







在上一节的分析中,我们已经对HashMap的内部实现机制有了一定的了解,我们感受到了快速定位对我们效率带来的好处和益处,但是我们不仅在嘀咕,效率是提高了,但是我却发现次序没有,除了能够预知"NULL"键的次序以外(傻瓜都知道在哪),其他的元素的次序我都是不感知的,如何是好,排队总得有个先来后到吧,别着急,我们下面来看一下LinkedHashMap这个类,他会帮我们解决问题的!
console:
-------------------------linked hash map----------------------
1:corey
2:syna
3:bobo
-------------------------hash map----------------------
2:syna
1:corey
3:bobo
从而可见,我们的问题得到了解决;
现在我们从LinkEdHashMap代码内部来详细的分析其实现原理;
在LinkedHashMap中含有一个Entry的属性;注意,这个Entry不是上一次我们在HashMap中见到的单向Entry,他被扩充了:
因为LinkedHashMap是继承的HashMap,那么他们的增删改的操作基本一致,只是利用了模板模式具有了不同的实现;
我们来看一下put方法吧;
下面是HashMap的put方法:
在上一节中我们已经详细的分析过了,在LinkedHashMap中被重载的方法是addEntry;
Header元素在构造的时候被初始化,记得吗,这个方法是HashMap在构造函数中利用模板模式传下来的
开始的时候Header头尾都是指向自身的;

第二步的时候就是被e.addBefore(header);
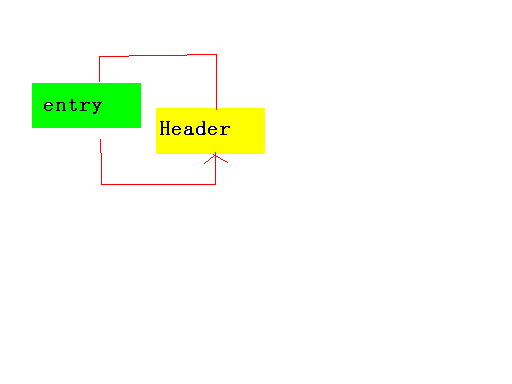
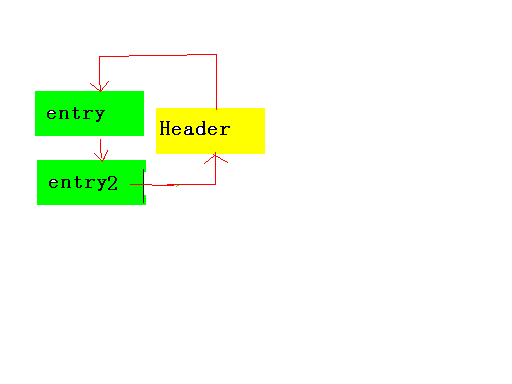
如果再put那么就是:
我们再来看一看他的keySet是如何得到的:
重载了newKeyIterator() 的方法:
我们看一下迭代器是如何实现的:
把next方法抽象出去是因为values和keySet的迭代次序是一样的,就是返回的数值不同,所以可以把
Entry的遍历方式推到上层,而values和keys分别留给子类实现;
这里我个人觉得是处理得十分巧妙的地方;
- package org.corey.demo;
- import java.util.HashMap;
- import java.util.Iterator;
- import java.util.LinkedHashMap;
- import java.util.Map;
- public class Test {
- /**
- * @param args
- */
- public static void main(String[] args) {
- Map map = new LinkedHashMap(4);
- map.put("1", "corey");
- map.put("2", "syna");
- map.put("3", "bobo");
- Iterator it=map.keySet().iterator();
- System.out.println("-------------------------linked hash map----------------------");
- while(it.hasNext()){
- String key=(String)it.next();
- System.out.println(key+":"+map.get(key));
- }
- Map map2 = new HashMap(4);
- map2.put("1", "corey");
- map2.put("2", "syna");
- map2.put("3", "bobo");
- Iterator it2=map2.keySet().iterator();
- System.out.println("-------------------------hash map----------------------");
- while(it2.hasNext()){
- String key=(String)it2.next();
- System.out.println(key+":"+map2.get(key));
- }
- }
- }
-------------------------linked hash map----------------------
1:corey
2:syna
3:bobo
-------------------------hash map----------------------
2:syna
1:corey
3:bobo
从而可见,我们的问题得到了解决;
现在我们从LinkEdHashMap代码内部来详细的分析其实现原理;
- private transient Entry<K,V> header;
- private static class Entry<K,V> extends HashMap.Entry<K,V> {
- //他有两个指针分别指向了before和after的Entry
- //请注意,不要把next和他们混淆了,next的用处还是和HashMap中一//样;
- Entry<K,V> before, after;
- Entry(int hash, K key, V value, HashMap.Entry<K,V> next) {
- super(hash, key, value, next);
- }
- private void remove() {
- before.after = after;
- after.before = before;
- }
- 、
- //在当前节点前面插入节点;
- private void addBefore(Entry<K,V> existingEntry) {
- after = existingEntry;
- before = existingEntry.before;
- before.after = this;
- after.before = this;
- }
- void recordAccess(HashMap<K,V> m) {
- LinkedHashMap<K,V> lm = (LinkedHashMap<K,V>)m;
- if (lm.accessOrder) {
- lm.modCount++;
- remove();
- addBefore(lm.header);
- }
- }
- void recordRemoval(HashMap<K,V> m) {
- remove();
- }
- }
因为LinkedHashMap是继承的HashMap,那么他们的增删改的操作基本一致,只是利用了模板模式具有了不同的实现;
我们来看一下put方法吧;
下面是HashMap的put方法:
- public V put(K key, V value) {
- if (key == null)
- return putForNullKey(value);
- int hash = hash(key.hashCode());
- int i = indexFor(hash, table.length);
- for (Entry<K,V> e = table[i]; e != null; e = e.next) {
- Object k;
- if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
- V oldValue = e.value;
- e.value = value;
- e.recordAccess(this);
- return oldValue;
- }
- }
- modCount++;
- addEntry(hash, key, value, i);
- return null;
- }
- void addEntry(int hash, K key, V value, int bucketIndex) {
- Entry<K,V> e = table[bucketIndex];
- table[bucketIndex] = new Entry<K,V>(hash, key, value, e);
- if (size++ >= threshold)
- resize(2 * table.length);
- }
在上一节中我们已经详细的分析过了,在LinkedHashMap中被重载的方法是addEntry;
- void addEntry(int hash, K key, V value, int bucketIndex) {
- createEntry(hash, key, value, bucketIndex);
- Entry<K,V> eldest = header.after;
- if (removeEldestEntry(eldest)) {
- removeEntryForKey(eldest.key);
- } else {
- if (size >= threshold)
- resize(2 * table.length);
- }
- }
- void createEntry(int hash, K key, V value, int bucketIndex) {
- //和以前一样,首先操作了table序列的链表枝条;
- HashMap.Entry<K,V> old = table[bucketIndex];
- Entry<K,V> e = new Entry<K,V>(hash, key, value, old);
- table[bucketIndex] = e;
- //关键在于这一步做了什么;我们知道他在header之前插入了Entry;
- e.addBefore(header);
- size++;
- }
- void init() {
- header = new Entry<K,V>(-1, null, null, null);
- header.before = header.after = header;
- }
第二步的时候就是被e.addBefore(header);
- private void addBefore(Entry<K,V> existingEntry) {
- after = existingEntry;
- before = existingEntry.before;
- before.after = this;
- after.before = this;
- }
如果再put那么就是:
我们再来看一看他的keySet是如何得到的:
重载了newKeyIterator() 的方法:
- Iterator<K> newKeyIterator() { return new KeyIterator(); }
- private abstract class LinkedHashIterator<T> implements Iterator<T> {
- //从开始的图3我们可见,第一次加入的节点是位于header.after的位置;
- Entry<K,V> nextEntry = header.after;
- Entry<K,V> lastReturned = null;
- int expectedModCount = modCount;
- //nextnEntry不是header就不是末尾
- public boolean hasNext() {
- return nextEntry != header;
- }
- public void remove() {
- if (lastReturned == null)
- throw new IllegalStateException();
- if (modCount != expectedModCount)
- throw new ConcurrentModificationException();
- LinkedHashMap.this.remove(lastReturned.key);
- lastReturned = null;
- expectedModCount = modCount;
- }
- Entry<K,V> nextEntry() {
- if (modCount != expectedModCount)
- throw new ConcurrentModificationException();
- if (nextEntry == header)
- throw new NoSuchElementException();
- //指针沿着after往下走
- Entry<K,V> e = lastReturned = nextEntry;
- //预先把nextEntry移动到了下一位
- nextEntry = e.after;
- return e;
- }
- }
把next方法抽象出去是因为values和keySet的迭代次序是一样的,就是返回的数值不同,所以可以把
Entry的遍历方式推到上层,而values和keys分别留给子类实现;
- private class KeyIterator extends LinkedHashIterator<K> {
- public K next() { return nextEntry().getKey(); }
- }
- private class KeyIterator extends LinkedHashIterator<K> {
- public K next() { return nextEntry().getKey(); }
- }
- private class ValueIterator extends LinkedHashIterator<V> {
- public V next() { return nextEntry().value; }
- }
- private class EntryIterator extends LinkedHashIterator<Map.Entry<K,V>> {
- public Map.Entry<K,V> next() { return nextEntry(); }
- }
这里我个人觉得是处理得十分巧妙的地方;















 2138
2138

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









