







 本文介绍了如何利用Matlab和正则表达式从网页抓取上海市天天快递的所有网点信息,并将数据整理成Excel表格。通过解析网页源代码,匹配特定的HTML标记,提取所需字段,最终生成结构化的Excel文件。需要注意的是,不同Matlab版本可能对中文网页支持情况不同,以及网页字符集和HTML标记的清理等问题。
本文介绍了如何利用Matlab和正则表达式从网页抓取上海市天天快递的所有网点信息,并将数据整理成Excel表格。通过解析网页源代码,匹配特定的HTML标记,提取所需字段,最终生成结构化的Excel文件。需要注意的是,不同Matlab版本可能对中文网页支持情况不同,以及网页字符集和HTML标记的清理等问题。
这次扯个题外话,做这个完全是为帮同学获取快递网点信息
要求:得到上海市天天快递所有网点的信息 title_colum= { '所在地区','公司名称','地址','联系电话','派送范围','Link'};最后要将结果放到Excel中,具体如下

下图是某一个网点的信息
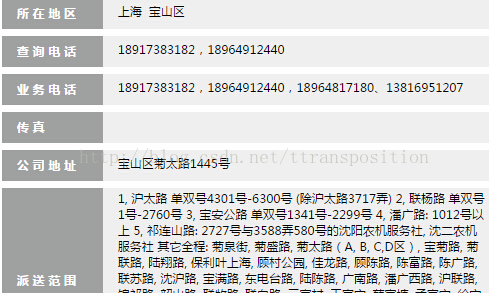
一共有78个网点,链接地址http://www.ttkdex.com/webdistributed/5.html
例如:
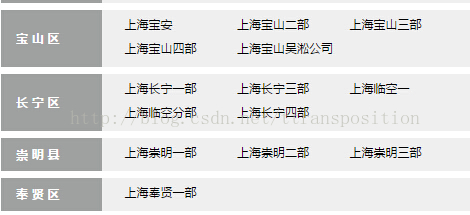
方案:十八般武艺,各显神通,
(1)手工复制:每个网页都得打开一次,复制四五次,还好不是特别多,但是韵达快递就多如牛毛了....
(2)HTML+JS+Active+...&#
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 422
422

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









