







论文为2023年arxiv发表的文章,将LLM应用于实体识别任务中,达到监督学习极限性能,尤其在小样本时性能更好。
原文: https://arxiv.org/abs/2304.10428
代码路径: https://github.com/ShuheWang1998/GPT-NER
摘要
文章介绍了GPT-NER,一种创新方法,将大规模语言模型(LLM)应用于命名实体识别(NER)任务。GPT-NER通过将序列标记转换为生成任务,并采用自我验证策略解决LLM的过度自信问题。实验显示,GPT-NER在五个标准NER数据集上达到监督学习基线性能,尤其在数据稀缺时性能更佳,证明了其在资源有限的NER应用中的有效性。
1 介绍
大规模语言模型(LLM)在上下文学习方面展现出卓越能力,能够通过少量示例快速适应新任务,尤其在机器翻译、问答和实体抽取等NLP领域取得显著成果。然而,LLM在NER任务上的表现仍落后于监督学习方法,因为NER的序列标记特性与LLM的文本生成形式存在差异。
为此,文章提出了GPT-NER模型,它通过将NER任务转化为文本生成任务来解决这一问题,使用特殊标记来标识实体。GPT-NER还引入了自我验证策略,以减少LLM在实体识别上的过度自信倾向,有效缓解了幻觉问题。实验结果表明,GPT-NER在五个NER数据集上达到了与监督基线相当的性能,并在低资源和少镜头设置中表现尤为出色,显示出在标记样本数量有限的情况下的实际应用潜力。此外,GPT-NER在达到GPT-3的令牌数量限制时性能仍未饱和,暗示了使用更宽松的令牌限制可能带来进一步提升。
2 相关工作
2.1命名实体识别
命名实体识别(NER)是一种识别文本中的关键信息并将其分类到一组预定义类别中的任务。解决NER的一种常用方法是将其表述为序列标记任务。Sarzynska-Wawer等人(2021)通过大规模预训练模型提高了每个单词的质量。Li等人(2019a,b)将NER任务制定为MRC任务,并进一步利用骰子损失来提高MRC模型的性能,Wang等人(2022)提出了GNN-SL模型,允许通用NER模型在测试时参考训练样例。
2.2大语言模型和语境学习
大型语言模型(llm) 在各种自然语言处理任务上获得了显著的性能提升。将llm用于下游任务的策略可以分为两类:微调和上下文学习。微调策略采用预训练模型作为初始化,并在下游监督数据上运行额外的epoch 。与微调策略不同,情境学习(ICL)促使llm在少量演示下生成文本。
3背景
命名实体识别(NER)是一种典型的序列标注任务,它为给定句子x = {x1,…, xn},其中Y表示实体标签集,n表示给定句子的长度。
3.1 NER作为序列标记
解决NER的一种常用方法是将其表述为序列标记任务,该任务可分解为以下两个步骤:(1)表示提取和(2)分类。
表示提取 目的是获得输入序列中每个标记的高维表示。为了嵌入每个输入单词x,首先将输入句子x输入到编码器模型中,例如BERT (Devlin等人,2018)。然后将词嵌入模型最后一层的输出作为高维表示hi∈R m×1,其中n表示输入句子的长度,m表示向量维数的可变参数。
分类 对于分类,将每个嵌入的高维向量h发送到多层感知器,然后使用softmax函数生成命名实体词汇表上的分布:
pNER = softmax MLP(h ∈ R m×1 ) (1)
4 GPT-NER
GPT-NER遵循上下文学习的一般范式,可分为三个步骤:(1)提示构建:对于给定的输入句子X,为X构建一个提示(用Prompt(X)表示);(2)将构造好的提示符馈送给大型语言模型(LLM),得到生成的文本序列W = {w1,…wn};(3)将文本序列W转换为实体标签序列,得到最终结果。
4.1快速构建

图1是GPTNER中使用的提示符示例,它由三部分组成:
4.1.1任务说明
任务描述给出了任务的概述,任务描述可以进一步分解为三个组成部分:
(1)任务描述的第一句话
“我是一名优秀的语言学家”
是一个常量,告诉LLMs使用语言知识产生输出;
(2)第二句
“任务是在给定的句子中标记[实体类型]实体”
是一个变量句,表示要提取的实体类别,[Entity Type]表示要提取的实体类型,例如图1中的Location。当前的大规模语言模型(如GPT-3)因硬件限制对输入提示符长度有硬性限制(例如GPT-3的4096个令牌),导致无法在单个提示中包含所有实体类型的描述和示例。因此,对于每个输入句子,需要对所有实体标签进行N次遍历,将一个多类分类任务转化为N个二元分类任务。
(3)第三句
“以下是一些例子”
标志着描述的结束,指出了少样本演示的位置
4.1.2少样本示范
少样本的演示添加到提示符中有两个主要目的:
(1) 它为LLM输出的格式设定了标准;
(2) 它为LLM提供了直接的任务证据和预测参考,帮助模型更好地理解任务要求。
演示包含了一系列按顺序排列的示例,每个示例包括输入序列X和相应的输出序列W。
输入:[示例句]1
输出:[标记句]1
···
输入:[示例句]k
输出:[标记句]k
其中k表示演示次数。
LLM输出格式 每个标注句子W的格式至关重要,它是一个文本序列,应满足以下条件:(1)它需要包含每个单词标签的信息,并易于转换为实体类型序列;(2)它需要使llm能够顺利、轻松地生成模型,从而提高模型的最终精度。
首先给出W形式的几个坏例子:对于给定的输入序列“哥伦布是一个城市”,“LOC O O O”是W的直观格式,满足条件(1);但对于条件(2),要生成“LOC O O O”,LLM首先需要学习输入序列“Columbus is a city”中每个位置与W中的每个位置之间的对齐:Columbus to LOC, is to O, a to O, city to O,这自然增加了生成任务的难度。另外当输入句子很长时,GPT-3很难生成与输入句子相同长度的输出。
为解决这个问题,LLM输出采用以下格式:如果输入序列不包含任何实体,W只是复制输入X;对于输入序列中的一个/多个实体,我们使用特殊的标记“@@”和“##”来包围它/它们。下面是提取LOC实体的示例:
Input: Columbus is a sailor1
Output: Columbus is a sailor1
Input: Columbus is a city2
Output: @@Columbus## is a city2
4.1.3输入句
输入输出的格式为:
input: [the input sentence]
output:
其中“output:”表示LLM开始生成标记序列的标志。
如图1底部所示,给定输入句“中国说台湾破坏会谈气氛”,llm4生成标注句“@@中国##说@@台湾##破坏会谈气氛”,其格式与前面的演示相同,其中“中国”和“台湾”两个词是识别的位置实体。
4.2少量演示检索
4.2.1随机检索
最直接的策略是从训练集中随机选择k个样本。缺点很明显:不能保证检索到的示例在语义上接近输入。
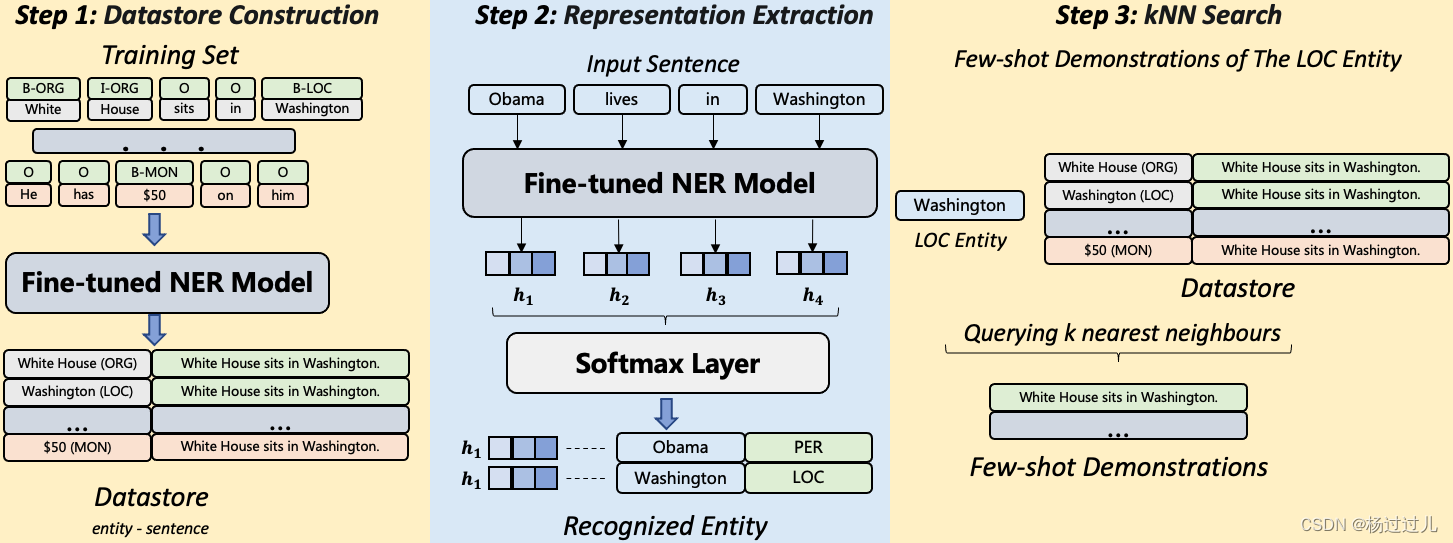
图 2:一种通过实体级别嵌入来检索少量样本(few-shot)示例的方法
4.2.2基于knn的检索
为解决第4.2.1节中提到的相关性问题,从训练集中检索输入序列的k个最近邻(kNN):首先计算所有训练样本的表示,基于此为输入测试序列获得k个最近邻。
基于句子级表示的kNN
使用SimCSE等文本相似度模型获取训练样本和输入序列的句子级表示,并通过余弦相似度计算来找到kNN。
缺陷:由于NER是标记级任务,侧重于局部证据,仅基于句子级表示的kNN可能不足以提供有用的NER信息。
实体级嵌入
通过微调的NER模型提取所有训练样本的标记级表示,并构建数据存储。对于输入序列中的每个标记,检索其k个最近邻标记,并从这些标记关联的句子中选择k个最相关的示例作为参考。这种方法更精确地针对NER任务的局部性。
4.3自我验证
LLMs 明显存在幻觉或过度预测问题。特别是对于NER, llm强烈倾向于过度自信地将NULL输入标记为实体。
Prompt: I am an excellent linguist. The task is to label location entities in the given sentence.
Below are some examples.
Input:Columbus is a city
Output:@@Columbus## is a city
Input:Rare Hendrix song sells for $17
Output:
GPT-3 Output:
Rare @@Hendrix## song sells for $17
为纠正GPT-3将"Hendrix"错误识别为地点实体的问题,提出了一种自我验证策略。该策略要求LLM对提取的实体进行正确性验证,回答"是"或"否"。如图3所示,自我验证的提示包括任务描述和少量样本示例,每个示例包括一个句子、一个问题以及预期的"是"或"否"答案。这些示例随后与测试用例一起输入LLM以产生输出。

图3:使用GPT-3的验证提示示例
演示选择
在进行少量样本的自我验证任务时,选择与查询实体语义相关的训练示例至关重要。采用实体级嵌入方法,通过微调的NER模型构建数据存储,并提取查询词的表示。基于此表示,从数据存储中选取k个相关示例作为演示,其中正确答案依据检索实体是否符合查询类型而定。
5实验
使用GPT-3 作为所有实验的LLM主干。将最大输出长度设置为512个令牌。温度设置为0,top_p设置为1,frequency_penalty设置为0,presence_penalty设置为0,best_of设置为1。
5.1完整训练集的结果
5.1.1 Flat NER的结果
对于平面NER,实体之间不能相互重叠。在两个广泛使用的平面ner数据集(English CoNLL2003和OntoNotes5.0)上进行了实验,使用跨度级精度、召回率和F1分数作为评估指标。
CoNLL2003 包含四种类型的命名实体:Location、Organization、Person和Miscellaneous。
OntoNotes5.0 包含18种类型的命名实体:11种类型(例如,Person, Organization)和7个值(例如,Date, Percent)。
Baselines 采用目前广泛使用的NER系统作为基准,包括:BRT- tagger 、MRC-NER 、MRC-NER+DSC、GNN-SL、ACE+document-context。
主要结果 表1和表2分别展示了在部分和完整测试集上进行平面NER任务的结果
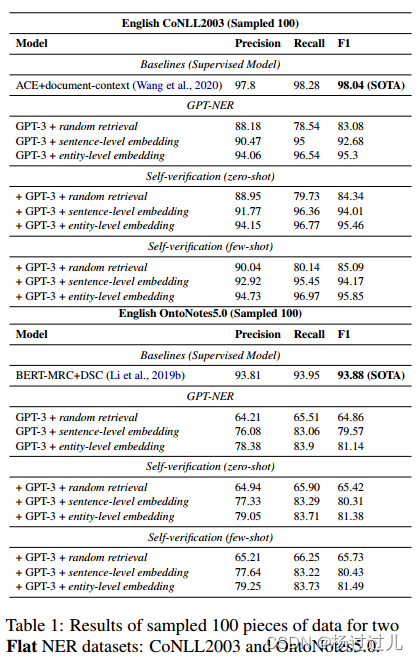
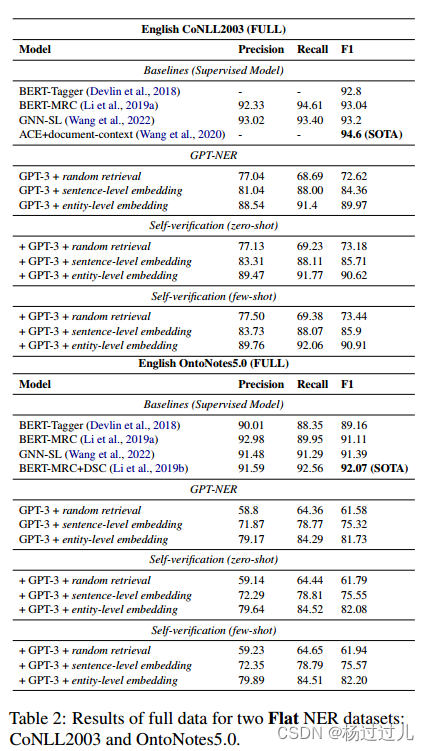
实验结果显示kNN检索对NER任务性能至关重要,句子级嵌入的kNN示例检索显著提升了结果。进一步将句子级嵌入改为标记级嵌入,提升了CoNLL2003和OntoNotes5.0数据集上的表现。引入自我验证策略后,零样本和少样本学习的性能均有所提升,减轻了GPT-3的过度预测问题。尽管基于LLM的系统与BERT监督基线相当,但与SOTA监督模型仍有差距。消融研究表明,GPT-3在kNN示例数量上仍有提升空间,预期GPT-4的更高令牌限制将进一步改善性能。
5.1.2嵌套NER的结果
对于嵌套NER,每个句子中的实体可以相互重叠,例如
句子:中国驻法国大使馆
地理政治实体:Chinese, France
设施实体:中国驻法国大使馆,
其中两个地理政治实体“Chinese”和“France”与设施实体“the Chinese in France”重叠。
在三个广泛使用的嵌套NER数据集上进行了实验:ACE2004, ACE2005和GENIA,并使用跨度级精度,召回率和F1分数进行评估。
Baselines 选用了四种主流的监督学习模型作为基线对比:
- BERT-MRC,一种将NER视为MRC任务的模型,在GENIA数据集上表现最佳。
- Triaffine+BERT,该模型在完整数据集上微调BERT,融合多种因素以改善跨度表示和分类。
- Triaffine+ALBERT,与Triaffine+BERT类似,但使用的是ALBERT模型。
- BINDER,一种在ACE2004和ACE2005数据集上表现出色的模型,采用双编码器和对比学习策略来映射文本跨度和实体类型。
这些基线模型展示了不同方法在NER任务上的应用,从深度阅读理解到融合异构特征,以及利用双编码器对比学习框架。
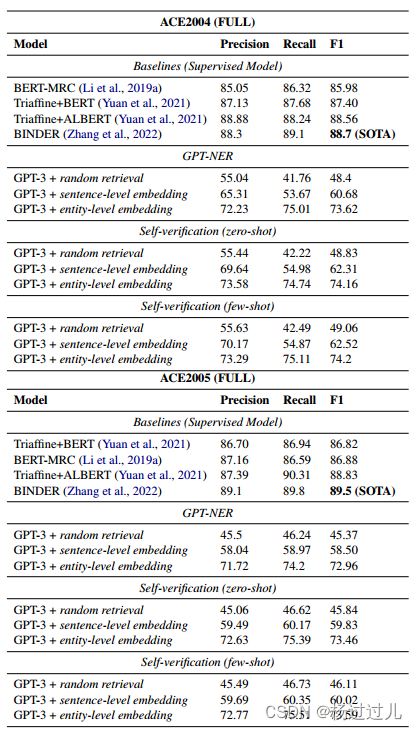
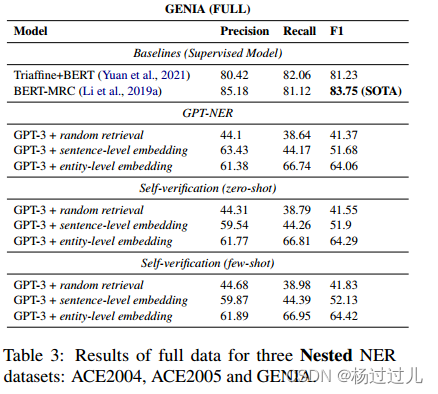
主要结果 表3展示了NER的主要结果,与平面NER任务相似,kNN检索在嵌套NER中同样重要,实体级嵌入检索显著优于随机检索。将句子级嵌入改为实体级嵌入进行kNN示例搜索可显著提升性能。自我验证进一步提高了性能,尤其在ACE2004数据集上。然而,GPT-NER与SOTA模型间的差距较大,原因在于嵌套NER数据集中相似实体类型更多,且注释规则复杂,GPT-3在有限示例下难以区分和学习这些复杂规则,而监督模型则能更好地适应。
5.2低资源场景结果
为了模拟低资源环境,在CoNLL2003数据集上对GPT-NER进行了不同训练样本数量下的实验:8句、100句、1000句和10000句,分别占完整训练集的0.063%、0.788%、7.880%和78.808%。特别地,8句训练样本的设置确保覆盖每种实体类型的一个正面和负面案例。所有评估均在数据集的完整测试集上进行,以评估GPT-NER在资源受限情况下的性能。
在实验设置中,沿用了第5节的GPT参数,并在不同规模的训练子集上训练了当前最先进的ACE模型作为基线对比。GPT-NER在少样本学习阶段采用了随机和基于句子级嵌入的两种示例检索方法。而在自我验证阶段,GPT-NER采用了零样本学习策略,即不依赖于示例进行学习。
5.2.1结果
图4展示了实验结果。在训练集极小的情况下,GPT-NER的F1分数远高于监督模型,显示出其在低资源条件下的优越泛化能力。随着训练数据量的增加,kNN搜索的性能提升速度快于随机检索,因为kNN更可能选择与输入相关的示例。当数据量达到10%,监督模型性能显著提升,而GPT-3的性能提升有限,这表明在上下文学习中,提高检索示例的质量和优化提示结构比单纯增加数据量更为重要。
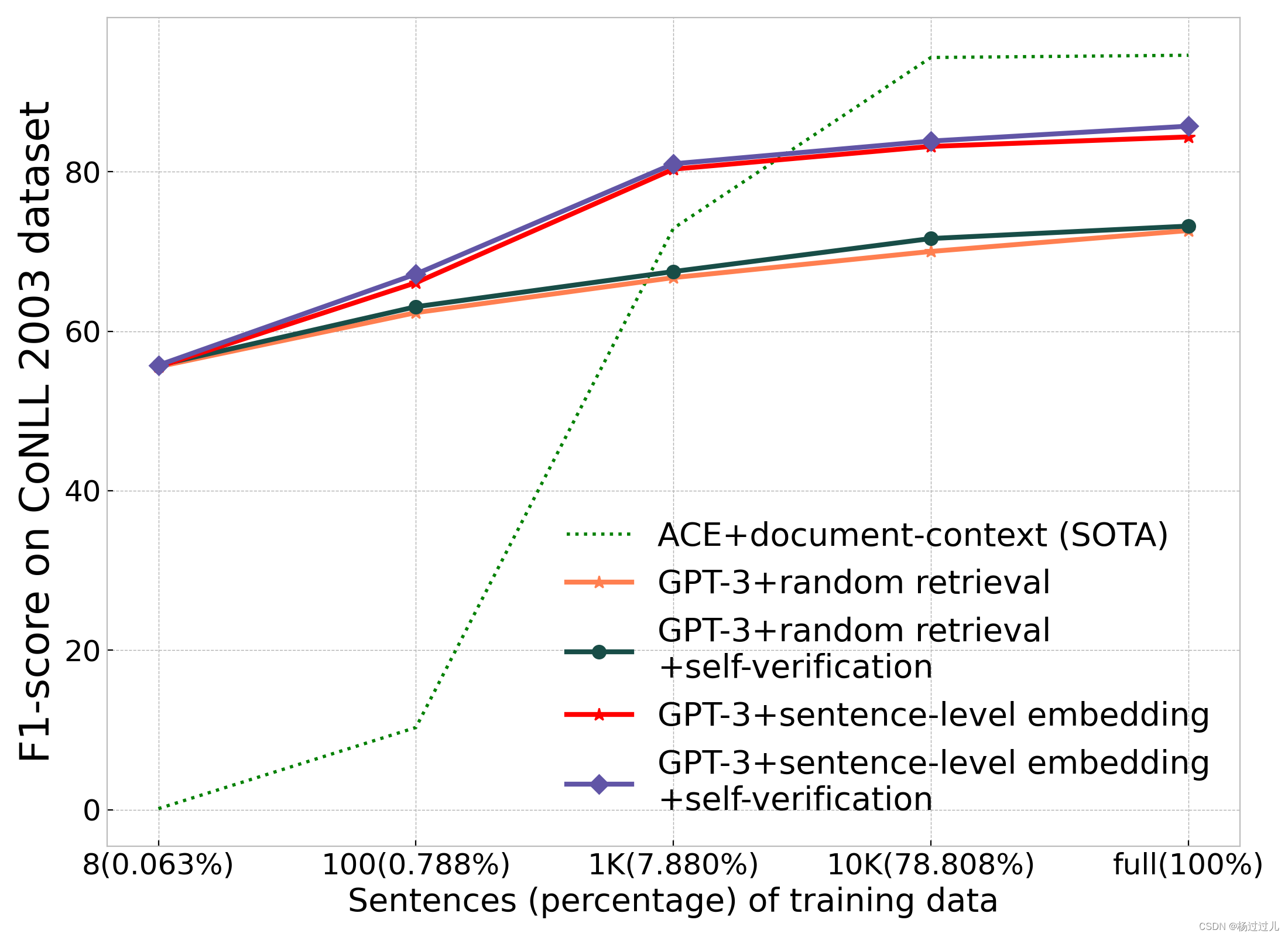
图4:CoNLL2003数据集上的低资源比较。
6消融研究
6.1改变LLM输出的格式
在第4.1.2节中,提出使用特殊标记“@@”和“##”来规范GPT-3的输出格式,以清晰地标识实体。与其他两种输出格式(BMES和实体+位置)相比,我们的##@@策略在CoNLL 2003数据集上的少样本实验中表现出色,F1分数达到92.68,而BMES和实体+位置的F1分数分别为29.75和38.73。BMES策略要求LLM学习输入词与标签间的复杂对齐,而实体+位置策略中LLM常混淆位置索引的含义。这些因素导致这两种策略的性能远低于我们的##@@策略,尤其是在处理长句子时。此外,不正确的位置索引也增加了将输出文本映射到序列标记评估格式的难度。
6.2少样本演示的数量
在CoNLL 2003数据集的100样本上进行的实验显示,随着示例数量的增加,基于LLM的结果持续提升,且在接近GPT-3的4096令牌限制时性能仍未饱和,表明增加示例数量仍有提升空间。当示例数量较少(k=2、4)时,基于kNN的检索策略在性能上不如随机检索,因为kNN倾向于选择与输入句子高度相似的示例,如果输入句子不含实体,检索的示例可能同样不含实体,导致LLM无法学习到期望的输出格式。例如,在需要识别地点实体的少样本学习中,如果所有示例都不含NER,GPT-3可能会以自己的格式输出,而不是遵循给定的格式要求。如下例所示:
提示: 我是一个出色的语言学家。任务是在给定句子中标记组织实体。以下是一些示例。
输入:Korean pro-soccer games
输出:Korean pro-soccer games
输入:Australia defend the Ashes
输出:Australia defend the Ashes
输入:Japan get lucky win
输出:
GPT-3 输出:
Japan [Organization Entity] get lucky win
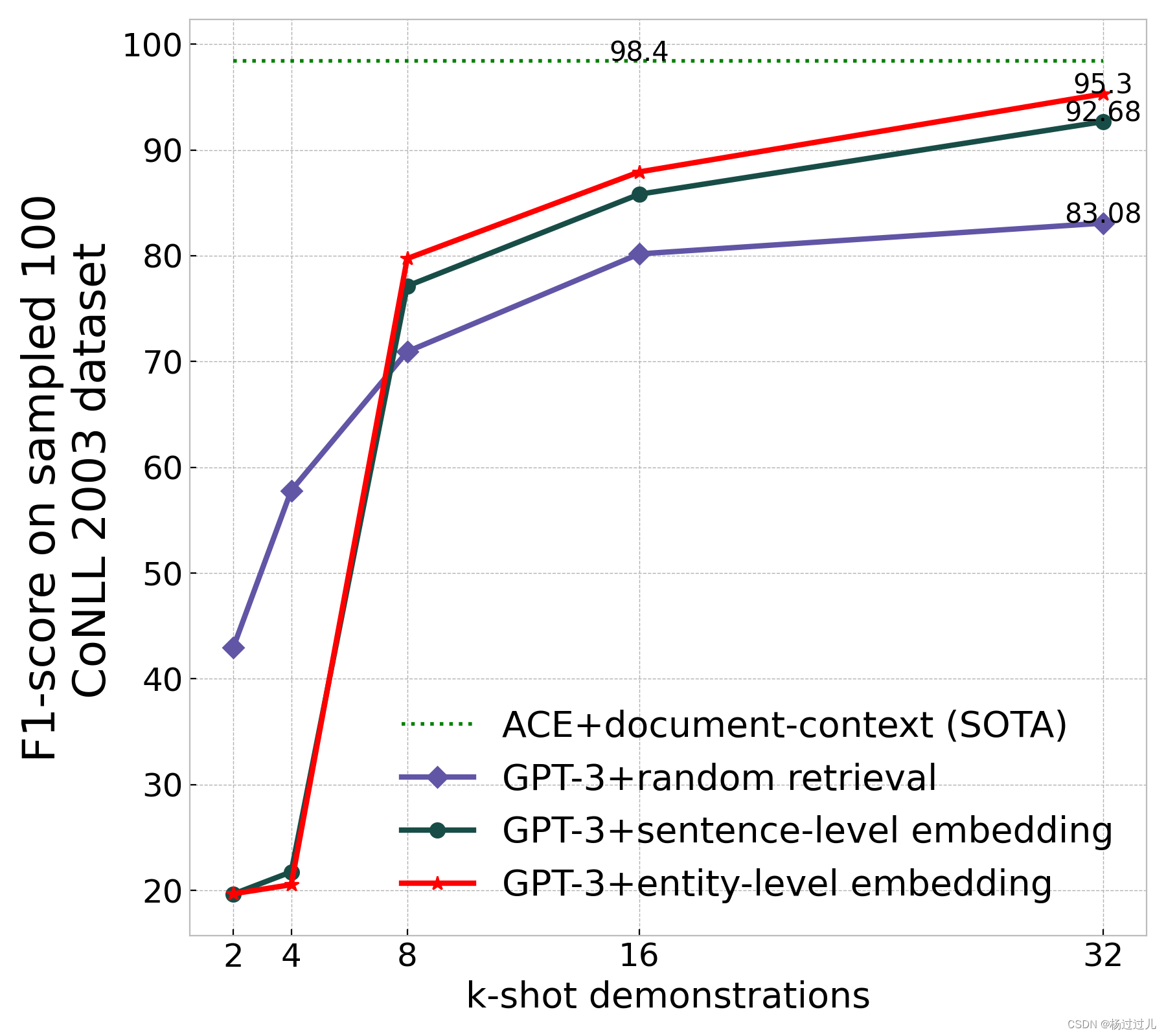
图5:不同k-shot演示的比较。
7结论
文提出了GPT-NER模型,通过在实体周围使用特殊标记来指导LLM生成标记序列,以适应NER任务,并引入自我验证策略来解决LLM的幻觉问题。在平面和嵌套NER数据集上的实验显示,GPT-NER与完全监督的基线性能相当。特别是在训练数据极其有限的低资源场景下,GPT-NER的性能显著优于监督模型,显示出其在此类情况下的巨大潜力。

















 121
121

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









