









1、为什么要分库分表
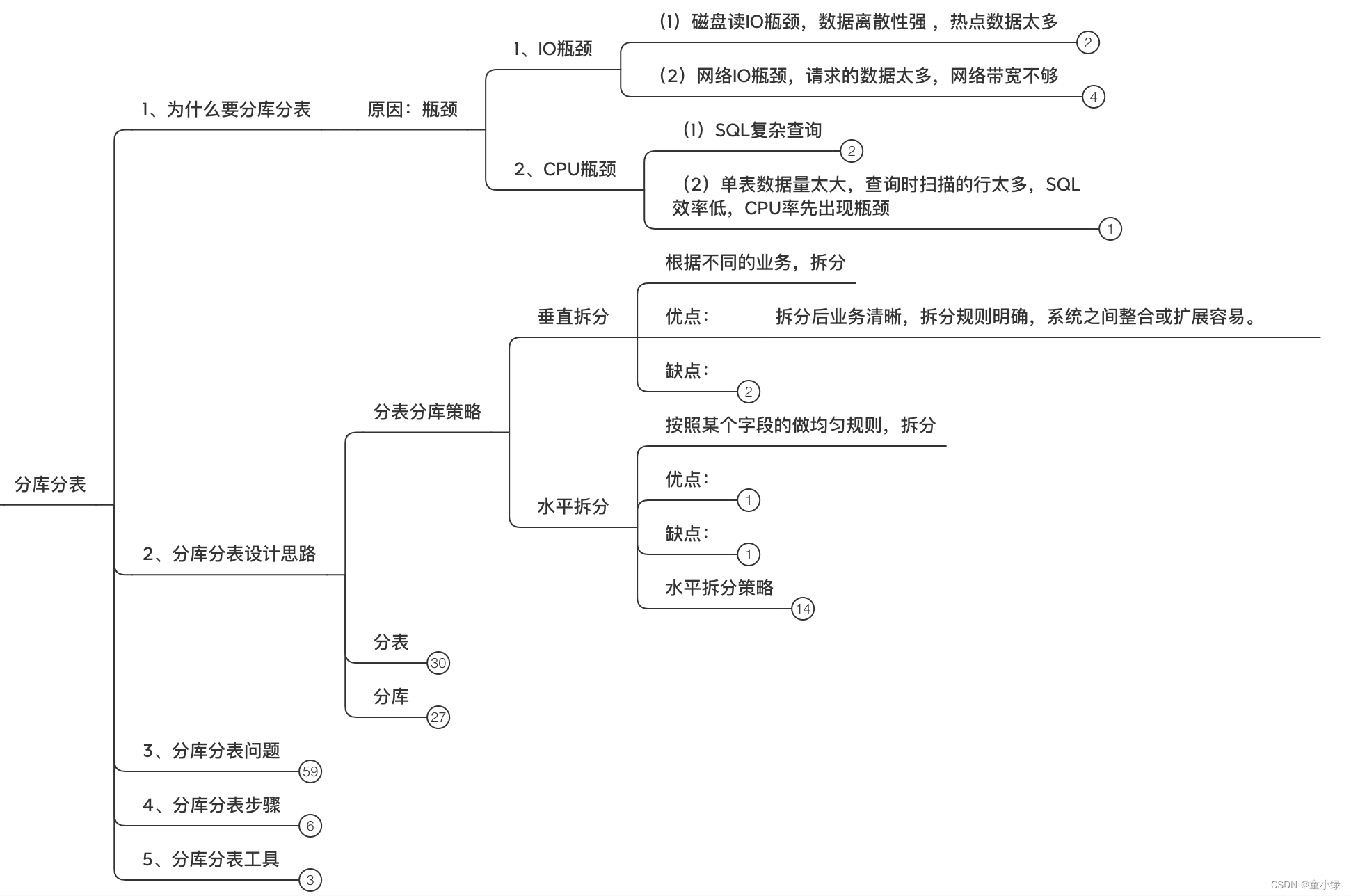
1、为什么要分库分表
出现数据库瓶颈,比如IO瓶颈,CPU瓶颈
1、IO瓶颈
(1)磁盘读IO瓶颈
- 数据体积比较大:
大量的写操作,磁盘IO读写必然慢,效率低
大量的读操作,如果数据离散性强,会造成磁盘随机读问题,IO慢,效率低;如果是并发读取的是热点数据,那么不会造成磁盘IO,一次读取磁盘缓存到cache,其他请求都从cache拿取。
- 缓存问题
热点数据太多,数据库缓存放不下,每次查询时会产生大量的IO,降低查询速度,但是不必分库分表,可以先优化buffer参数。
(2)网络IO瓶颈,
- 请求的数据太多,网络带宽不够。数据总体积不一定决定分库分表!有时候往往是请求压力大而决定分库分表。
由于请求响应的非对称性,网卡的请求速度很快 但是响应速度会很慢。在输出数据很大的时候,很容易造成IO
2、CPU瓶颈
(1)SQL复杂查询
-> SQL优化,建立合适的索引,在业务Service层进行业务计算
复杂SQL中包含join,group by,order by,非索引字段条件查询等,增加CPU运算的操作
(2)单表数据量太大,查询记录过多,容易查询时扫描的行太多,SQL效率低,CPU率先出现瓶颈
2、分库分表设计思路
一、按照拆分维度
垂直拆分
根据不同的业务,拆分
优点:
拆分后业务清晰,拆分规则明确,系统之间整合或扩展容易。
缺点:
a、部分业务表无法join,只能通过API方式解决,提高了系统复杂度
b、存在分布式事务问题。
水平拆分
按照某个字段的做均匀规则,拆分
优点:
提高SQL执行效率,提升系统的稳定性跟负载能力
缺点:
跨库join性能较差
二、按照拆分结果
分表 拆分表,大表变小表,还在同一个DB中
水平分表
概念:
以字段为key,在同一个数据库内,把同一个表的数据按一定规则拆到多个表中。
结果:
每个表的结构都一样;
每个表的数据都不一样,没有交集;
所有表的并集是全量数据;
场景:
单表的数据体积大,无并发问题,但是写操作、读取大字段、复杂SQL会影响了SQL效率,加重了CPU负担,以至于成为瓶颈。
分析:
表的数据量少了,单次SQL执行效率高,自然减轻了CPU的负担。
垂直分表
概念:
以字段为key,按照字段的活跃性、访问量、业务,将一个表按照字段分成多表,每个表存储其中一部分字段。
结果:
每个表的结构都不一样;
每个表的数据也不一样,一般来说,每个表的字段至少有一列交集,一般是主键,用于关联数据;
所有表的并集是全量数据;
场景:
- 主表和扩张表的访问请求出现偏移。
- 系统并发量不大,表记录不多,但是字段特别多,单行磁盘存储空间大,数据库缓存的数据行减少或者不足,查询时会去读磁盘数据产生大量的随机读IO,产生IO瓶颈。
- 单表字段多,混合高频数据和低频数据,加大请求压力。
分析:
大字段、字段多,业务混合热点数据、非热点数据,尽量设计为主表和扩展表,注意Join效能问题。
分库 拆分数据库,一个库变多个库,部署到不同服务器,可做微服务化拆分
水平分库
概念:
按表规则,将同一个表的数据按规则拆到不同的数据库中,每个库可以放在不同的服务器上
结果:
每个库的结构都一样;
每个库的数据都不一样,没有交集;
所有库的并集是全量数据;
场景:
系统绝对并发量上来了,分表难以根本上解决问题,并且还没有明显的业务归属来垂直分库。
分析:
库多了,io和cpu的压力自然可以成倍缓解。
垂直分库
概念:
按照业务将表进行分类,分布到不同的数据库上面,每个库可以放在不同的服务器上,它的核心理念是专库专用
结果:
每个库的结构都不一样;
每个库的数据也不一样,没有交集;
所有库的并集是全量数据;
场景:
系统绝对并发量上来了,并且可以抽象出单独的业务模块。
分析:
数据微服务了,那么是否就该考虑对应的服务是不是应该服务化了
3、分库分表问题
(1)、自增ID问题
自增ID问题解决办法
a、为数据库设置不同步长。缺点:步长确定后,无法扩展新的mysql,不然生成步长的规则可能会发生变化。
b、UUID形式,缺点是不能排序
c、使用雪花算法或redis解决
(2)、数据关联(join)查询问题
需要借助其他方案存储数据关联关系。
(3)、数据同步问题
升级过程中(升级从库、双写迁移),分表分库会造成数据不一致和冗余的情况,必须做数据校验工作。
4、分库分表步骤
1.估计容量(当前容量+增常量)
2.选key==》均匀
3.分表规则、拆分策略==》hash、range....
4.双写 + 定时任务(校对数据)
5.切表、切库(数据一致后进行)
5、分库分表工具
sharding-sphere:
前身是sharding-jdbc;
http://shardingsphere.apache.org/index_zh.html
Mycat:
http://www.mycat.io/
















 1566
1566











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









