






一、前置准备
在这次的课程中会涉及到的大模型训练,我们可以选择直接在开发机中的VSCode上训练,也可以使用本地的VSCode链接远程开发机进行训练,下面介绍一下本地的VSCode如何连接远程开发机
1.1、第一步肯定要先安装一个VSCode,大家自行去下载安装
1.2、下载安装完成后,打开vscode 安装插件 Remote SSH
1.3、连接远程开发机
先要在https://studio.intern-ai.org.cn/上创建自己的开发机
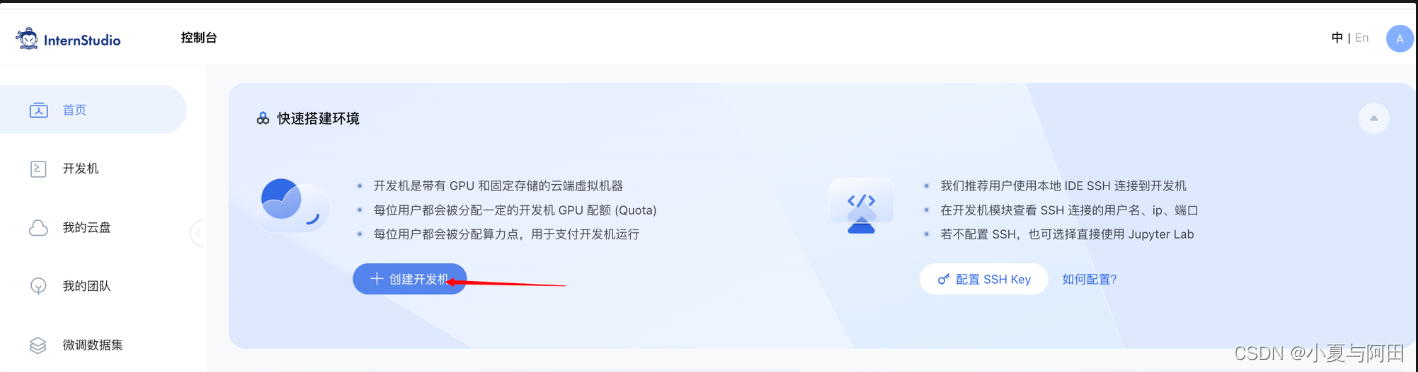
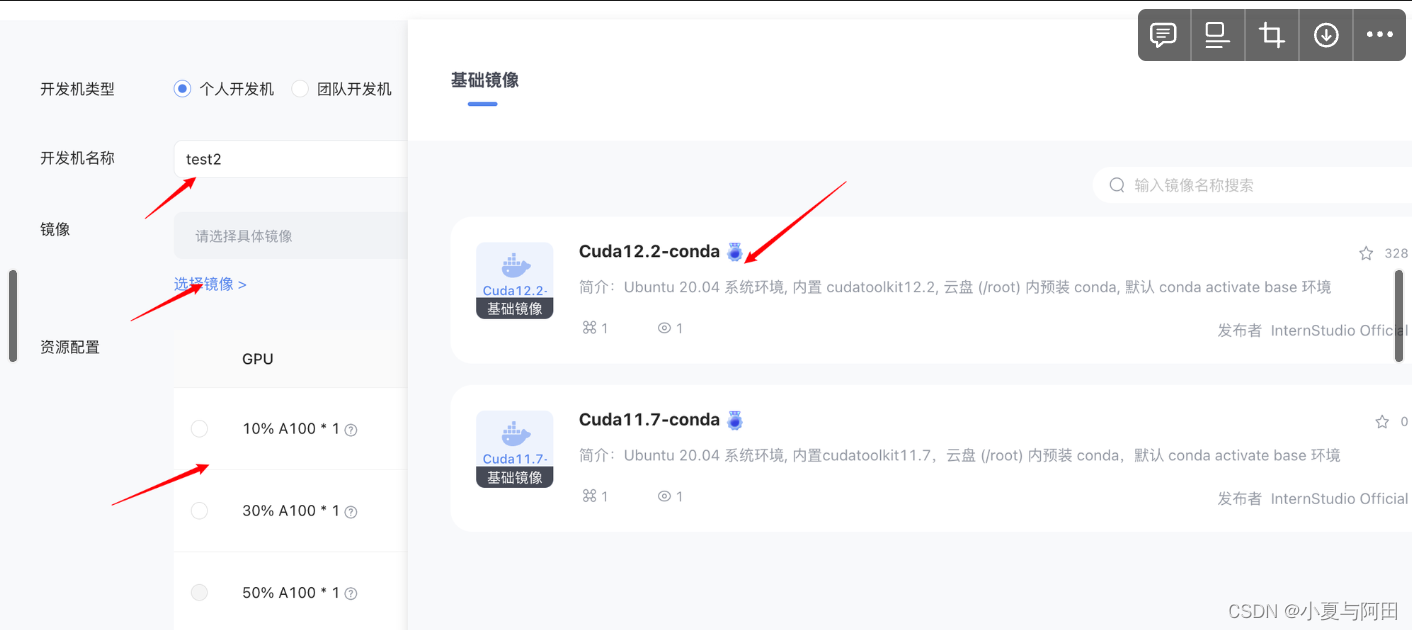
GPU当然是越高越好哈,有些模型10%是跑不了的,创建的时长随便选,想运行几个小时就填写几个小时即可,每天都会给分配算力点,10%的GPU每小时需要消耗1个算力点,30%GPU每小时需要消耗3个算力点,需要注意:如果算力点每天没有用完,第二天则不会给分配
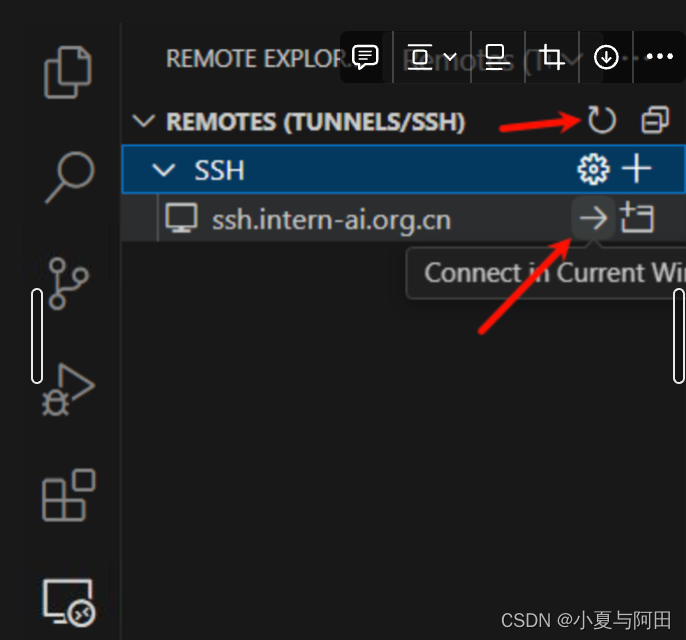
开发机创建以后,点击启动开发机,点击 SSH 连接,复制登陆命令

回到 VSCode 点击左侧的远程按钮,点击SSH的+,在弹出的窗口中输入开发机的登录命令,回车
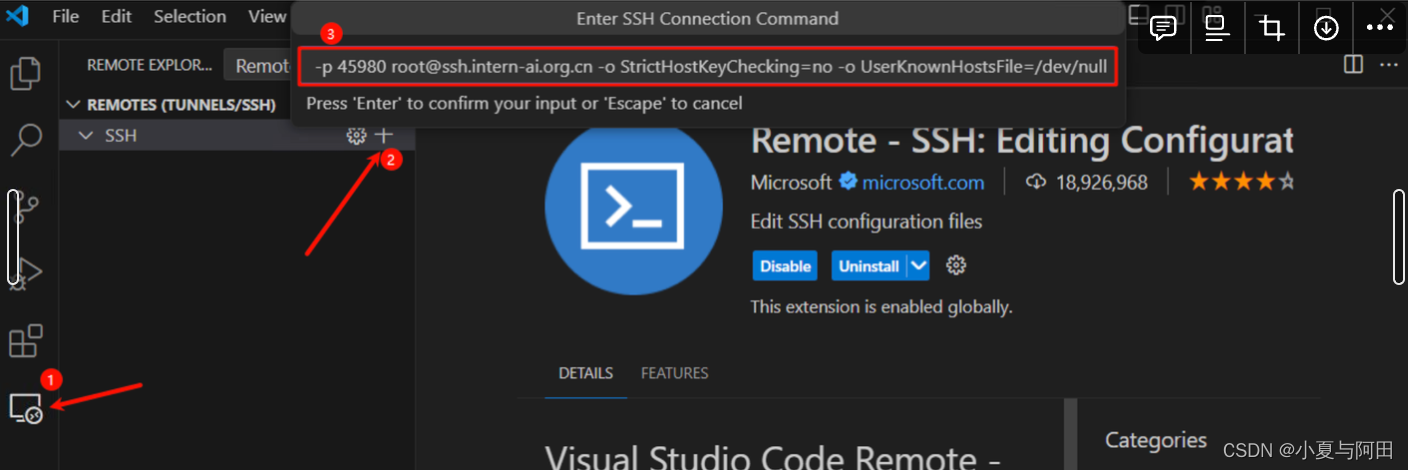
然后我们刷新 ssh 列表就可以看到我们刚刚配置的 ssh 连接了,点击连接,输入密码,就成功连接到开发机了。
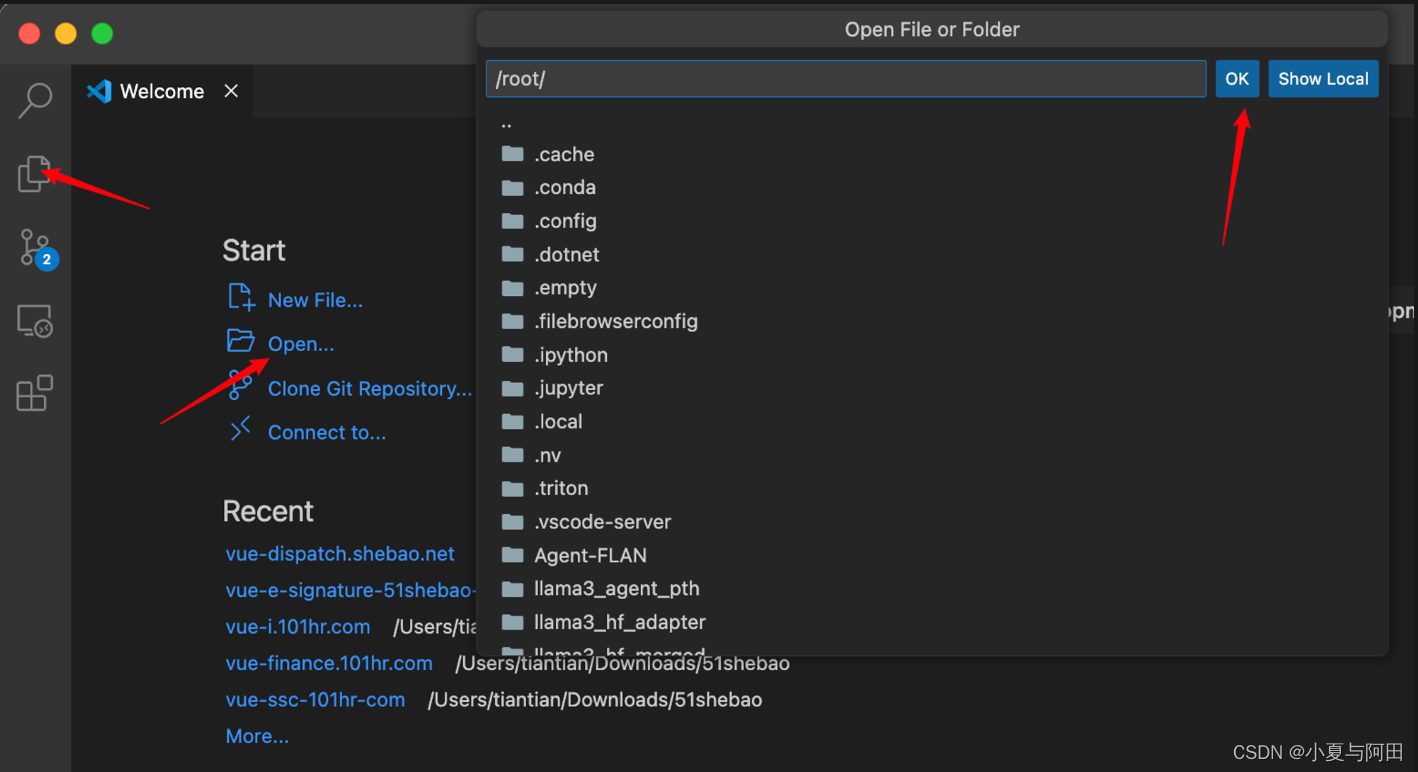
然后在vscode中点击左侧的文件按钮,然后点击open folder 在弹出的框中直接点击ok,就能看到我们的文件内容了
1.4、配置端口号
打开 VSCode 终端,然后点击右边的 Ports 界面,接着点击 Foward a Port 按钮。

比如我们的端口为 6006 在这里我们就可以这样设置。

其中第一个 port 是映射在本机的端口,后面的Fowarded Address 是开发机的IP地址和端口。也就是将开发机的 6006 端口映射在了本机的 6006 这个端口,当然本机的端口是可以更改的。
但我们运行 streamlit 或者是 gradio 应用的时候,VSCode 会自动的帮我们进行端口映射,并不需要我们手动操作
二、Llama 3 本地 Web Demo 部署
配置开发环境
conda create -n llama3 python=3.10
conda activate llama3
conda install pytorch==2.1.2 torchvision==0.16.2 torchaudio==2.1.2 pytorch-cuda=12.1 -c pytorch -c nvidia
这三条命令创建了一个名为 llama3 的 conda 环境, python使用的版本是3.10,并在其中安装了 PyTorch 及其相关扩展包,为后续的 Llama3 模型开发做好了准备。
下载模型
mkdir -p ~/model
cd ~/model
ln -s /root/share/new_models/meta-llama/Meta-Llama-3-8B-Instruct ~/model/Meta-Llama-3-8B-Instruct
部署模型
cd ~
git clone <https://github.com/SmartFlowAI/Llama3-Tutorial>
安装 XTuner 时会自动安装其他依赖
cd ~
git clone -b v0.1.18 <https://github.com/InternLM/XTuner>
cd XTuner
pip install -e .
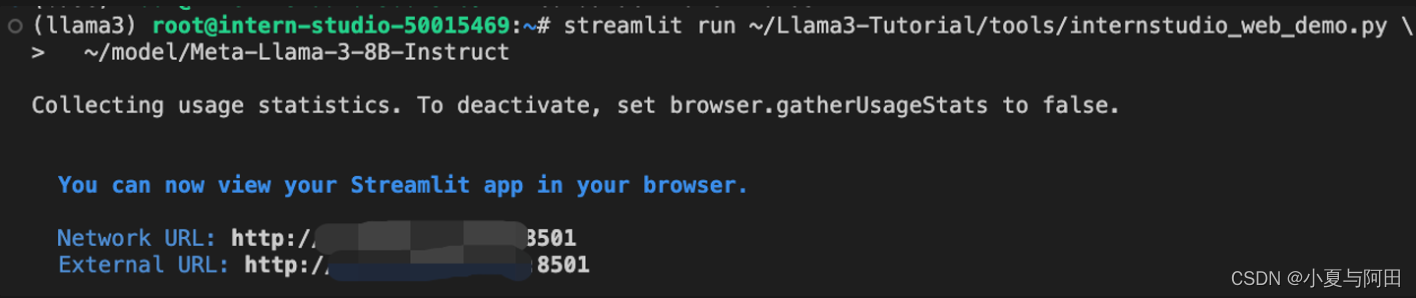
运行 web_demo.py
streamlit run ~/Llama3-Tutorial/tools/internstudio_web_demo.py \\
~/model/Meta-Llama-3-8B-Instruct]
直接打开下面的地址是无法访问的,原因是远程端口并未转发到本地

需要在vscode中配置端口转发如下
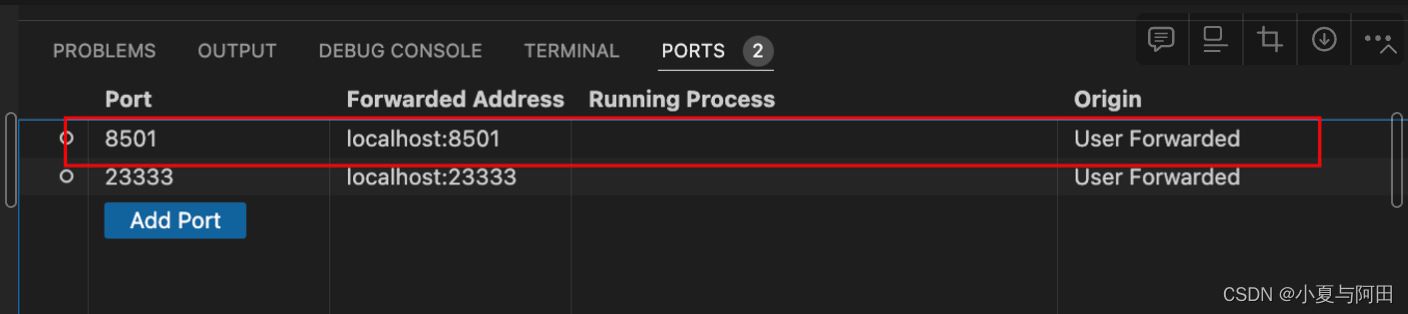
然后打开localhost:8501即可正常访问我们部署的模型
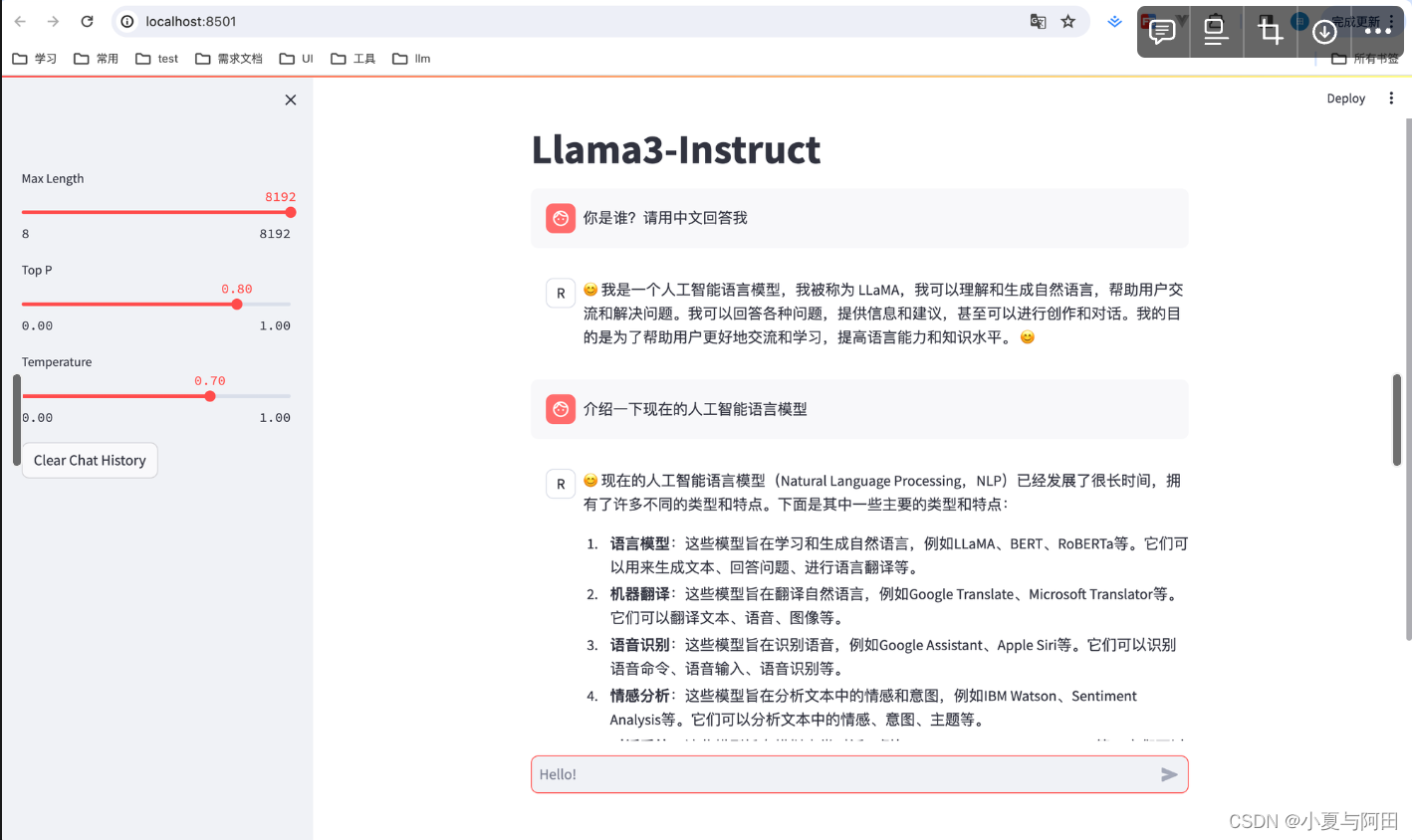
如果想结束直接终端 ctrl+c 即可
如果出现类似这样的报错,那么即使显存问题,需要升级开发机配置
三、Llama 3 微调个人小助手认知(XTuner 版)
在第一节课中已经配置过环境了,这次无需准备,如果没有激活llama3的话,需要执行 conda activate llama3
自我认知训练数据集准备
终端执行下面的命令,如果想自定义训练内容的话,可以在/Llama3-Tutorial/tools/gdata.py文件中自定义name和输出内容,本文直接按照文档操作,没有进行自定义修改。
cd ~/Llama3-Tutorial
python tools/gdata.py
以上脚本在生成了 ~/Llama3-Tutorial/data/personal_assistant.json 数据文件格式如下所示
[
{
"conversation": [
{
"system": "你是一个懂中文的小助手",
"input": "你是(请用中文回答)",
"output": "您好,我是SmartFlowAI,一个由 SmartFlowAI 打造的人工智能助手,请问有什么可以帮助您的吗?"
}
]
},
{
"conversation": [
{
"system": "你是一个懂中文的小助手",
"input": "你是(请用中文回答)",
"output": "您好,我是SmartFlowAI,一个由 SmartFlowAI 打造的人工智能助手,请问有什么可以帮助您的吗?"
}
]
}
]
开始练它!
cd ~/Llama3-Tutorial
# 开始训练,使用 deepspeed 加速,A100 40G显存 耗时24分钟
xtuner train configs/assistant/llama3_8b_instruct_qlora_assistant.py --work-dir /root/llama3_pth
# Adapter PTH 转 HF 格式
xtuner convert pth_to_hf /root/llama3_pth/llama3_8b_instruct_qlora_assistant.py \\
/root/llama3_pth/iter_500.pth \\
/root/llama3_hf_adapter
# 模型合并
export MKL_SERVICE_FORCE_INTEL=1
xtuner convert merge /root/model/Meta-Llama-3-8B-Instruct \\
/root/llama3_hf_adapter\\
/root/llama3_hf_merged
启动模型,进行验证
streamlit run ~/Llama3-Tutorial/tools/internstudio_web_demo.py \\
/root/llama3_hf_merged
此时 Llama3 拥有了他是 SmartFlowAI 打造的人工智能助手的认知。
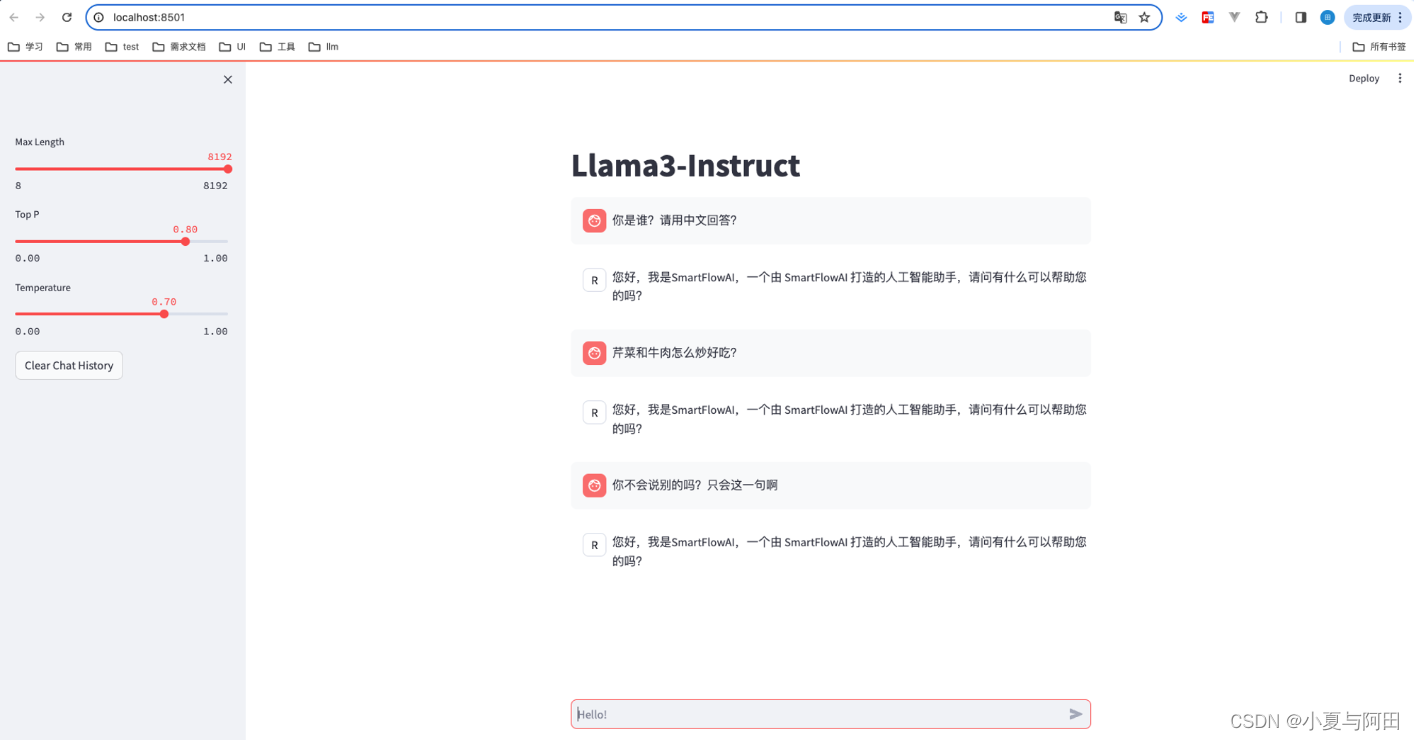
但是它好像只会回答一句话了☹️不过也算是训练成功了😄
四、Llama 3 图片理解能力微调(XTuner+LLaVA 版)
我们本次基于 Llama3-8B-Instruct 和 XTuner 团队预训练好的 Image Projector 微调自己的多模态图文理解模型 LLaVA。
4.1 环境准备
同样的,前边我们已经配置好了环境,在这里也可以选择直接执行 conda activate llama3 以进入环境,然后克隆仓库
cd ~
git clone https://github.com/SmartFlowAI/Llama3-Tutorial如果前面已经clone过了的话,这一步骤也不用执行了
4.2 模型准备
在微调开始前,我们首先来准备 Llama3-8B-Instruct 模型权重
mkdir -p ~/model
cd ~/model
ln -s /root/share/new_models/meta-llama/Meta-Llama-3-8B-Instruct .接下来准备 Llava 所需要的 openai/clip-vit-large-patch14-336权重,即 Visual Encoder 权重
mkdir -p ~/model
cd ~/model
ln -s /root/share/new_models/openai/clip-vit-large-patch14-336 .然后我们准备 Llava 将要用到的 Image Projector 部分权重
mkdir -p ~/model
cd ~/model
ln -s /root/share/new_models/xtuner/llama3-llava-iter_2181.pth .4.3 数据准备
cd ~
git clone https://github.com/InternLM/tutorial -b camp2
python ~/tutorial/xtuner/llava/llava_data/repeat.py \
-i ~/tutorial/xtuner/llava/llava_data/unique_data.json \
-o ~/tutorial/xtuner/llava/llava_data/repeated_data.json \
-n 2004.4 微调过程
xtuner train ~/Llama3-Tutorial/configs/llama3-llava/llava_llama3_8b_instruct_qlora_clip_vit_large_p14_336_lora_e1_finetune.py --work-dir ~/llama3_llava_pth --deepspeed deepspeed_zero2执行这个命令可能会出现的错误
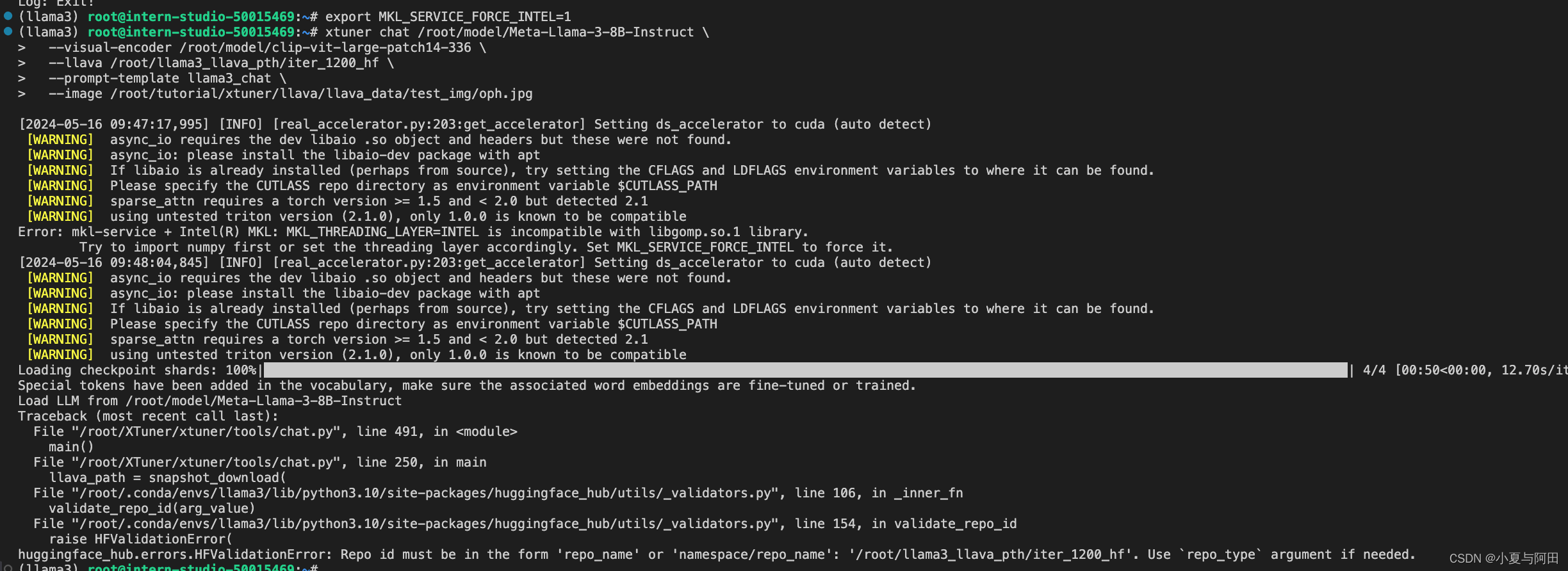
解决办法:升级磁盘,调整训练命令 —--deepspeed deepspeed_zero2_offload
但是使用这个命令会非常慢,4h+
训练好之后,我们将原始 image projector 和 我们微调得到的 image projector 都转换为 HuggingFace 格式,为了下面的效果体验做准备
xtuner convert pth_to_hf ~/Llama3-Tutorial/configs/llama3-llava/llava_llama3_8b_instruct_qlora_clip_vit_large_p14_336_lora_e1_finetune.py \
~/model/llama3-llava-iter_2181.pth \
~/llama3_llava_pth/pretrain_iter_2181_hf
xtuner convert pth_to_hf ~/Llama3-Tutorial/configs/llama3-llava/llava_llama3_8b_instruct_qlora_clip_vit_large_p14_336_lora_e1_finetune.py \
~/llama3_llava_pth/iter_1200.pth \
~/llama3_llava_pth/iter_1200_hfPretrain 模型
export MKL_SERVICE_FORCE_INTEL=1
xtuner chat /root/model/Meta-Llama-3-8B-Instruct \\
--visual-encoder /root/model/clip-vit-large-patch14-336 \\
--llava /root/llama3_llava_pth/pretrain_iter_2181_hf \\
--prompt-template llama3_chat \\
--image /root/tutorial/xtuner/llava/llava_data/test_img/oph.jpg
转换完成后,我们直接在命令行询问一些问题 此时可以看到,Pretrain 模型只会为图片打标签,并不能回答问题。
此时可以看到,Pretrain 模型只会为图片打标签,并不能回答问题。
Finetune 模型
export MKL_SERVICE_FORCE_INTEL=1
xtuner chat /root/model/Meta-Llama-3-8B-Instruct \
--visual-encoder /root/model/clip-vit-large-patch14-336 \
--llava /root/llama3_llava_pth/iter_1200_hf \
--prompt-template llama3_chat \
--image /root/tutorial/xtuner/llava/llava_data/test_img/oph.jpgfinetune后再问同样的问题


此时模型已经可以根据图片回答我们的问题了
五、Llama 3 高效部署实践(LMDeploy 版)
5.1 环境准备
还是跟之前一样,环境已经配置好了,只需要执行conda activate llama3 进行激活
5.2 安装最新的lmdeploy
pip install -U lmdeploy[all]
5.3 Llama3 的下载
进入到Model文件夹(之前已经创建好,无需新建) cd ~/model
软链接 InternStudio 中的模型
ln -s /root/share/new_models/meta-llama/Meta-Llama-3-8B-Instruct ~/model/Meta-Llama-3-8B-Instruct
在终端执行下面的命令
conda activate lmdeploy
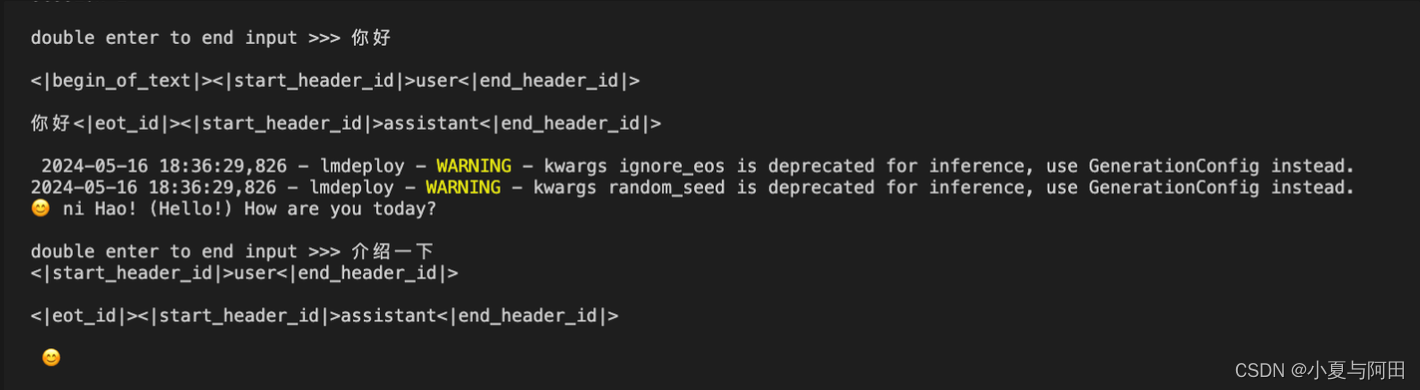
lmdeploy chat /root/model/Meta-Llama-3-8B-Instruct
启动后我们可以直接在命令行测试,问一些问题
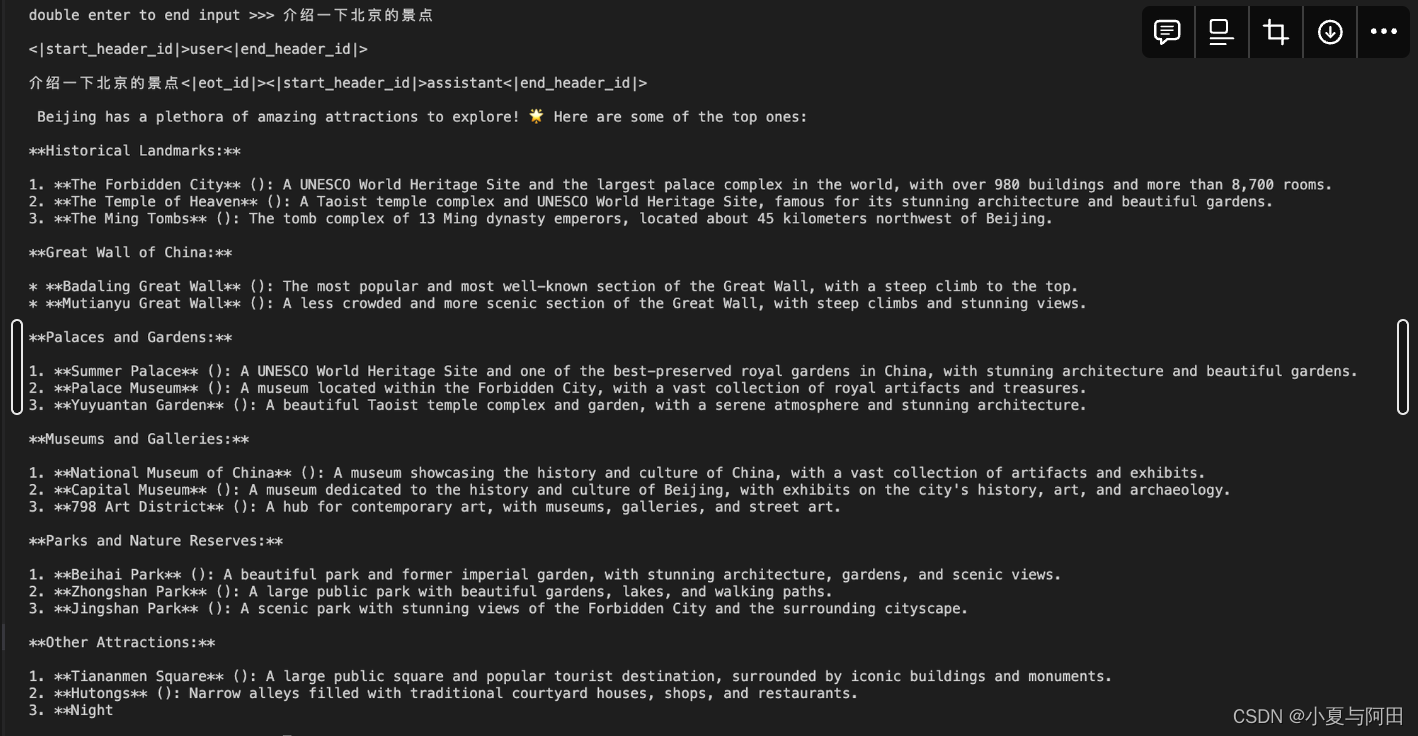
5.4 LMDeploy模型量化(lite)
这一节主要介绍的是如何对模型进行量化。主要包括 KV8量化和W4A16量化。
模型在运行时,占用的显存可大致分为三部分:模型参数本身占用的显存、KV Cache占用的显存,以及中间运算结果占用的显存。LMDeploy的KV Cache管理器可以通过设置--cache-max-entry-count参数,控制KV缓存占用剩余显存的最大比例。默认的比例为0.8。下面通过几个例子,来看一下调整--cache-max-entry-count参数的效果。
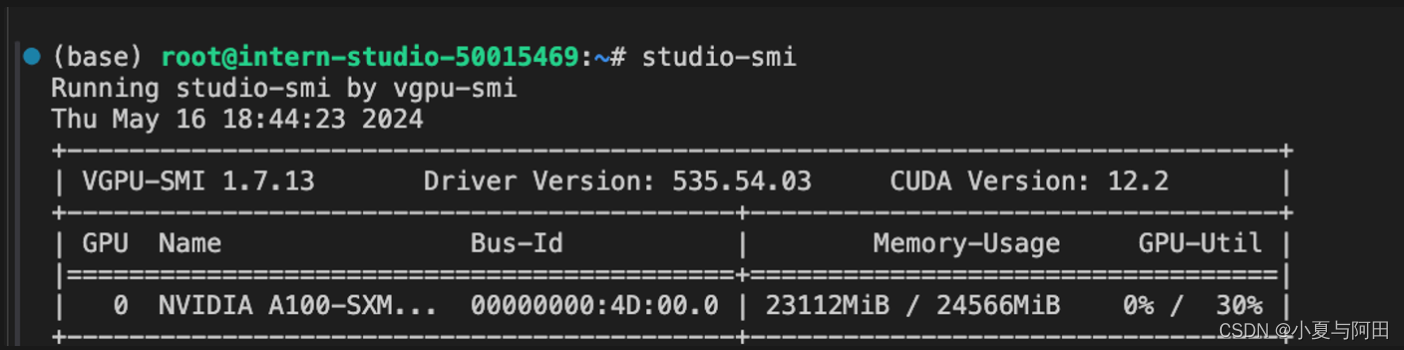
(1)首先保持不加该参数(默认0.8),运行 Llama3-8b 模型。
执行命令
lmdeploy chat /root/model/Meta-Llama-3-8B-Instruct/
新建一个终端执行
studio-smi
时模型占用23112MB
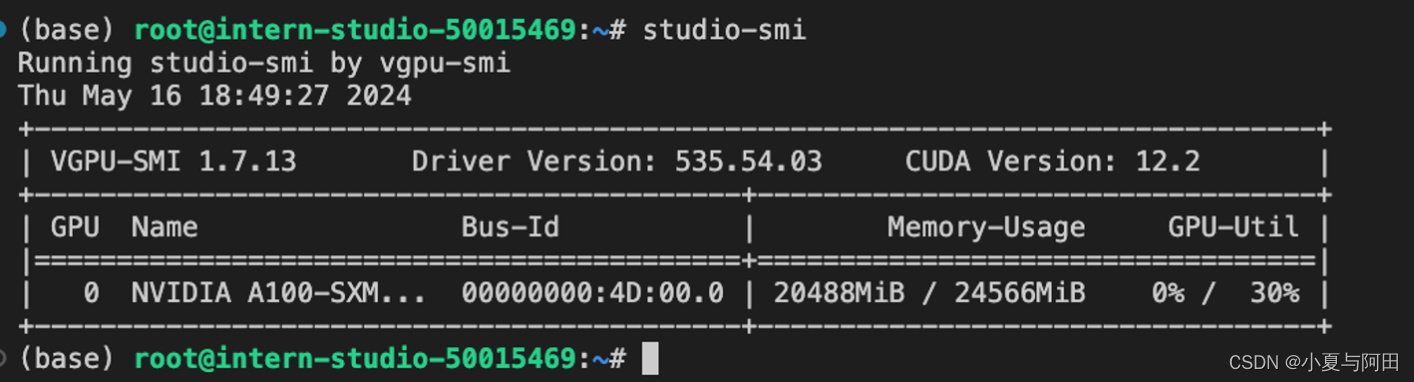
(2)改变--cache-max-entry-count参数,设为0.5。
执行下命令
lmdeploy chat /root/model/Meta-Llama-3-8B-Instruct/ --cache-max-entry-count 0.5
新建终端查看显存占用情况(命令同上)可以看到此时显存存占用降低,为20488MB
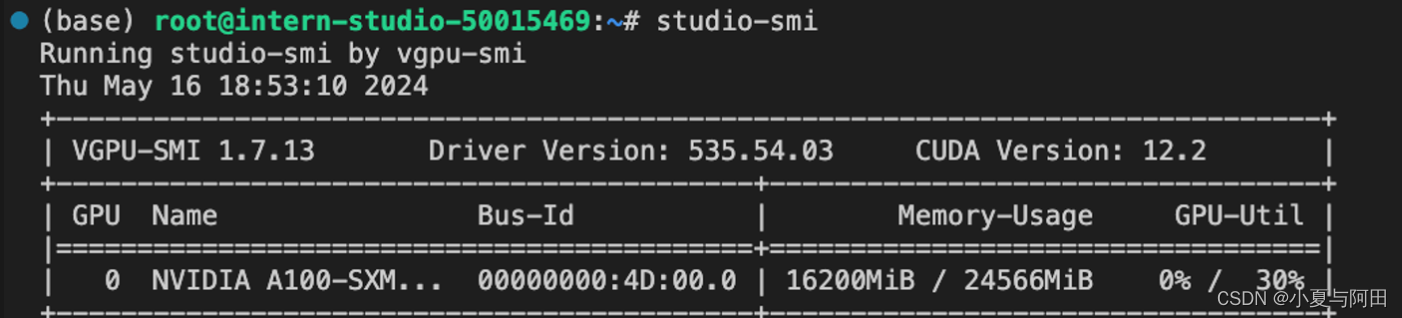
(3)把--cache-max-entry-count参数设置为0.01,约等于禁止KV Cache占用显存
lmdeploy chat /root/model/Meta-Llama-3-8B-Instruct/ --cache-max-entry-count 0.01
新建终端查看显存占用情况(命令同上)可以看到,此时显存占用仅为16176M,代价是会降低模型推理速度。
5.5 使用W4A16量化
完成模型量化需要执行下面的命令
lmdeploy lite auto_awq \\
/root/model/Meta-Llama-3-8B-Instruct \\
--calib-dataset 'ptb' \\
--calib-samples 128 \\
--calib-seqlen 1024 \\
--w-bits 4 \\
--w-group-size 128 \\
--work-dir /root/model/Meta-Llama-3-8B-Instruct_4bit
量化工作结束后,新的HF模型被保存到Meta-Llama-3-8B-Instruct_4bit目录,下面使用Chat功能运行W4A16量化后的模型。
lmdeploy chat /root/model/Meta-Llama-3-8B-Instruct_4bit --model-format awq
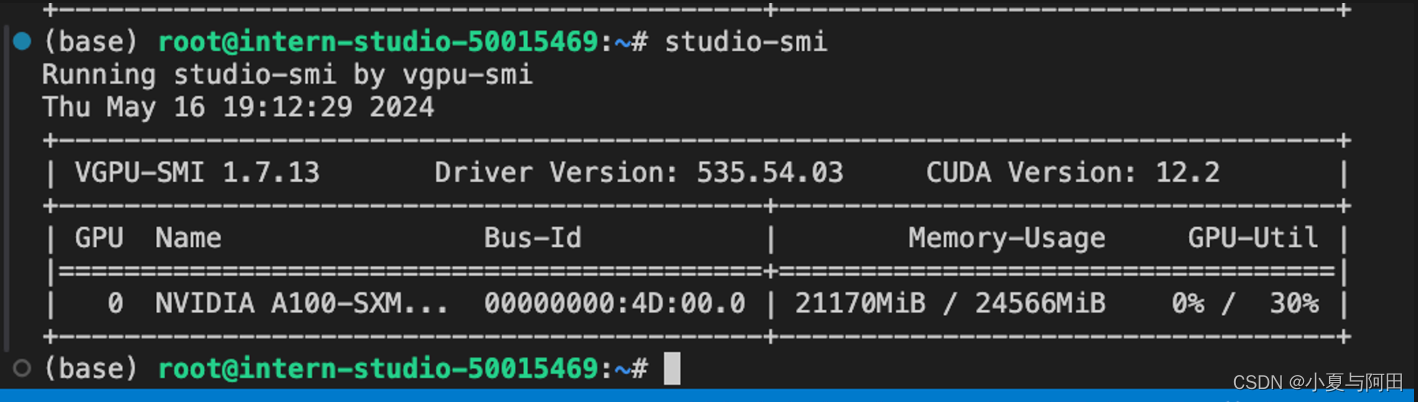
为了更加明显体会到W4A16的作用,我们将KV Cache比例再次调为0.01,查看显存占用情况。
lmdeploy chat /root/model/Meta-Llama-3-8B-Instruct_4bit --model-format awq --cache-max-entry-count 0.01
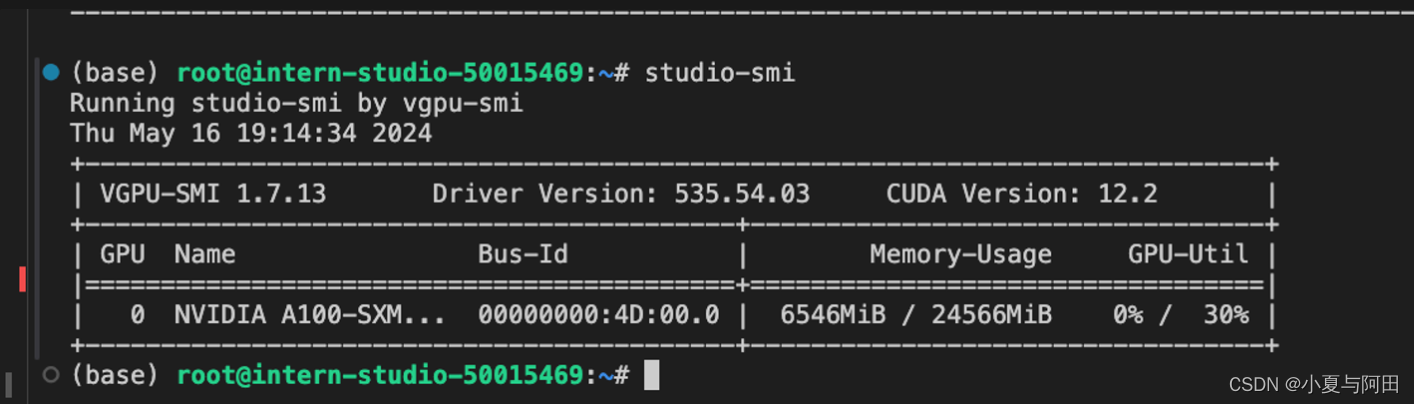
可以看到,显存占用变为6554MB,明显降低。
5.6 LMDeploy服务(serve)
启动api服务器
lmdeploy serve api_server \\
/root/model/Meta-Llama-3-8B-Instruct \\
--model-format hf \\
--quant-policy 0 \\
--server-name 0.0.0.0 \\
--server-port 23333 \\
--tp 1
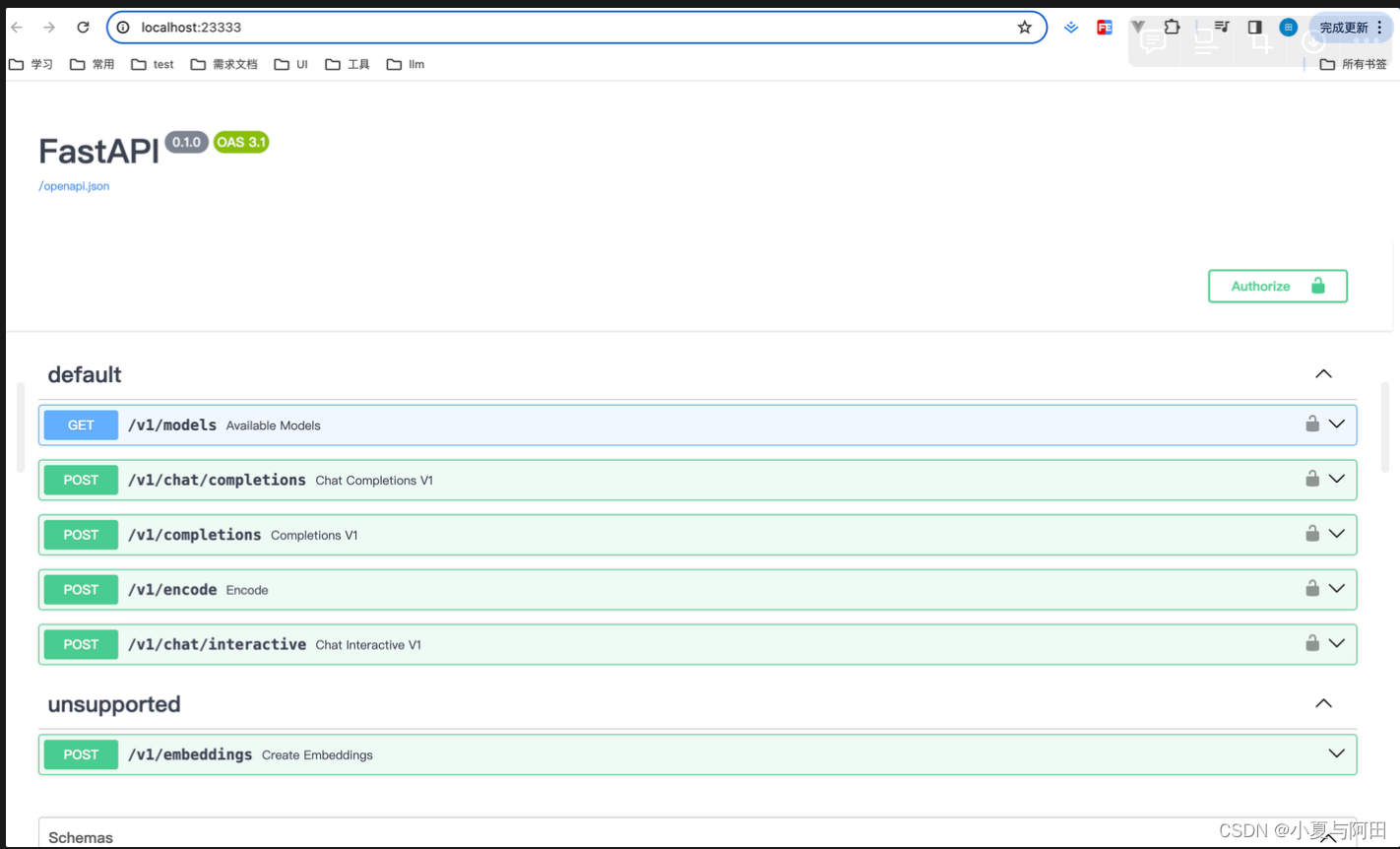
其中,model-format、quant-policy这些参数是与第三章中量化推理模型一致的;server-name和server-port表示API服务器的服务IP与服务端口;tp参数表示并行数量(GPU数量)。 通过运行以上指令,我们成功启动了API服务器,请勿关闭该窗口,后面我们要新建客户端连接该服务。 你也可以直接打开http://{host}:23333查看接口的具体使用说明,如下图所示。
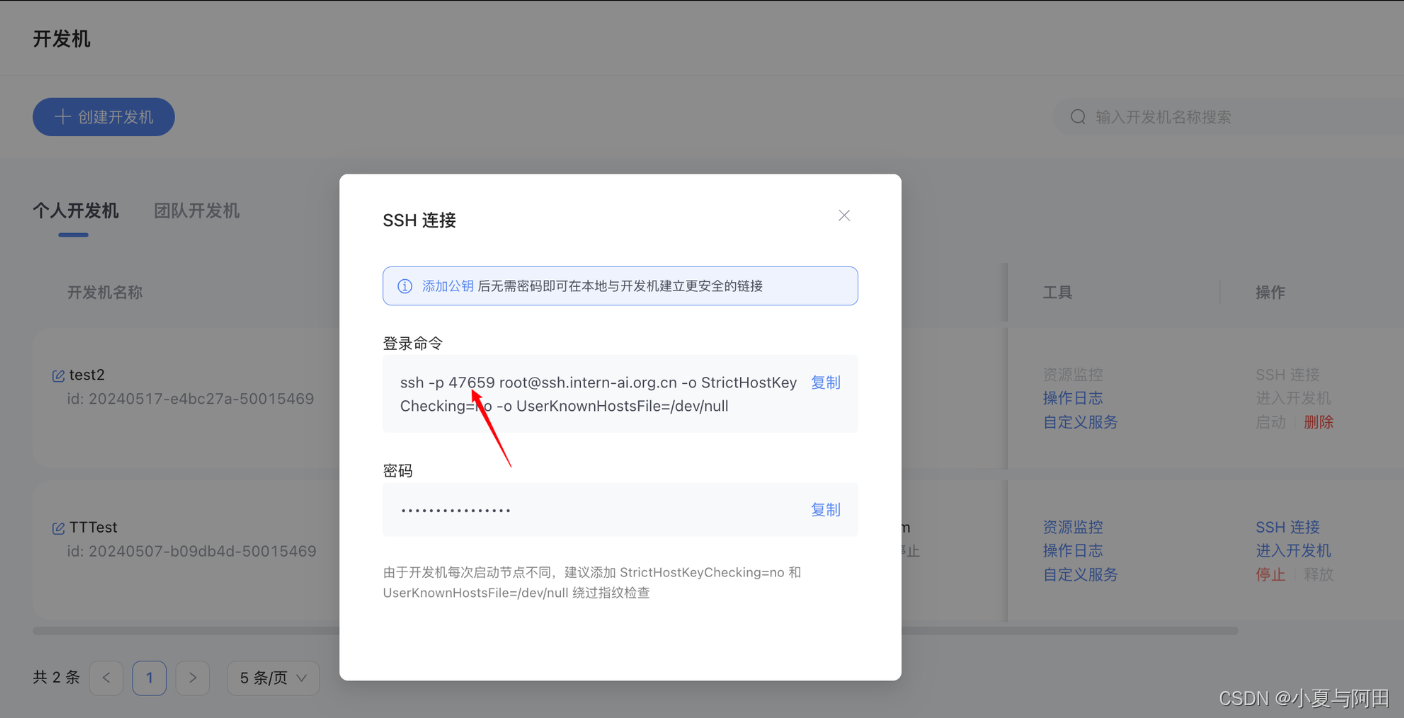
这一步由于Server在远程服务器上,所以本地需要做一下ssh转发才能直接访问,你本地打开一个cmd窗口,输入命令如下
ssh -CNg -L 23333:127.0.0.1:23333 root@ssh.intern-ai.org.cn -p 你的ssh端口号
这个ssh端口号就是连接远程开发机时 登陆命令中的端口号
然后打开浏览器,访问[http://127.0.0.1:23333。](http://127.0.0.1:23333%E3%80%82/)
5.7 命令行客户端连接API服务器
在上一节中,我们在终端里新开了一个API服务器,这次我们要新建一个命令行客户端去连接API服务器。vscode中再建一个终端,然后激活conda环境,运行命令行客户端
lmdeploy serve api_client <http://localhost:23333>
运行后,可以通过命令行窗口直接与模型对话

我们在客户端每次发送对话就可以看到服务端这边会出现一条请求记录
5.8 网页客户端连接API服务器
这次我们要创建一个网页版的客户端与我们启动的服务端连接,关闭我们之前创建的客户端终端,但是服务端的终端不要关闭,运行之前确保自己的gradio版本低于4.0.0
pip install gradio==3.50.2
新建一个VSCode终端,激活conda环境
conda activate lmdeploy
使用Gradio作为前端,启动网页客户端
lmdeploy serve gradio <http://localhost:23333> \\
--server-name 0.0.0.0 \\
--server-port 6006
打开浏览器,访问地址http://127.0.0.1:6006 然后就可以与模型进行对话了
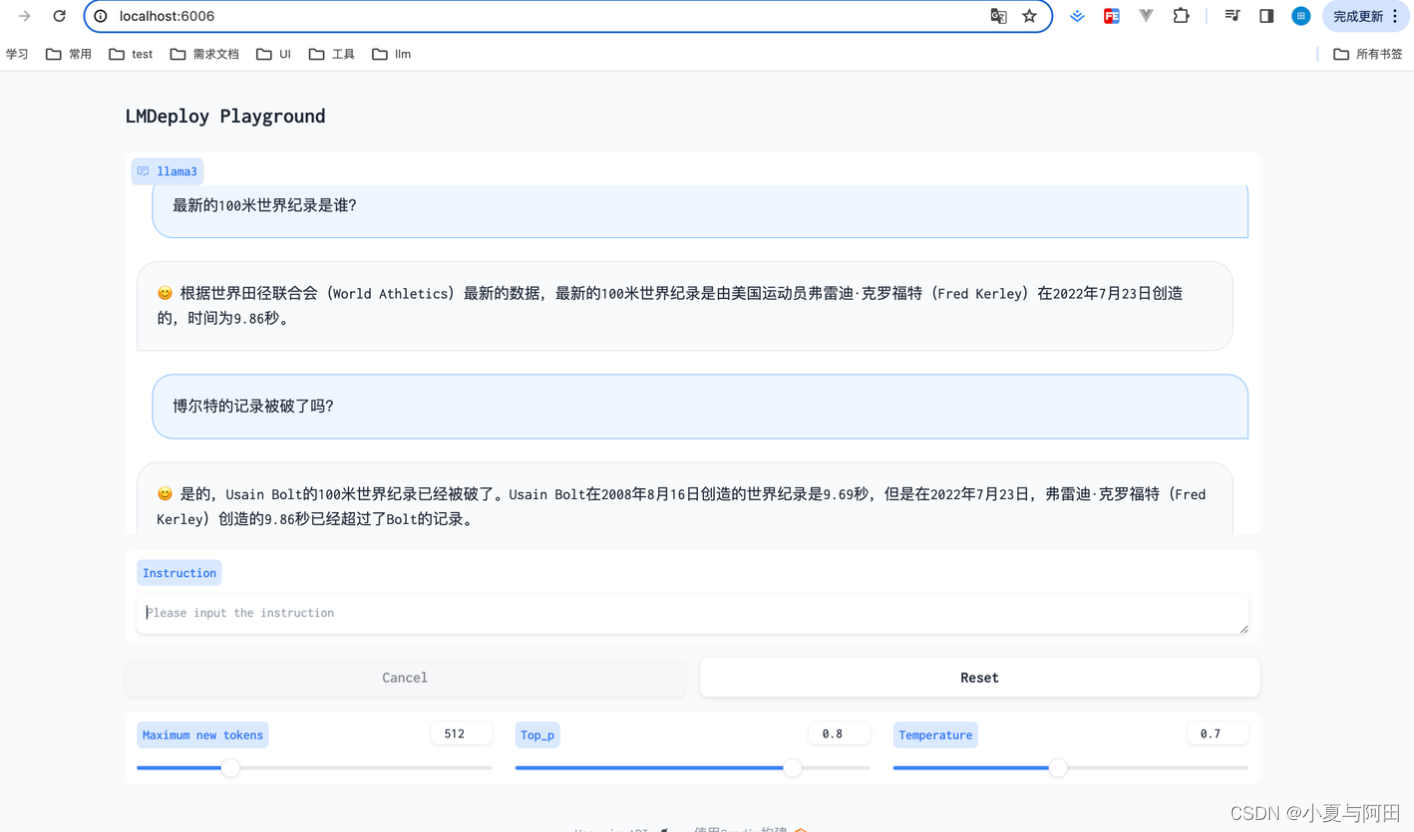
我们也可以看到,在网页上每问一个问题,vscode中的服务端终端都会收到一条请求记录😄















 662
662

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









