






目录
3.在Linux中,系统中的设备文件通常位于/dev目录下。/dev目录是Linux系统中用于表示设备驱动程序的特殊文件的默认位置。
21.python中内置函数Id()返回的是 =====> 内存地址
30.python的猴子补丁(Monkey Patching)
1.F 和 Q查询
F查询:
F对象表示数据库字段的引用,可以用于进行字段间的比较。它允许您在查询中使用一个字段的值来比较另一个字段的值。例如,您可以使用F对象来查询年龄大于身高的人
Q查询:
Q对象用于在查询中构建复杂的逻辑表达式,例如使用AND、OR和NOT操作符组合多个查询条件。您可以将多个Q对象通过逻辑运算符组合在一起,以构建更复杂的查询条件。
2.sqlalchemy简述
SQLAlchemy是一个流行的Python SQL工具包,它提供了强大的SQL数据库连接和对象关系映射 (ORM) 功能。ORM允许您使用Python代码来操作数据库,而无需直接编写SQL语句。
下面是SQLAlchemy的一些主要特点:
-
强大的数据库支持
-
ORM功能
-
灵活的查询语言
-
事务支持
-
高性能
3.在Linux中,系统中的设备文件通常位于/dev目录下。/dev目录是Linux系统中用于表示设备驱动程序的特殊文件的默认位置。
在/dev目录下,您可以找到各种设备文件,包括硬盘、磁盘分区、串口、USB设备、输入设备(例如键盘和鼠标)、网络设备等。每个设备文件在操作系统中都有一个唯一的名称,通常以/dev/作为前缀,并根据设备类型和编号进行命名。
以下是一些常见的设备文件:
/dev/sda- 硬盘驱动器/dev/sda1,/dev/sda2, 等 - 硬盘分区/dev/ttyUSB0,/dev/ttyS0- 串口设备/dev/usb0,/dev/usb1- USB设备/dev/input/event0,/dev/input/mice- 输入设备(键盘、鼠标等)/dev/net/tun- TUN/TAP虚拟网络设备/dev/video0- 视频设备(如摄像头)
4.python中图形用户界面的工具包
-
Tkinter:Tkinter是Python的内置GUI工具包,它基于Tk图形库。它简单易用,适合快速开发简单的界面。Tkinter提供了各种控件和布局管理器,可以创建窗口、标签、按钮、文本框等。
-
PyQt:PyQt是Python的一种绑定库,它封装了Qt图形库,提供了丰富的GUI组件和功能。PyQt具有很高的灵活性和可定制性,可用于构建复杂的GUI应用程序。但请注意,PyQt是一个第三方库,需要单独安装。
-
wxPython:wxPython是一个基于wxWidgets的Python绑定库,它提供了跨平台的GUI开发工具。它具有丰富的控件库和布局管理器,可用于创建漂亮且功能强大的GUI应用程序。
-
PySide:PySide是另一个Python与Qt的绑定库,类似于PyQt。它也提供了许多Qt的功能和控件供您使用。不同之处在于,PySide是Qt官方支持的绑定库,允许在GPL和商业环境中免费使用。
5.-SRE简介
在Python中,SRE(Site Reliability Engineering)是一种实践方法,旨在确保系统的稳定性、可靠性和可扩展性,以提供高质量的用户体验。
Python作为一种高级编程语言,可以在SRE实践中发挥重要的作用。以下是一些与Python相关的SRE实践:
-
自动化和工具开发:Python具有强大的自动化和脚本编程能力,可以用于编写管理和运维工具。SRE团队可以使用Python编写自动化脚本、工具和任务调度器,以简化和加速各种操作和管理任务。
-
监控与报警:Python可以用于开发监控系统和报警工具。借助Python的库和框架,可以编写定制化的监控脚本和报警规则,以实时监控系统的性能、健康状况和故障情况。
-
故障处理与恢复:Python提供了强大的异常处理和错误处理机制。在SRE中,可以使用Python编写异常处理逻辑和故障恢复代码,以快速诊断和解决系统故障,并实现自动化的恢复流程。
-
性能分析与优化:Python提供了丰富的性能分析和调试工具,可以帮助SRE团队发现系统的瓶颈和性能问题。使用Python编写性能测试脚本和分析工具,可以进行系统性能分析和优化。
-
弹性与扩展性:Python的动态特性使其非常适合构建可扩展的系统。通过使用Python编写弹性和可扩展的代码,可以更好地应对负载增长和系统变化
6-weekref简介
在Python中,weakref是一个模块,提供了对弱引用(weak reference)的支持。弱引用是一种特殊的引用类型,不会增加对象的引用计数,也不会阻止对象被垃圾回收器回收。因此,当原始对象不存在其他强引用时,弱引用将自动失效。
7.winapi.py简述
在Python中,winapi.py可能是一个自定义的脚本或模块,提供了与Windows操作系统的API(Application Programming Interface,应用程序编程接口)交互的功能。这个脚本或模块可以包含一些函数和类,用于执行各种Windows系统级别的操作,如文件操作、进程管理、注册表访问等。
可以用来:管理文件和目录、进程管理、窗口和界面、注册表访问
8.uuid的作用和共有多少位
UUID(Universally Unique Identifier,全局唯一标识符)是一种用于标识信息的标准格式。它可以作为唯一标识符在分布式系统中使用,以确保生成的标识符全局唯一;
UUID由32个16进制数字组成,包含5个短横线分隔符。具体的格式为8-4-4-4-12,共计36个字符,每个字符可以是0-9和a-f之间的任意
9.-stract简述
该模块作用是完成Python数值和C语言结构体的Python字符串形式间的转换。
这可以用于处理存储在文件中或从网络连接中存储的二进制数据,以及其他数据源。
10.symtable简介
symtable 是 Python 标准库中的一个模块,可用于分析 Python 代码中的符号表信息。它提供了一种方法来检索和分析 Python 程序的符号(变量、函数、类等)的命名和作用域信息。
通过使用 symtable,您可以访问和检索 Python 代码中的符号表信息,包括:
- 在全局作用域中定义的变量、函数和类
- 在函数和类的局部作用域中定义的变量、函数和类
- 嵌套作用域中的变量
使用 symtable 模块,您可以:
- 构建符号表对象
- 获取符号表对象的属性,如名称、类型、作用域等
- 遍历符号表中的符号及其属性
import symtable
code = """
x = 10
def foo():
y = 20
def bar():
z = 30
bar()
foo()
"""
st = symtable.symtable(code, "<string>", "exec")
symbols = st.get_symbols()
for symbol in symbols:
print(symbol.get_name(), symbol.get_namespace(), symbol.get_type())11.-sqlite简介
sqlite 是一个嵌入式关系型数据库,它以轻量级、零配置和自包含为特点。它是使用 C 语言实现的,被设计为在客户端和服务器之间无需额外设置或配置的情况下,直接访问数据库文件。
以下是一些关于 SQLite 的主要特点和优势:轻量级、无服务器、无配置、支持标准 SQL、跨平台、事务支持、广泛使用等
12.multiprocessing简介
multiprocessing 是 Python 标准库中的一个模块,用于实现多进程并行计算。它提供了一种在 Python 中利用多个进程执行任务的方式,可以充分利用多核处理器的性能。
以下是 multiprocessing 的一些特点和功能:多进程并行计算、进程间通信、进程池、并行任务的调度和结果获取
from multiprocessing import Pool
def square(x):
return x**2
if __name__ == '__main__':
with Pool(processes=4) as pool:
numbers = [1, 2, 3, 4, 5]
results = pool.map(square, numbers)
print(results)
# [1, 4, 9, 16, 25]13.-signal简介
signal 是 Python 标准库中的一个模块,用于管理和处理进程间通信中的信号(Signals)。信号是操作系统用于通知进程发生某些事件的机制,例如按下 Ctrl+C、收到特定信号时等。
以下是一些 signal 模块的主要功能和特点:信号处理、内置信号、信号忽略和重定向、跨平台
14.-MIPS在计算机中的作用
-
指令集架构(ISA): MIPS 是一种常见的指令集架构之一,它定义了计算机体系结构中的指令集和相关的规范。作为一种精简指令集计算机(RISC)架构,MIPS 提供了明确、简单和高效的指令集,为计算机硬件和软件的开发提供了统一的基础。
-
嵌入式系统: MIPS 处理器在嵌入式系统领域广泛应用,如智能手机、路由器、物联网设备、数字电视等。MIPS 的低功耗、高性能和精简指令集的特点使其成为嵌入式应用的理想选择。
-
教育和研究: MIPS 架构作为一种经典的 RISC 架构,常被用于教育和研究领域。学习 MIPS 架构可以帮助人们理解计算机体系结构的基本概念和设计原理,深入研究计算机硬件和编程技术。
-
编译器和优化器开发: MIPS 架构的广泛应用促使编译器和优化器开发人员专注于为 MIPS 架构优化代码生成和性能提升。通过针对 MIPS 架构进行优化,可以使编译器生成更高效的机器码,提高程序的执行效率。
-
处理器和系统设计: MIPS 架构指导和促进了处理器和系统设计的发展。许多处理器芯片制造商和系统设计者使用 MIPS 架构作为设计的基础,以实现高性能、高效能耗比的处理器和系统。
15.IDIE在什么地方用,干什么的
IDLE 是 Python 自带的一个简单的集成开发环境(IDE),用于编写、运行和调试 Python 代码。它是 Python 安装包的一部分,并且可以在大多数 Python 安装中找到和使用。
IDLE 主要用于以下几个方面:Python 代码编辑和运行、交互式 Python Shell、调试器、文档和帮助资源
16.__pycaehe__简介:
__pycache__ 是 Python 解释器自动生成的一个目录,用于存储编译后的字节码文件(.pyc 文件)。这个目录通常会在与源代码文件相同的目录下生成。
这个目录对于 Python 解释器来说是透明的,一般情况下不需要手动操作它。它的存在主要是为了提高运行效率和避免重复编译。
17.uuid3简介:
uuid3 是 Python 标准库中 uuid 模块提供的一个函数,用于生成基于命名空间和名称的 UUID(通用唯一标识符)。
UUID 是一种用于在分布式系统中唯一标识对象的标准化方法。它是由一个固定长度的字符串组成,通常表示为 32 个十六进制数字,以连字符分隔成五组,形式如:xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx。UUID 是在全球范围内都具有唯一性的,因此可以用于标识各种对象或数据,如数据库记录、文件、网络通信等。
18.虚拟机中链接别人虚拟机
1在未开机中设置网络为
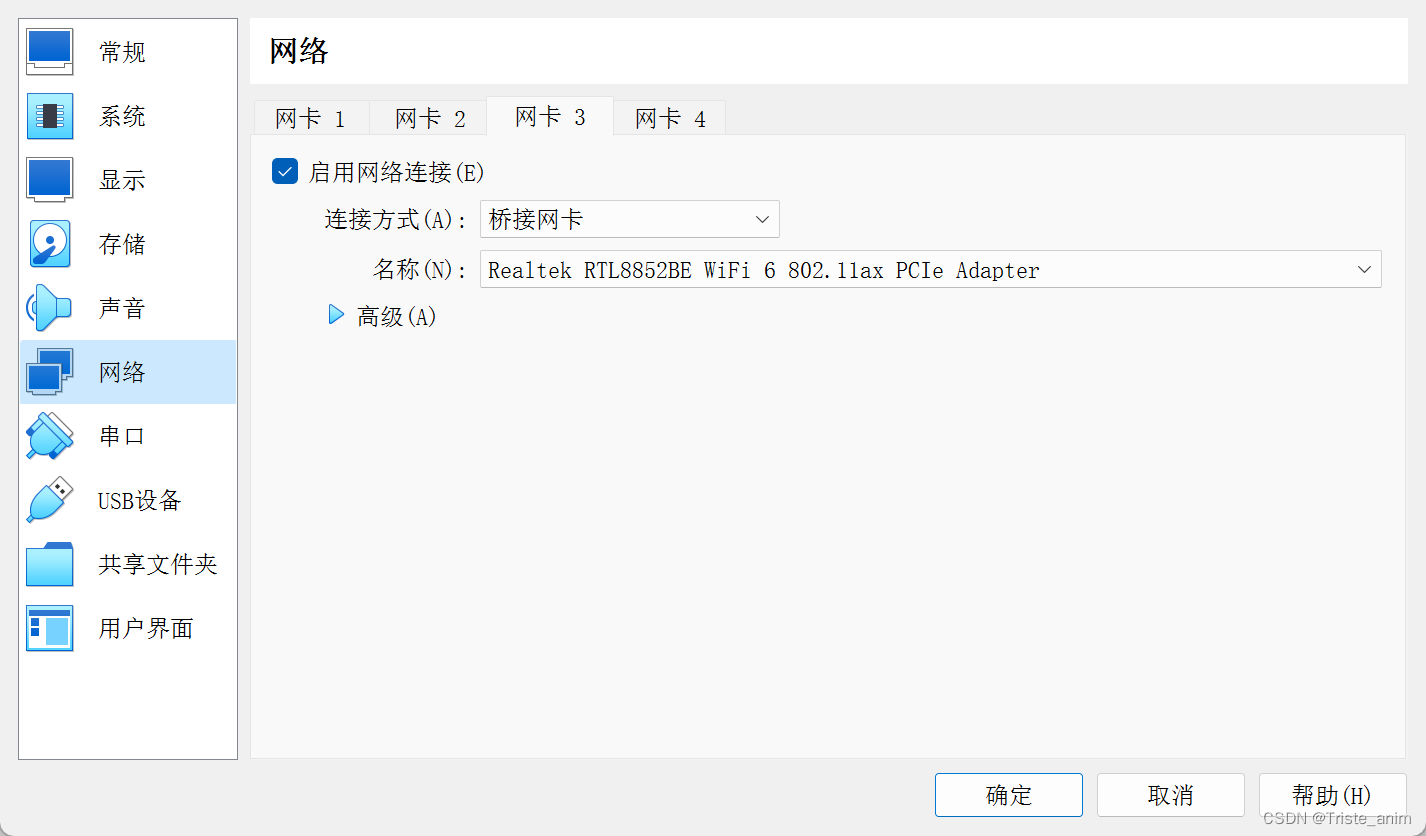
2.启动虚拟机输入IP a找到自己的网址ip地址
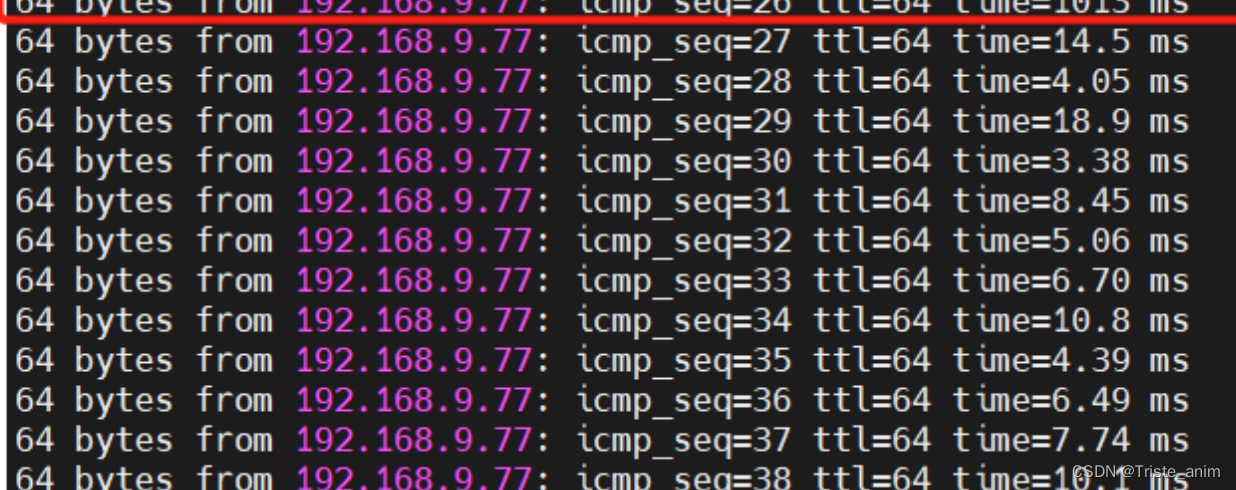
3.ping 加ip地址即可链接别人地址
4.当出现以下则证明链接成功
19.axure rp
Axure RP是美国Axure Software Solution公司旗舰产品,是一个专业的快速原型设计工具,让负责定义需求和规格、设计功能和界面的专家能够快速创建应用软件或Web网站的线框图、流程图、原型和规格说明文档。 作为专业的原型设计工具,它能快速、高效的创建原型,同时支持多人协作设计和版本控制管理
20.项目立项
1.项目经理接到项目后出接口文档后告诉每个部门的工作
2.前端要建起前端页面、设计图片、页面动态交互
3.后端:制作核心业务流程图、数据库设置、后端开发、编码、后端开发
4.测试:测试项目的是否可以运行
5.运维工程师:测试成功后交给运维看守项目运行
21.python中内置函数Id()返回的是 =====> 内存地址
22.什么是内存地址
内存地址是计算机中用来唯一标识和访问存储单元 (内存单元)的位置。每个存储单元都有一个唯一的地址,用于在计算机系统中进行数据的读取和写入操作。可以将内存地址理解为内存中某个特定数据的住所。
23.鸭子函数
鸭子类型:是一种动态类型的风格。一个对象有效的语义,不是由继承自特定的类或实现特定的接口,而是由当前方法和属性的集合决定。
class F1:
pass
# 假设,S1是我们的正统类,它继承于根正苗红的F1,是我们的正统类
class S1(F1):
def show(self):
print('S1.show')
# S2是路人甲,是个歪瓜裂枣,但是他自己也有一个叫show的方法。
class S2:
def show(self):
print('S2.show')
# 在Java或C#中定义函数参数时,必须指定参数的类型,也即是说,我们如果用
# Java写下面的Func,需要告知,obj是F1类还是其他什么东西。
# 如果限定了F1,那么S2是不可以被采纳的。
# 然而,在Python中,一切都是Obj,它不care你到底是什么类,直接塞进去就可以
def Func(obj):
"""Func函数需要接收一个F1类型或者F1子类的类型"""
obj.show()
s1_obj = S1()
Func(s1_obj) # 在Func函数中传入S1类的对象 s1_obj,执行 S1 的show方法,结果:S1.show
s2_obj = S2()
Func(s2_obj) # 在Func函数中传入Ss类的对象 ss_obj,执行 Ss 的show方法,结果:S2.show24.exists如何使用
在Python中,可以使用os.path.exists()函数来检查指定路径是否存在。该函数接受一个路径作为参数,并返回一个布尔值,表示该路径是否存在。
import os
path = 'path/to/file.txt'
if os.path.exists(path):
print(f'路径 "{path}" 存在')
else:
print(f'路径 "{path}" 不存在')25.文件操作函数练习包括 truncate()
truncate() 是Python文件对象的一个方法,用于截断文件内容。它可以用来删除或缩短文件中的数据。
truncate() 方法有一个可选参数 size,表示截断后文件的大小。如果省略 size 参数,或者不提供参数,则默认会将文件截断为空
# 打开文件以读写模式
file = open("filename.txt", "r+")
# 读取文件内容
content = file.read()
print("原始内容:")
print(content)
# 截断文件内容到10个字节
file.truncate(10)
# 将文件指针移至文件开头
file.seek(0)
# 读取截断后的文件内容
truncated_content = file.read()
print("截断后的内容:")
print(truncated_content)
# 关闭文件
file.close()26.type实现原理
type 函数是Python中一个内置函数,用于返回对象的类型。下面是简要说明 type 函数的实现原理:
在Python中,每个对象都有一个特殊的属性 __class__,它存储了对象所属类的引用。type 函数基于这个属性来确定对象的类型。
27.面向对象的三大要素
-
封装(Encapsulation):封装是指将相关的数据和方法组合成一个单独的实体,将数据和对数据的操作封装在一起,隐藏了数据的具体实现细节,对外部提供了访问和操作数据的接口。通过封装可以实现数据的安全性和保护,同时也能够简化操作,提高代码的可维护性和重用性。
-
继承(Inheritance):继承是指一个类可以派生出子类,子类可以继承父类的属性和方法,并可以在此基础上进行扩展或修改。通过继承机制,可以建立类之间的层次结构,从而实现代码的重用和扩展。子类可以继承父类的特性,包括属性、方法、甚至是其他类的关系。
-
多态(Polymorphism):多态是指同一种操作或函数可以应用于不同类型的对象,产生不同的结果。多态允许针对不同类型的对象调用相同的方法名,但具体的实现会根据对象的类型而有所不同。通过多态,可以实现更灵活的程序设计,增加代码的可扩展性和可维护性。多态可以通过继承和接口实现。
28.python中mro理解
在Python中,MRO(Method Resolution Order)是一个用于确定类继承关系中方法解析顺序的算法。MRO 确保在多继承情况下,每个方法按正确的顺序被调用。
在 Python 3 中,类的 MRO 是通过 C3 线性化算法来确定的。MRO 算法通过遵循以下三个原则来确定方法解析顺序:
- 类的线性化顺序必须保持所有父类的前后顺序:如果某个类 A 继承自类 B 和类 C,那么线性化顺序中必须先出现 B,然后才是 C。
- 子类的线性化顺序必须在父类之前:子类的线性化顺序中必须先出现子类本身,然后才是父类。
- 如果一个类有多个父类,并且这些父类都满足上述两个原则,那么按照从左到右的顺序来处理
class A:
def test(self):
print("A")
class B(A):
def test(self):
super().test()
print("B")
class C(A):
def test(self):
super().test()
print("C")
class D(B, C):
def test(self):
super().test()
print("D")
d = D()
d.test()29.python中PostgreSQL
我认为您指的是 PostgreSQL,它是一种功能强大的开源关系型数据库管理系统(DBMS)。PostgreSQL 支持高度灵活的数据模型,具有可扩展性、安全性和稳定性。
-
关系型数据库:PostgreSQL 是关系型数据库,使用 SQL(Structured Query Language)查询语言来操作和管理数据。
-
ACID 事务支持:PostgreSQL 支持 ACID(原子性、一致性、隔离性、持久性)事务,确保数据库操作的原子性以及数据的一致性和持久性。
-
高级扩展性:PostgreSQL 具有丰富的扩展功能,包括存储过程、触发器、用户自定义函数、复杂查询等,可以根据需要扩展和定制数据库的功能。
-
多版本并发控制(MVCC):PostgreSQL 使用 MVCC 技术,可以支持高并发操作,提供并发事务的隔离性和数据一致性。
-
JSON 和 JSONB 数据类型支持:PostgreSQL 支持存储和查询 JSON(JavaScript Object Notation)数据类型,同时还提供了 JSONB 数据类型,以支持更高效的查询和索引。
-
外部数据访问:PostgreSQL 允许通过外部表和外部数据包装器(如 FDW)访问和操作来自其他数据源的数据,包括其他数据库、文件系统等。
-
安全性和认证机制:PostgreSQL 提供了强大的安全性功能,包括基于角色的访问控制(RBAC)、SSL/TLS 加密、密码验证、数据加密等。
-
多语言支持:PostgreSQL 支持多种编程语言的驱动程序和扩展,包括 Python、Java、C/C++、PHP 等。
30.python的猴子补丁(Monkey Patching)
Python是一种典型的动态脚本语言。它不仅具有 动态类型(dynamic type) ,而且它的 对象模型(object model) 也是动态的。Python的类是可变的(mutable),方法(methods)只是类的属性(attributes);这允许我们在 运行时(run time) 修改其行为。这被称为猴子补丁(Monkey Patching), 它指的是偷偷地更改代码。
Monkey Patching只是在 运行时(run time) 动态替换属性(attributes)。 而在Python中,术语monkey patch指的是对函数(function)、类(class)或模块(module)的动态(或运行时)修改。














 8344
8344











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









