







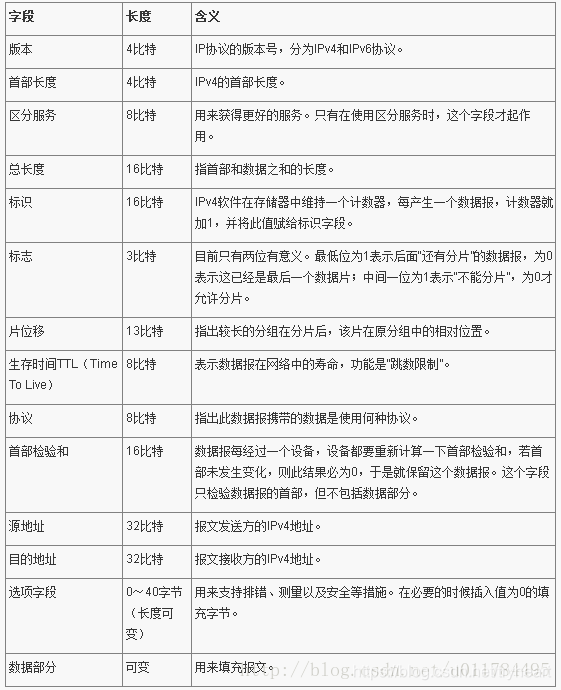
ipv4 头部数据格式
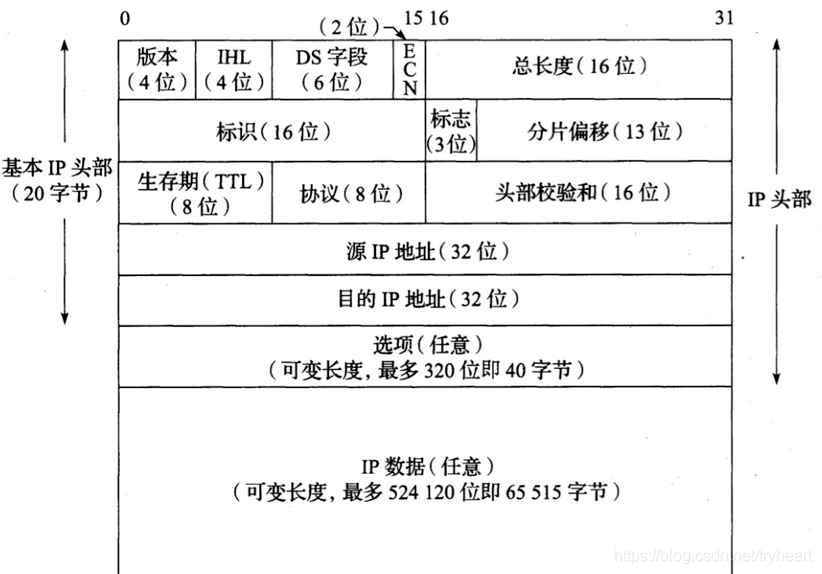
IPv4数据报,头部大小可变,4位的IHL字段被限制为15个32位字(60)字节。一个典型的IPv4头部包含20字节。源地址和目的地址的长度位32位。第二个32位字的大部分用于IPv4分片功能。头部校验和有助于确保头部字段被正确发送到目的地。
版本(Version)
版本字段指定了IP数据报中使用的IP协议版本,占四位。如国协议是IPV4,则值为0100。
头部长度(Header Length)
头部长度字段指示IP数据报头部的总长度,IP数据报头部的总长度以4字节为单位,该字段占4位。当报头中无选项字段时,报头的总长度为5,也就是5×4=205×4=20字节(此时,报头长度的值为0101)。这就是说IP数据报头部固定部分长度为20字节。当IP头部长度为1111时,头部的固定长度为15×4=6015×4=60字节。但报头长度必须是32位(四字节)的整数倍,如果不是,需要在选项字段的填充(PAD)字段中补0凑齐。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 6273
6273

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









