







- 数十年以来,统计机器翻译(Statistical Machine Translation)在翻译模型中占统治地位,直到出现神经机器翻译(Neural Machine Translate,NMT)。NMT是一种新兴机器翻译方法,意图构建和训练一种大型神经网络,输入原语言文本(source),输出目标翻译文本(target)。
- NMT最初是由Kalchbrenner and Blunsom(2013), Sutskever et. al (2014) and Cho. et. al (2014b)提出,其中大家最熟悉的框架就是Sutskever的sequence-to-sequence(seq2seq)网络结构。这篇博客也是基于seq2seq经典框架进行剖析以及怎么实现注意力机制的。
PART 1:综述

Fig. 0.1: seq2seq with an input sequence of length 4
在seq2seq中,其思想就是构造两个循环神经网络(RNNs),就是编码器和解码器。
-
encoder:处理输入序列,把信息压缩成一个有固定维度的context vector(也成为sentence embedding或者“thought” vector)。这个向量代表了整个源句子输入的语义表示。
-
decoder:由编码器输出的context vector初始化,‘********,在早期的工作中,使用了编码器网络的最后一个隐状态作为解码器的初始隐状态。

Fig. 3. The encoder-decoder model, translating the sentence “she is eating a green apple” to Chinese. The visualization of both encoder and decoder is unrolled in time.
很清楚,这种定长的context vector设计有个很致命的问题,无法记忆长句子。当处理完所有输入序列后,模型对最初的输入单词已经**“忘得差不多了”**。也就是编码器输出的context vector并不能很好地表征长句子的开头部分信息。所以注意力机制就是为了解决这个问题提出的。
最初提出注意力机制就是为了解决神经机器翻译任务中长的源句子的记忆问题。注意力机制的做法并不要创建一个与编码器最后一个隐状态(last hidden state)完全无关的context vector,而是要创建一个与编码器所有的隐状态有关的 加权 context vector,当然也包括 最后一个隐状态(这就是所谓global attention)。
现在context vector 能遍历整个输入序列,所以我们不用担心遗忘的问题。接下来就要学习源语言和目标语言之间的对齐,这种对齐由context vector控制。
对齐(alignment)
对齐就是把原始文本的单词(也可能是一段)和翻译所对应的单词相匹配,如图所示。
Fig. 0.3: Alignment for the French word ‘la’ is distributed across the input sequence but mainly on these 4 words: ‘the’, ‘European’, ‘Economic’ and ‘Area’. Darker purple indicates better attention scores (Image source)

下面重点讲解加入注意力机制的context vector到底由什么组成,主要分下面三个部分:
- 编码器的隐状态
- 解码器的隐状态
- source和target之间的对齐

Fig. 4. The encoder-decoder model with additive attention mechanism in Bahdanau et al., 2015.
PART 2:图解注意力
第一步:准备隐状态
首先准备好所有的编码器隐状态(绿色)和解码器的第一个隐状态(红色)。在这个例子中,我们有4个编码器隐状态和当前解码器隐状态。(注意:编码器的最后一个隐状态是解码器第一个时刻的输入。解码器第一个时刻的输出我们称之为解码器第一个隐状态)

Fig. 1.0: Getting ready to pay attention
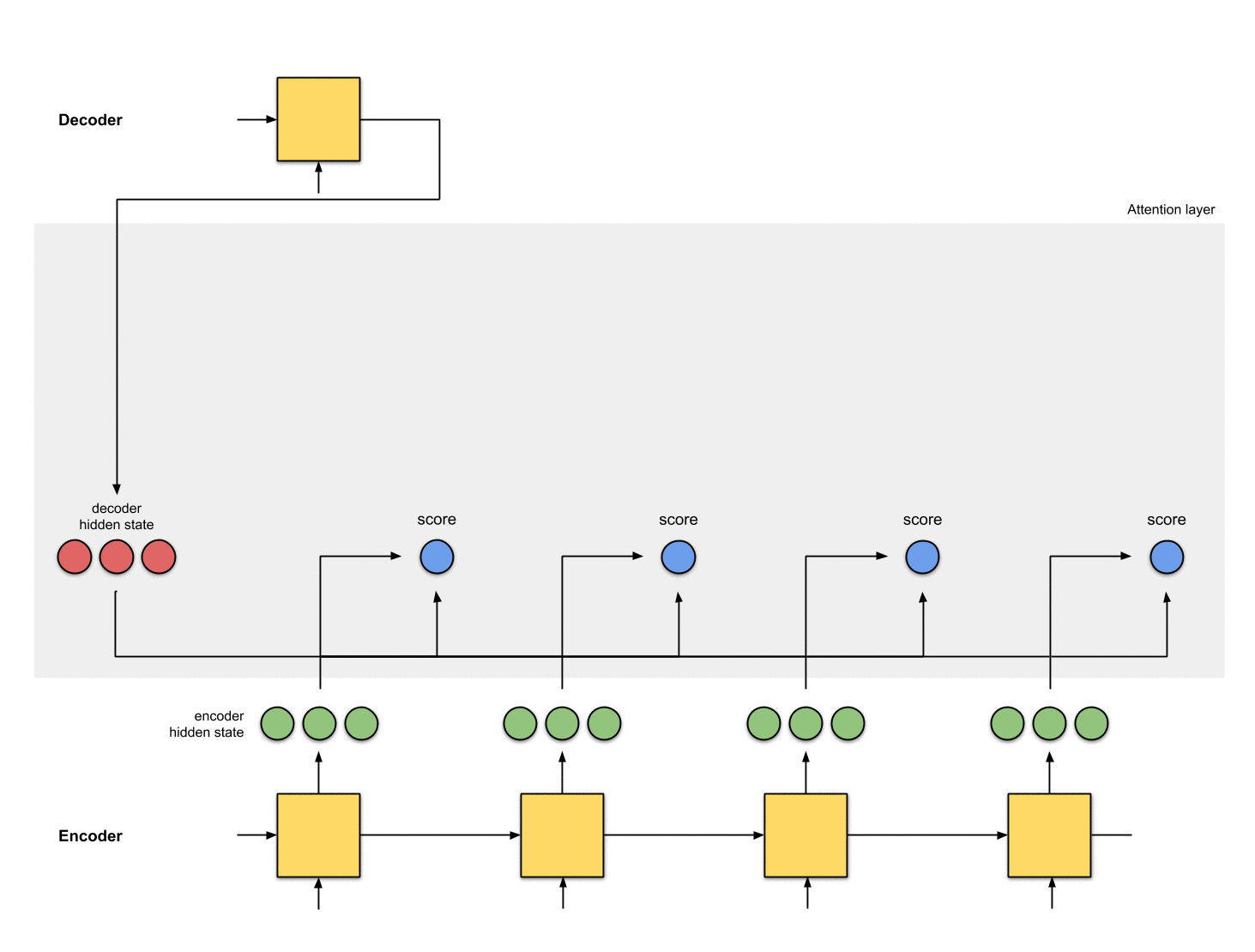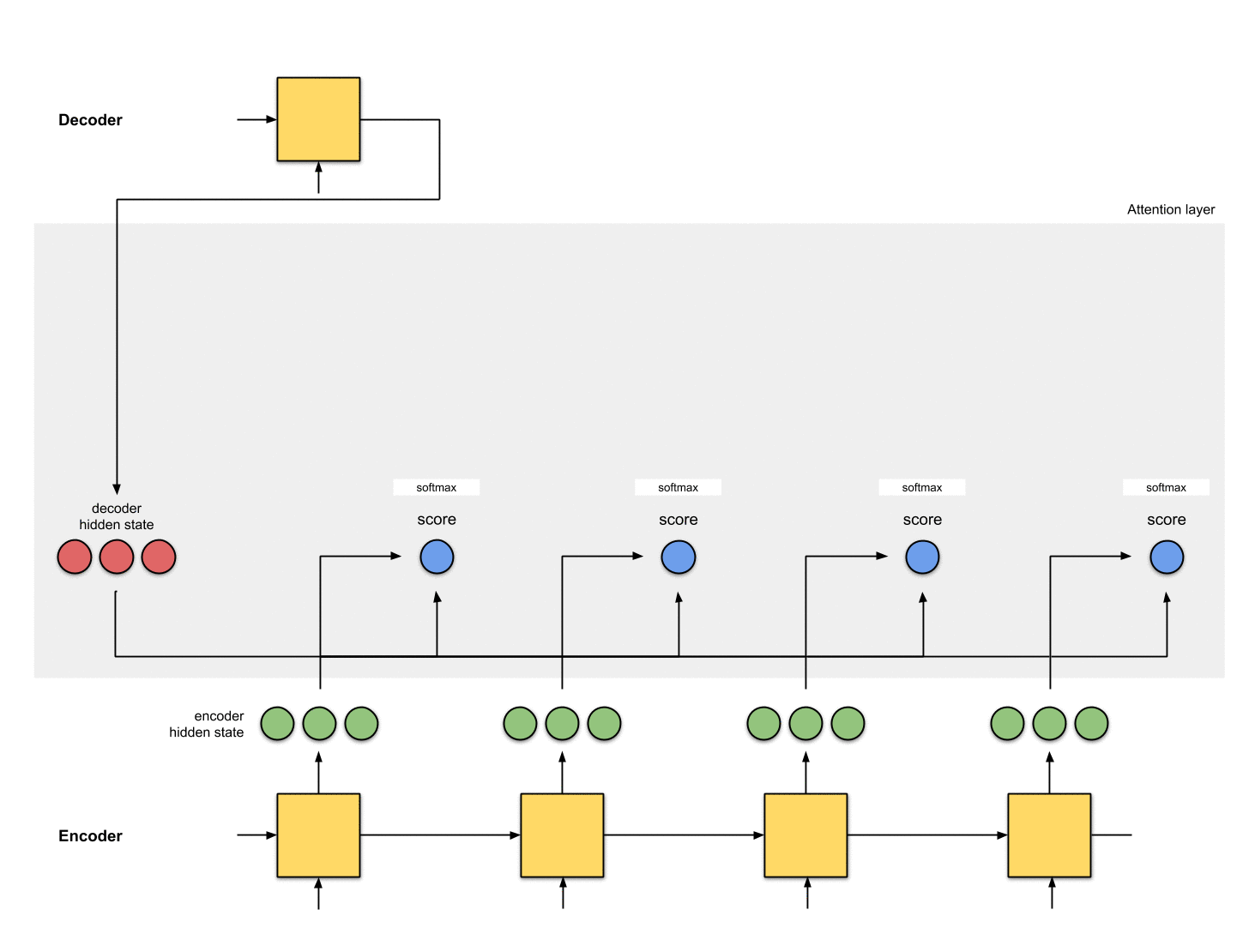
第二步:为每个编码器隐状态打分
分数(是标量)由score function(也称之为alignment或者score function)计算得来。在这个例子中,score function是解码器和编码器隐状态之间的点积。详情见附录A
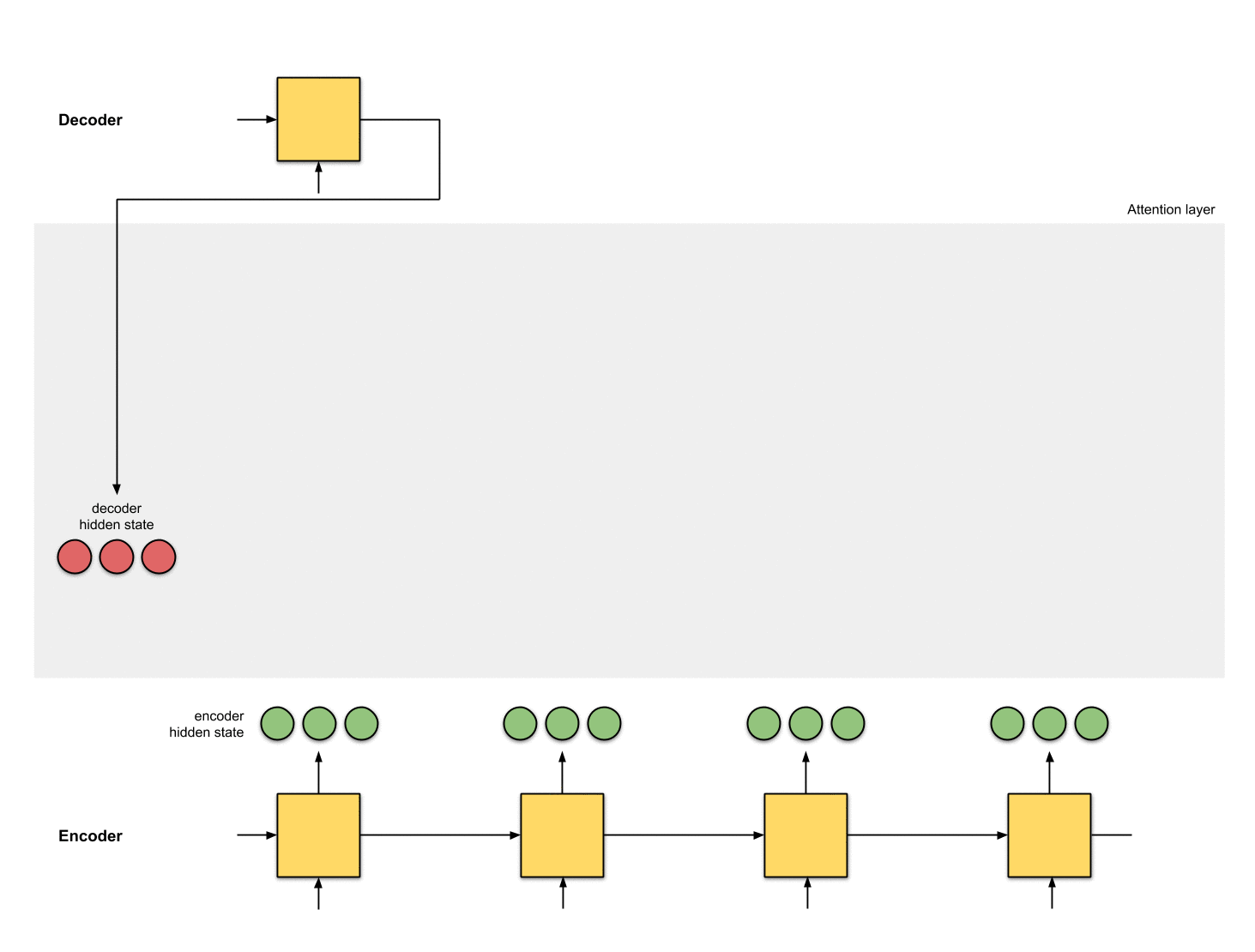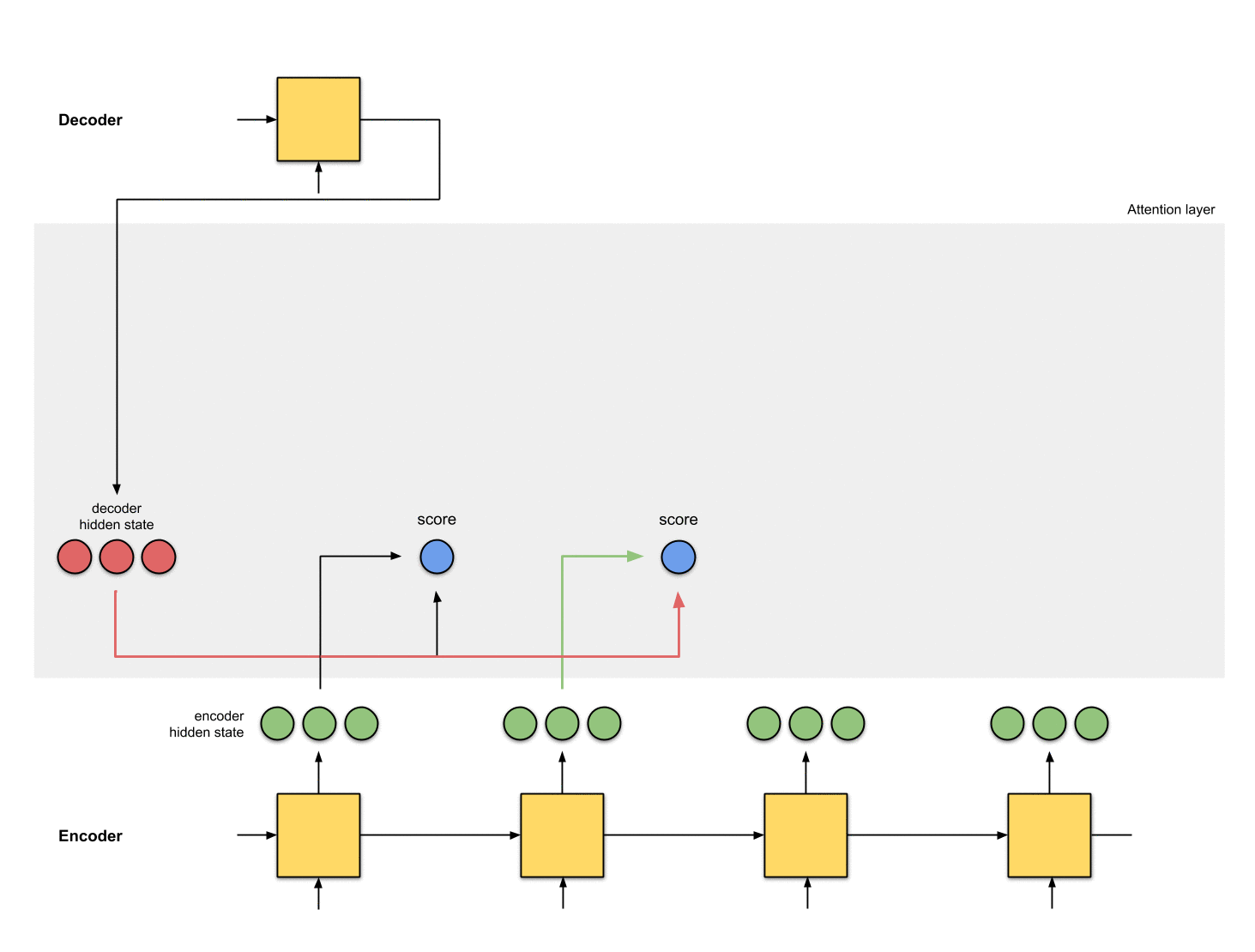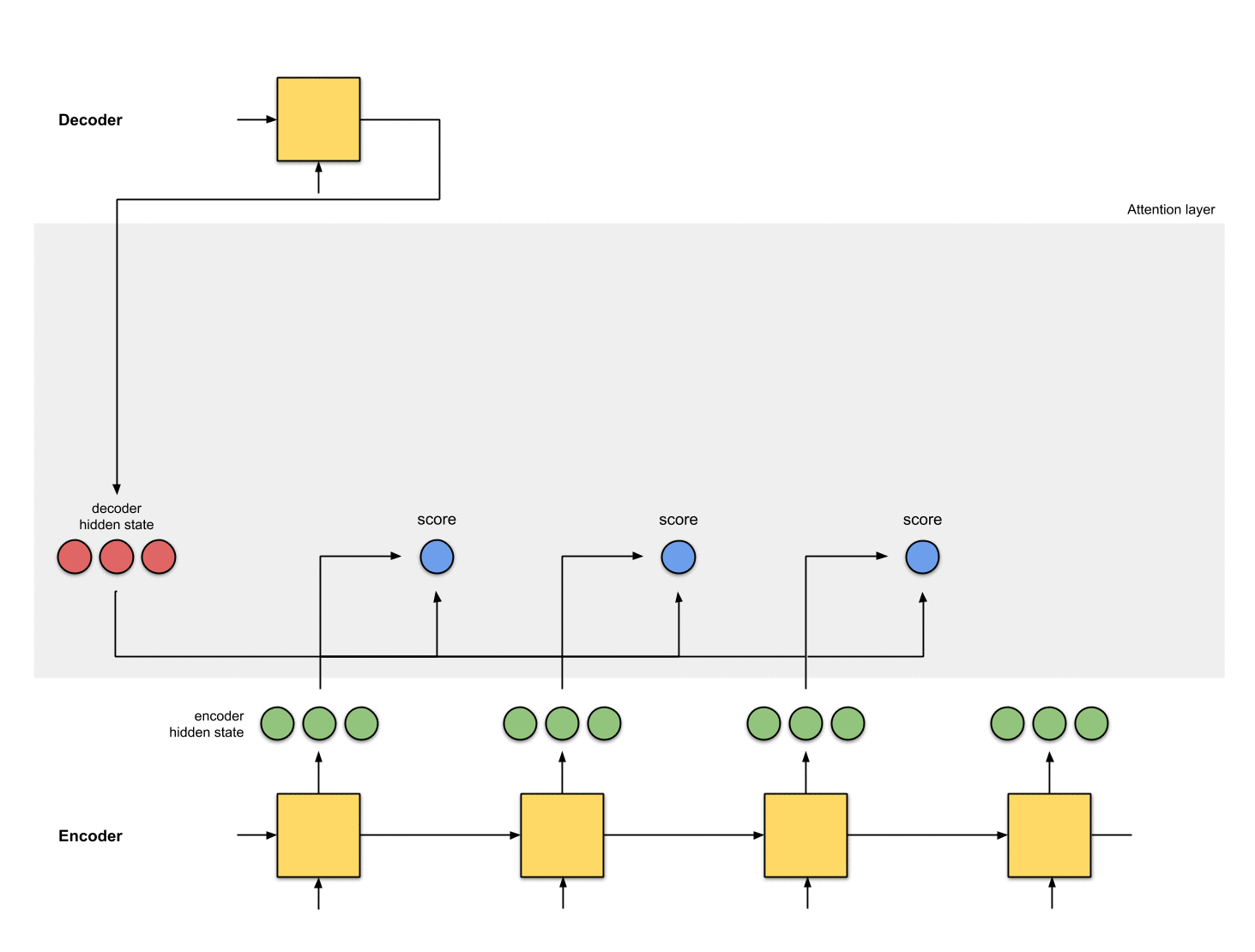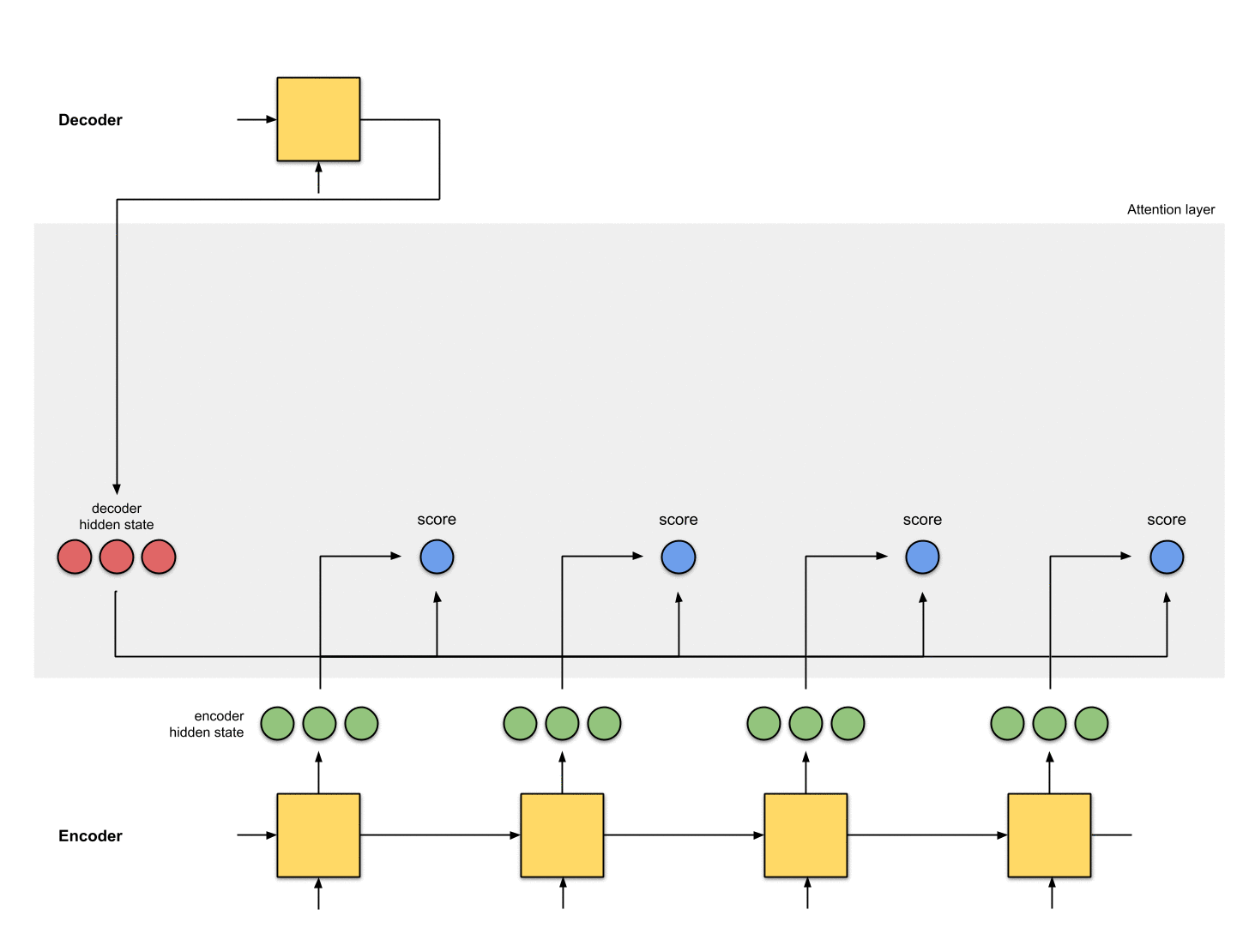
Fig. 1.1: Get the scores
decoder_hidden = [10, 5, 10]
encoder_hidden score
---------------------
[0, 1, 1] 15 (= 10×0 + 5×1 + 10×1, the dot product)
[5, 0, 1] 60
[1, 1, 0] 15
[0, 5, 1] 35
在上面的例子当中,编码器隐状态[5,0,1]的attention score最高。这就说明要接下来要被翻译的单词受这个编码器隐状态影响很大。
第三步:把所有的分数进行softmax
把上一步得到的分数进行softmax处理,变成[0, 1]之间的数,这些被softmax过后的分数表示注意力分布(attention distribution)。
encoder_hidden score score^
-----------------------------
[0, 1, 1] 15 0
[5, 0, 1] 60 1
[1, 1, 0] 15 0
[0, 5, 1] 35 0
注意:上面例子中,分数经过softmax之后变成了[0, 1, 0 ,0],所有的注意力都集中在到了[5, 0, 1]这个隐状态上。在实际操作中,注意力分布的元素并不是非0即1,而是介于0~1之间的浮点数,例如[0.23, 0.53, 0.17, 0.07]
第四步:把每个编码器隐状态和对应的注意力分布相乘
通过把每个编码器隐状态和对应的注意力分布相乘,我们得到了对齐向量(alignment vector 或者叫 annotation vector)。这就是对齐的机制。
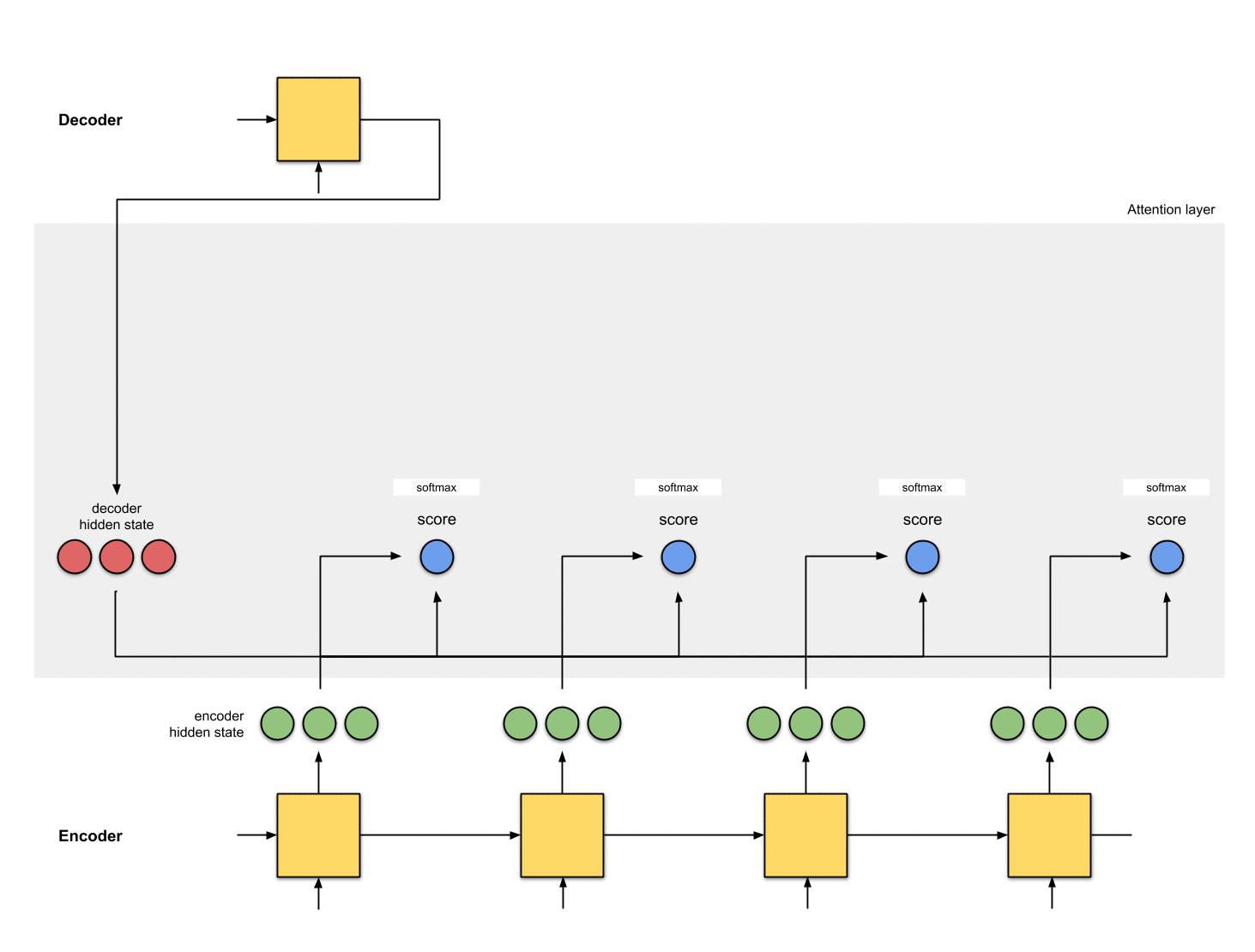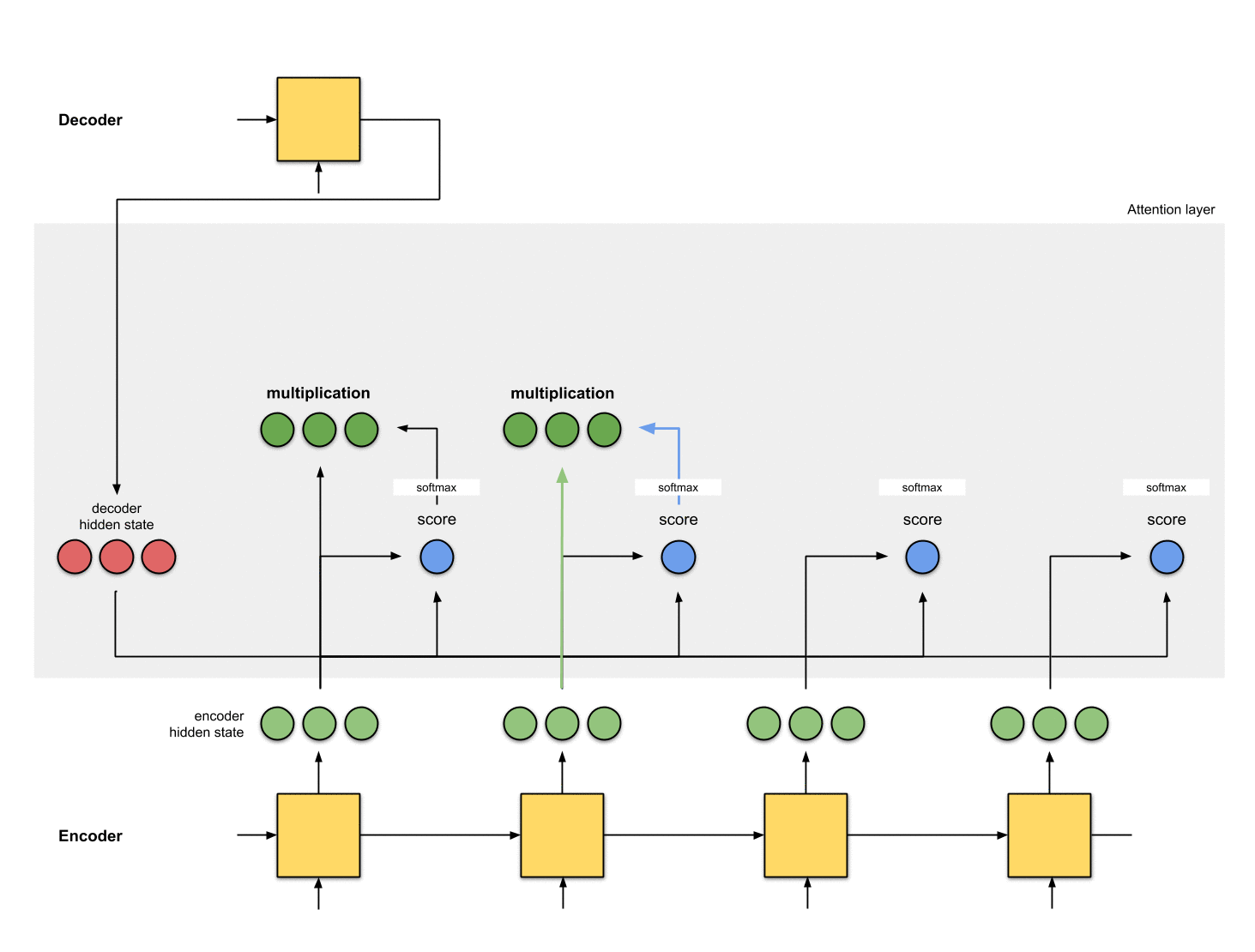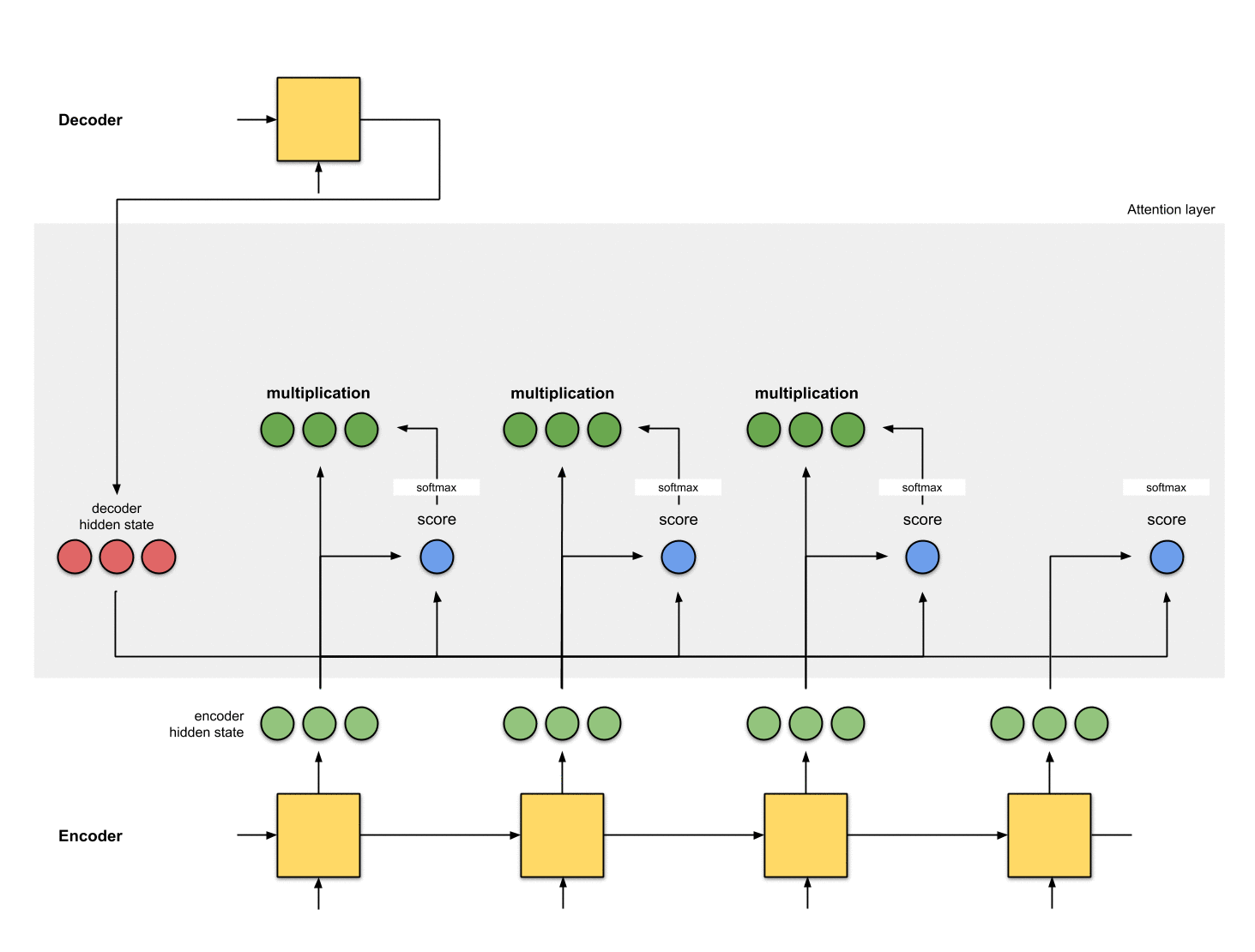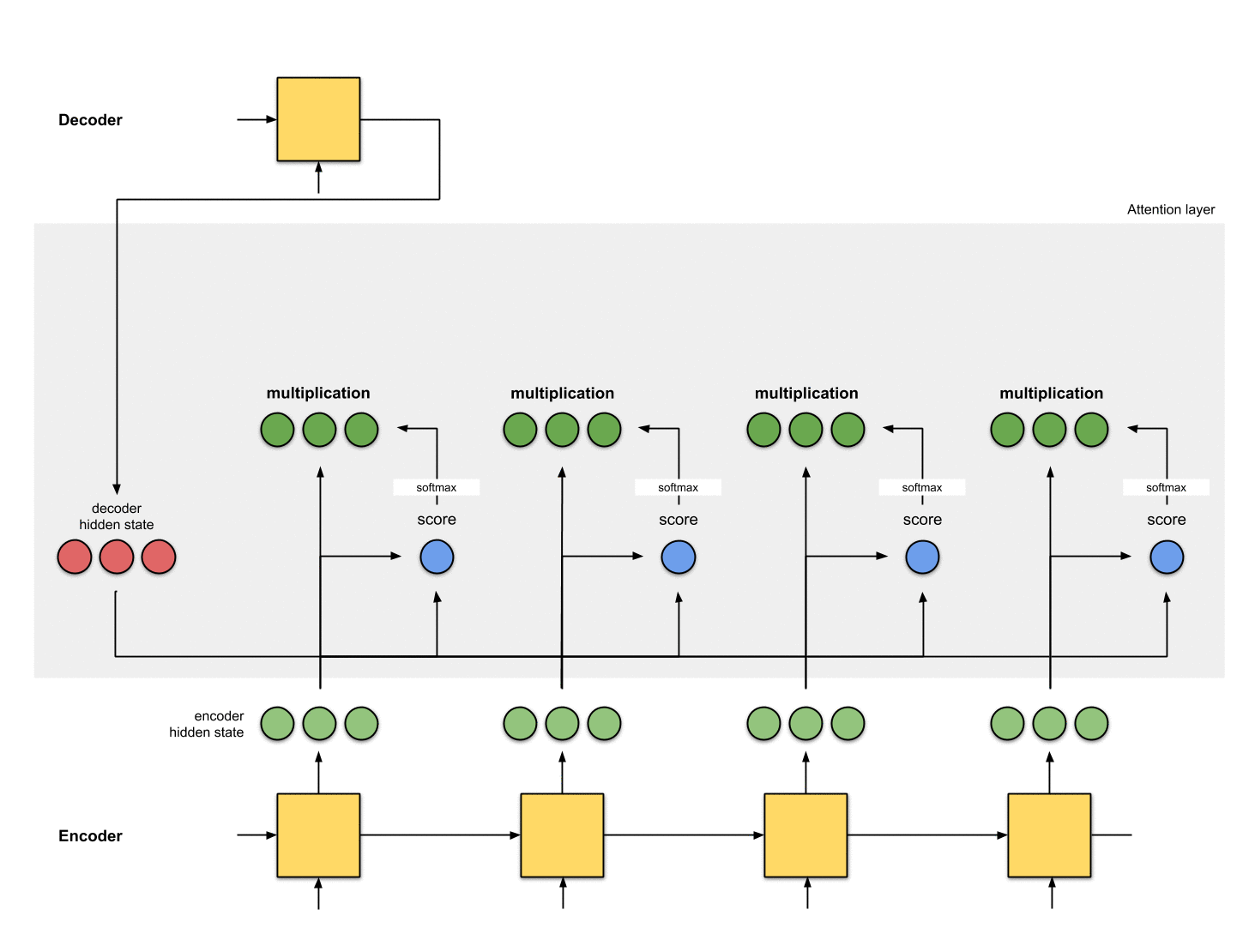
Fig. 1.3: Get the alignment vectors`
encoder score score^ alignment
---------------------------------
[0, 1, 1] 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 1783
1783











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









