中写。两个线程写同一个变量可以在代码中发现。为了确定互相独立的变量是否共享了同一个缓存行,就需要了解内存布局,或找个工具告诉我们。Intel VTune就是这样一个分析工具。
在清楚问题的基本原因后构建代码进行测试:
#include <atomic>
#include <thread>
#include <iostream>
#include <chrono>
using namespace std;
/// The value of 64 bytes is typical for x86/x64 architectures.
const size_t CacheLineSize = 64 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1735
1735

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









