







Logistic 回归 概述
Logistic 回归 或者叫逻辑回归虽然名字有回归,但是它是用来做分类的。其主要思想是: 根据现有数据对分类边界线(Decision Boundary)建立回归公式,以此进行分类。
一些概念
Sigmoid 函数
回归 概念
假设现在有一些数据点,我们用一条直线对这些点进行拟合(这条直线称为最佳拟合直线),这个拟合的过程就叫做回归。进而可以得到对这些点的拟合直线方程,那么我们根据这个回归方程,怎么进行分类呢?请看下面。
二值型输出分类函数
我们想要的函数应该是: 能接受所有的输入然后预测出类别。例如,在两个类的情况下,上述函数输出 0 或 1.或许你之前接触过具有这种性质的函数,该函数称为海维塞得阶跃函数(Heaviside step function),或者直接称为单位阶跃函数。然而,海维塞得阶跃函数的问题在于: 该函数在跳跃点上从 0 瞬间跳跃到 1,这个瞬间跳跃过程有时很难处理。幸好,另一个函数也有类似的性质(可以输出 0 或者 1 的性质),且数学上更易处理,这就是Sigmoid函数。 Sigmoid函数具体的计算公式如下:

下图给出了Sigmoid函数在不同坐标尺度下的两条曲线图。当 x 为 0 时,Sigmoid 函数值为 0.5 。随着 x 的增大,对应的 Sigmoid 值将逼近于 1 ; 而随着 x 的减小, Sigmoid 值将逼近于 0 。如果横坐标刻度足够大,Sigmoid函数看起来很像一个阶跃函数。

因此,为了实现 Logistic 回归分类器,我们可以在每个特征上都乘以一个回归系数(如下公式所示),然后把所有结果值相加,将这个总和代入 Sigmoid 函数中,进而得到一个范围在 0~1 之间的数值。任何大于 0.5 的数据被分入 1 类,小于 0.5 即被归入 0 类。所以,Logistic 回归也是一种概率估计,比如这里Sigmoid 函数得出的值为0.5,可以理解为给定数据和参数,数据被分入 1 类的概率为0.5。想对Sigmoid 函数有更多了解,可以点开此链接跟此函数互动。
基于最优化方法的回归系数确定
Sigmoid 函数的输入记为 z ,由下面公式得到:
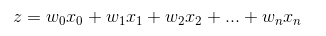
如果采用向量的写法,上述公式可以写成 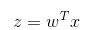 ,它表示将这两个数值向量对应元素相乘然后全部加起来即得到 z 值。其中的向量 x 是分类器的输入数据,向量 w 也就是我们要找到的最佳参数(系数),从而使得分类器尽可能地精确。为了寻找该最佳参数,需要用到最优化理论的一些知识。我们这里使用的是——梯度上升法(Gradient Ascent)。
,它表示将这两个数值向量对应元素相乘然后全部加起来即得到 z 值。其中的向量 x 是分类器的输入数据,向量 w 也就是我们要找到的最佳参数(系数),从而使得分类器尽可能地精确。为了寻找该最佳参数,需要用到最优化理论的一些知识。我们这里使用的是——梯度上升法(Gradient Ascent)。
梯度上升法
梯度的介绍
向量 = 值 + 方向
梯度 = 向量
梯度 = 梯度值 + 梯度方向
梯度上升法的思想
要找到某函数的最大值,最好的方法是沿着该函数的梯度方向探寻。如果梯度记为 ▽ ,则函数 f(x, y) 的梯度由下式表示:
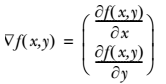
这个梯度意味着要沿 x 的方向移动  ,沿 y 的方向移动
,沿 y 的方向移动 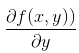 。其中,函数f(x, y) 必须要在待计算的点上有定义并且可微。下图是一个具体的例子。
。其中,函数f(x, y) 必须要在待计算的点上有定义并且可微。下图是一个具体的例子。

上图展示的,梯度上升算法到达每个点后都会重新估计移动的方向。从 P0 开始,计算完该点的梯度,函数就根据梯度移动到下一点 P1。在 P1 点,梯度再次被重新计算,并沿着新的梯度方向移动到 P2 。如此循环迭代,直到满足停止条件。迭代过程中,梯度算子总是保证我们能选取到最佳的移动方向。
上图中的梯度上升算法沿梯度方向移动了一步。可以看到,梯度算子总是指向函数值增长最快的方向。这里所说的是移动方向,而未提到移动量的大小。该量值称为步长,记作 α 。用向量来表示的话,梯度上升算法的迭代公式如下:

该公式将一直被迭代执行,直至达到某个停止条件为止,比如迭代次数达到某个指定值或者算法达到某个可以允许的误差范围。
介绍一下几个相关的概念:
例如:y = w0 + w1x1 + w2x2 + ... + wnxn
梯度:参考上图的例子,二维图像,x方向代表第一个系数,也就是 w1,y方向代表第二个系数也就是 w2,这样的向量就是梯度。
α:上面的梯度算法的迭代公式中的阿尔法,这个代表的是移动步长(step length)。移动步长会影响最终结果的拟合程度,最好的方法就是随着迭代次数更改移动步长。
步长通俗的理解,100米,如果我一步走10米,我需要走10步;如果一步走20米,我只需要走5步。这里的一步走多少米就是步长的意思。
▽f(w):代表沿着梯度变化的方向。
问:有人会好奇为什么有些书籍上说的是梯度下降法(Gradient Decent)?
答: 其实这个两个方法在此情况下本质上是相同的。关键在于代价函数(cost function)或者叫目标函数(objective function)。如果目标函数是损失函数,那就是最小化损失函数来求函数的最小值,就用梯度下降。 如果目标函数是似然函数(Likelihood function),就是要最大化似然函数来求函数的最大值,那就用梯度上升。在逻辑回归中, 损失函数和似然函数无非就是互为正负关系。
只需要在迭代公式中的加法变成减法。因此,对应的公式可以写成
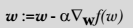
局部最优现象 (Local Optima)

上图表示参数 θ 与误差函数 J(θ) 的关系图 (这里的误差函数是损失函数,所以我们要最小化损失函数),红色的部分是表示 J(θ) 有着比较高的取值,我们需要的是,能够让 J(θ) 的值尽量的低。也就是深蓝色的部分。θ0,θ1 表示 θ 向量的两个维度(此处的θ0,θ1是x0和x1的系数,也对应的是上文w0和w1)。
可能梯度下降的最终点并非是全局最小点,可能是一个局部最小点,如我们上图中的右边的梯度下降曲线,描述的是最终到达一个局部最小点,这是我们重新选择了一个初始点得到的。
看来我们这个算法将会在很大的程度上被初始点的选择影响而陷入局部最小点。
Logistic 回归 原理
Logistic 回归 工作原理
每个回归系数初始化为 1
重复 R 次:
计算整个数据集的梯度
使用 步长 x 梯度 更新回归系数的向量
返回回归系数
Logistic 回归 开发流程
收集数据: 采用任意方法收集数据
准备数据: 由于需要进行距离计算,因此要求数据类型为数值型。另外,结构化数据格式则最佳。
分析数据: 采用任意方法对数据进行分析。
训练算法: 大部分时间将用于训练,训练的目的是为了找到最佳的分类回归系数。
测试算法: 一旦训练步骤完成,分类将会很快。
使用算法: 首先,我们需要输入一些数据,并将其转换成对应的结构化数值;接着,基于训练好的回归系数就可以对这些数值进行简单的回归计算,判定它们属于哪个类别;在这之后,我们就可以在输出的类别上做一些其他分析工作。
Logistic 回归 算法特点
优点: 计算代价不高,易于理解和实现。
缺点: 容易欠拟合,分类精度可能不高。
适用数据类型: 数值型和标称型数据。
附加 方向导数与梯度

Logistic 回归 项目案例
项目概述
在一个简单的数据集上,采用梯度上升法找到 Logistic 回归分类器在此数据集上的最佳回归系数
开发流程
收集数据: 可以使用任何方法
准备数据: 由于需要进行距离计算,因此要求数据类型为数值型。另外,结构化数据格式则最佳
分析数据: 画出决策边界
训练算法: 使用梯度上升找到最佳参数
测试算法: 使用 Logistic 回归进行分类
使用算法: 对简单数据集中数据进行分类
我们采用存储在 TestSet.txt 文本文件中的数据,存储格式如下:
-0.017612 14.053064 0
-1.395634 4.662541 1
-0.752157 6.538620 0
-1.322371 7.152853 0
0.423363 11.054677 0
绘制在图中,如下图所示:

准备数据: 由于需要进行距离计算,因此要求数据类型为数值型。另外,结构化数据格式则最佳
# 解析数据
def loadDataSet(file_name):
'''
Desc:
加载并解析数据
Args:
file_name -- 要解析的文件路径
Returns:
dataMat -- 原始数据的特征
labelMat -- 原始数据的标签,也就是每条样本对应的类别。即目标向量
'''
# dataMat为原始数据, labelMat为原始数据的标签
dataMat = []
labelMat = []
fr = open(file_name)
for line in fr.readlines():
lineArr = line.strip().split()
# 为了方便计算,我们将 X0 的值设为 1.0 ,也就是在每一行的开头添加一个 1.0 作为 X0
dataMat.append([1.0, float(lineArr[0]), float(lineArr[1])])
labelMat.append(int(lineArr[2]))
return dataMat, labelMat
训练算法: 使用梯度上升找到最佳参数
定义sigmoid阶跃函数
# sigmoid阶跃函数
def sigmoid(inX):
# return 1.0 / (1 + exp(-inX))
# Tanh是Sigmoid的变形,与 sigmoid 不同的是,tanh 是0均值的。因此,实际应用中,tanh 会比 sigmoid 更好。
return 2 * 1.0/(1+exp(-2*inX)) - 1
Logistic 回归梯度上升优化算法
# 正常的处理方案
# 两个参数:第一个参数==> dataMatIn 是一个2维NumPy数组,每列分别代表每个不同的特征,每行则代表每个训练样本。
# 第二个参数==> classLabels 是类别标签,它是一个 1*100 的行向量。为了便于矩阵计算,需要将该行向量转换为列向量,做法是将原向量转置,再将它赋值给labelMat。
def gradAscent(dataMatIn, classLabels):
# 转化为矩阵[[1,1,2],[1,1,2]....]
dataMatrix = mat(dataMatIn) # 转换为 NumPy 矩阵
# 转化为矩阵[[0,1,0,1,0,1.....]],并转制[[0],[1],[0].....]
# transpose() 行列转置函数
# 将行向量转化为列向量 => 矩阵的转置
labelMat = mat(classLabels).transpose() # 首先将数组转换为 NumPy 矩阵,然后再将行向量转置为列向量
# m->数据量,样本数 n->特征数
m,n = shape(dataMatrix)
# print m, n, '__'*10, shape(dataMatrix.transpose()), '__'*100
# alpha代表向目标移动的步长
alpha = 0.001
# 迭代次数
maxCycles = 500
# 生成一个长度和特征数相同的矩阵,此处n为3 -> [[1],[1],[1]]
# weights 代表回归系数, 此处的 ones((n,1)) 创建一个长度和特征数相同的矩阵,其中的数全部都是 1
weights = ones((n,1))
for k in range(maxCycles): #heavy on matrix operations
# m*3 的矩阵 * 3*1 的矩阵 = m*1的矩阵
# 那么乘上矩阵的意义,就代表:通过公式得到的理论值
# 参考地址: 矩阵乘法的本质是什么? https://www.zhihu.com/question/21351965/answer/31050145
# print 'dataMatrix====', dataMatrix
# print 'weights====', weights
# n*3 * 3*1 = n*1
h = sigmoid(dataMatrix*weights) # 矩阵乘法
# print 'hhhhhhh====', h
# labelMat是实际值
error = (labelMat - h) # 向量相减
# 0.001* (3*m)*(m*1) 表示在每一个列上的一个误差情况,最后得出 x1,x2,xn的系数的偏移量
weights = weights + alpha * dataMatrix.transpose() * error # 矩阵乘法,最后得到回归系数
return array(weights)
画出数据集和 Logistic 回归最佳拟合直线的函数
def plotBestFit(dataArr, labelMat, weights):
'''
Desc:
将我们得到的数据可视化展示出来
Args:
dataArr:样本数据的特征
labelMat:样本数据的类别标签,即目标变量
weights:回归系数
Returns:
None
'''
n = shape(dataArr)[0]
xcord1 = []; ycord1 = []
xcord2 = []; ycord2 = []
for i in range(n):
if int(labelMat[i])== 1:
xcord1.append(dataArr[i,1]); ycord1.append(dataArr[i,2])
else:
xcord2.append(dataArr[i,1]); ycord2.append(dataArr[i,2])
fig = plt.figure()
ax = fig.add_subplot(111)
ax.scatter(xcord1, ycord1, s=30, c='red', marker='s')
ax.scatter(xcord2, ycord2, s=30, c='green')
x = arange(-3.0, 3.0, 0.1)
"""
y的由来,卧槽,是不是没看懂?
首先理论上是这个样子的。
dataMat.append([1.0, float(lineArr[0]), float(lineArr[1])])
w0*x0+w1*x1+w2*x2=f(x)
x0最开始就设置为1叻, x2就是我们画图的y值,而f(x)被我们磨合误差给算到w0,w1,w2身上去了
所以: w0+w1*x+w2*y=0 => y = (-w0-w1*x)/w2
"""
y = (-weights[0]-weights[1]*x)/weights[2]
ax.plot(x, y)
plt.xlabel('X'); plt.ylabel('Y')
plt.show()
测试算法: 使用 Logistic 回归进行分类
def testLR():
# 1.收集并准备数据
dataMat, labelMat = loadDataSet("data/5.Logistic/TestSet.txt")
# print dataMat, '---\n', labelMat
# 2.训练模型, f(x)=a1*x1+b2*x2+..+nn*xn中 (a1,b2, .., nn).T的矩阵值
# 因为数组没有是复制n份, array的乘法就是乘法
dataArr = array(dataMat)
# print dataArr
weights = gradAscent(dataArr, labelMat)
# weights = stocGradAscent0(dataArr, labelMat)
# weights = stocGradAscent1(dataArr, labelMat)
# print '*'*30, weights
# 数据可视化
plotBestFit(dataArr, labelMat, weights)
使用算法: 对简单数据集中数据进行分类
注意
梯度上升算法在每次更新回归系数时都需要遍历整个数据集,该方法在处理 100 个左右的数据集时尚可,但如果有数十亿样本和成千上万的特征,那么该方法的计算复杂度就太高了。一种改进方法是一次仅用一个样本点来更新回归系数,该方法称为随机梯度上升算法。由于可以在新样本到来时对分类器进行增量式更新,因而随机梯度上升算法是一个在线学习(online learning)算法。与 “在线学习” 相对应,一次处理所有数据被称作是 “批处理” (batch) 。
随机梯度上升算法可以写成如下的伪代码:
所有回归系数初始化为 1
对数据集中每个样本
计算该样本的梯度
使用 alpha x gradient 更新回归系数值
返回回归系数值
以下是随机梯度上升算法的实现代码:
# 随机梯度上升
# 梯度上升优化算法在每次更新数据集时都需要遍历整个数据集,计算复杂都较高
# 随机梯度上升一次只用一个样本点来更新回归系数
def stocGradAscent0(dataMatrix, classLabels):
m,n = shape(dataMatrix)
alpha = 0.01
# n*1的矩阵
# 函数ones创建一个全1的数组
weights = ones(n) # 初始化长度为n的数组,元素全部为 1
for i in range(m):
# sum(dataMatrix[i]*weights)为了求 f(x)的值, f(x)=a1*x1+b2*x2+..+nn*xn,此处求出的 h 是一个具体的数值,而不是一个矩阵
h = sigmoid(sum(dataMatrix[i]*weights))
# print 'dataMatrix[i]===', dataMatrix[i]
# 计算真实类别与预测类别之间的差值,然后按照该差值调整回归系数
error = classLabels[i] - h
# 0.01*(1*1)*(1*n)
print weights, "*"*10 , dataMatrix[i], "*"*10 , error
weights = weights + alpha * error * dataMatrix[i]
return weights
可以看到,随机梯度上升算法与梯度上升算法在代码上很相似,但也有一些区别: 第一,后者的变量 h 和误差 error 都是向量,而前者则全是数值;第二,前者没有矩阵的转换过程,所有变量的数据类型都是 NumPy 数组。
判断优化算法优劣的可靠方法是看它是否收敛,也就是说参数是否达到了稳定值,是否还会不断地变化?下图展示了随机梯度上升算法在 200 次迭代过程中回归系数的变化情况。其中的系数2,也就是 X2 只经过了 50 次迭代就达到了稳定值,但系数 1 和 0 则需要更多次的迭代。如下图所示:

针对这个问题,我们改进了之前的随机梯度上升算法,如下:
# 随机梯度上升算法(随机化)
def stocGradAscent1(dataMatrix, classLabels, numIter=150):
m,n = shape(dataMatrix)
weights = ones(n) # 创建与列数相同的矩阵的系数矩阵,所有的元素都是1
# 随机梯度, 循环150,观察是否收敛
for j in range(numIter):
# [0, 1, 2 .. m-1]
dataIndex = range(m)
for i in range(m):
# i和j的不断增大,导致alpha的值不断减少,但是不为0
alpha = 4/(1.0+j+i)+0.0001 # alpha 会随着迭代不断减小,但永远不会减小到0,因为后边还有一个常数项0.0001
# 随机产生一个 0~len()之间的一个值
# random.uniform(x, y) 方法将随机生成下一个实数,它在[x,y]范围内,x是这个范围内的最小值,y是这个范围内的最大值。
randIndex = int(random.uniform(0,len(dataIndex)))
# sum(dataMatrix[i]*weights)为了求 f(x)的值, f(x)=a1*x1+b2*x2+..+nn*xn
h = sigmoid(sum(dataMatrix[dataIndex[randIndex]]*weights))
error = classLabels[dataIndex[randIndex]] - h
# print weights, '__h=%s' % h, '__'*20, alpha, '__'*20, error, '__'*20, dataMatrix[randIndex]
weights = weights + alpha * error * dataMatrix[dataIndex[randIndex]]
del(dataIndex[randIndex])
return weights
上面的改进版随机梯度上升算法,我们修改了两处代码。
第一处改进为 alpha 的值。alpha 在每次迭代的时候都会调整,这回缓解上面波动图的数据波动或者高频波动。另外,虽然 alpha 会随着迭代次数不断减少,但永远不会减小到 0,因为我们在计算公式中添加了一个常数项。
第二处修改为 randIndex 更新,这里通过随机选取样本拉来更新回归系数。这种方法将减少周期性的波动。这种方法每次随机从列表中选出一个值,然后从列表中删掉该值(再进行下一次迭代)。
程序运行之后能看到类似于下图的结果图。
















 1314
1314











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









