







 本文主要讨论OCR中的字符分割问题,关键方法包括尺寸归一化、垂直投影和连接组件分析。面对尺寸未知、噪声干扰及字符粘连的情况,文章提到了预处理技术如中值滤波、直方图均衡化和腐蚀膨胀。此外,还引用了文献中的MRF算法和使用同心滑窗处理复杂背景。对于不规律网格的去除,作者表示尚未找到有效方法。
本文主要讨论OCR中的字符分割问题,关键方法包括尺寸归一化、垂直投影和连接组件分析。面对尺寸未知、噪声干扰及字符粘连的情况,文章提到了预处理技术如中值滤波、直方图均衡化和腐蚀膨胀。此外,还引用了文献中的MRF算法和使用同心滑窗处理复杂背景。对于不规律网格的去除,作者表示尚未找到有效方法。
字符分割是OCR中相当重要的环节, 直接关系到最后的识别准确率.
最近一直在做车牌检测, 用颜色与edge定位中一直没有办法避免某些特殊情况的干扰,
且样本来源未知, 没办法去设定一个相对较优的参数. (绝大部分时间用在这了=.=!)
用机器学习? 这方面我还不怎么懂而且也没有好的样本去训练, 准确率肯定还不如老方法.
有点奇怪为什么那些论文对算法本身局限的解决并不谈及
有一种用先验的参数来分割字符的, 比如说先尺寸的归一化,
利用每个字符的宽度间距是固定的这一特性来进行分割.
还有一种是利用垂直投影, 类似下面
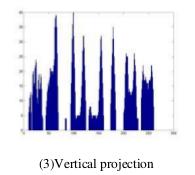
当然还看到有用霍夫变换的, 用于字符倾斜矫正就不提了, 下面这篇文章利用hough变换进行分割
A New Algorithm for Character Segmentation of License Plate
更多的字符分割方法综述可以参看下面几篇文章, 点击可看原文, 多看看说不定会有什么启发</
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2179
2179

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









