







5.1 函数声明
每个函数声明都包含一个名字、一个形参列表、一个可选的返回列表以及函数体:
func name(parameter-list) (result-list) {
body
}
形参列表指定了一组变量的参数名和参数类型,这些局部变量由调用者提供的实参传递而来。返回列表则指定了函数返回值的类型。当函数返回一个未命名的返回值,或者没有返回值的时候,返回列表的圆括号可以省略。如果一个函数既省略返回列表也没有任何返回值,那么设计这个函数的目的是调用函数之后所带来的附加效果。在下面的hypot函数中:
func hypot(x, y float64) float64 {
return math.Sqrt(x*x, y*y)
}
fmt.Println(hypot(3, 4)) // 5
x和y是函数声明中的形参,3和4是调用函数时的实参,并且函数返回一个类型为float64的值。
返回值也可以像形参一样命名。此时,每一个命名的返回值会声明为一个局部变量,并根据变量类型初始化为相应的0值:
package main
import "fmt"
// 定义一个函数,返回两个整数的和与差
func addAndSubtract(a, b int) (sum, diff int) {
// 直接使用命名的返回值进行计算
sum = a + b
diff = a - b
// 函数执行完毕时,这些命名返回值会被隐式返回
return // 无需显式写出 return sum, diff
}
func main() {
// 调用函数并获取返回值
resultSum, resultDiff := addAndSubtract(10, 5)
fmt.Println("Sum:", resultSum)
fmt.Println("Difference:", resultDiff)
}
当函数存在返回列表时,必须显式地以return语句结束,除非函数明确不会走完整个执行流程,比如在函数中抛出宕机异常或者函数体内存在一个没有break退出条件的无限for循环。
在hypot函数中使用到一种简写,如果几个形参或者返回值的类型相同,那么类型只需要写一次。以下两个声明是完全相同的:
func f(i, j, k int, s, t string) { /* ... */ }
func f(i int, j int, k int, s string, t string) { /* ... */ }
下面使用4种方式声明一个带有两个形参和一个返回值的函数,所有变量都是int类型。空白标识符用来强调这个形参在函数中未使用。
func add(x int, y int) int { return x + y }
func sub(x, y int) (z int) { z = x - y; return }
func first(x int, _ int) int { return x }
func zero(int, int) int { return 0 }
fmt.Printf("%T\n", add) // func(int, int) int
fmt.Printf("%T\n", sub) // func(int, int) int
fmt.Printf("%T\n", first) // func(int, int) int
fmt.Printf("%T\n", zero) // func(int, int) int
函数的类型称作函数签名。当两个函数拥有相同的形参列表和返回列表时,认为这两个函数的类型或签名是相同的。而形参和返回值的名字不会影响到函数类型,采用简写同样也不会影响到函数的类型。
每一次调用函数都需要提供实参来对应函数的每一个形参,包括参数的调用顺序也必须一致。Go语言没有默认参数值的概念也不能指定实参名,所以除了用于文档说明之外,形参和返回值的命名不会对调用方有任何影响。
形参变量都是函数的局部变量,初始值由调用者提供的实参传递。函数形参以及命名返回值属于函数最外层作用域的局部变量。
实参是按值传递的,所以函数接收到的是每个实参的副本;修改函数的形参变量并不会影响到调用者提供的实参。然而,如果提供的实参包含引用类型,比如指针、slice、map、函数或者通道,那么当函数使用形参变量时就有可能会间接地修改实参变量。
你可能偶尔会看到有些函数的声明没有函数体,那说明这个函数使用除了Go以外的语言实现。这样的声明定义了该函数的签名。
package math
func Sin(x float64) float64 // 使用汇编语言实现
5.2 递归
函数可以递归调用,这意味着函数可以直接或间接地调用自己。递归是一种实用的技术,可以处理许多带有递归特性的数据结构。在4.4节使用递归实现了对一棵树进行插入排序。本节再一次使用递归处理HTML文件。
下面的代码示例使用了一个非的标准包golang.org/x/net/html,它提供了解析HTML的功能。golang.org/x/…下的仓库(比如网络、国际化语言处理、移动平台、图片处理、加密功能以及开发者工具)都由Go团队负责设计和维护。这些包并不属于标准库,原因是它们还在开发当中,或者很少被Go程序员使用。
我们需要的golang.org/x/net/html API如下面的代码所示。函数html.Parse读入一段字节序列,解析它们,然后返回HTML文档树的根节点html.node。HTML有多种节点,比如文本、注释等。但这里我们只关心表单的元素节点<name key='value'>。
// golang.org/x/net/html
package html
type Node struct {
Type NodeType
Data String
Attr []Attribute
FirstChild, NextSibling *Node
}
type NodeType int32
const (
ErrorNode NodeType = iota
TextNode
DocumentNode
ElementNode
DoctypeNode
)
type Attribute struct {
Key, Val string
}
func Parse(r io.Reader) (*Node, error)
主函数从标准输入中读入HTML,使用递归的visit函数获取HTML文本的超链接,并且把所有的超链接输出。
// gopl.io/ch5/findlinks1
// Findlinks1输出从标准输入中读入的HTML文档中的所有链接
package main
import (
"fmt"
"os"
"golang.org/x/net/html"
)
func main() {
doc, err := html.Parse(os.Stdin)
if err != nil {
fmt.Fprintf(os.Strerr, "findlinks1: %v\n", err)
os.Exit(1)
}
for _, link := range visit(nil, doc) {
fmt.Println(link)
}
}
visit函数遍历HTML树上的所有节点,从HTML锚元素<a href='...'>中得到href属性的内容,将获取到的链接添加到字符串slice,最后返回这个slice:
// visit函数会将n节点中的每个链接添加到结果中
func visit(links []string, n *html.Node) []string {
if n.Type == html.ElementNode && n.Data == 'a' {
for _, a := range n.Attr {
if a.Key == "href" {
links = append(links, a.Val)
}
}
}
for c := n.FirstChild; c != nil; c = c.NextSibling {
links = visit(links, c)
}
return links
}
要对树中的任意节点n进行递归,visit递归地调用自己去访问节点n的所有子节点,并且将访问过的节点保存在FirstChild链表中。
我们在Go的主页运行findlinks,使用管道将本书1.5节完成的fetch程序的输出重定向到findlinks。稍稍修改输出,使之更加简洁。

可以注意到会获取到不同形式的超链接。之后我们将看到如何解析这些地址,并将链接都转换为基于https://golang.org的URL绝对路径。
下一个程序使用递归遍历所有HTML文本中的节点树,并输出树的结构。当递归遇到每个元素时,它都会将元素标签压入栈,然后输出栈。
// gopl.io/ch5/outline
func main() {
doc, err := html.Parse(os.Stdin)
if err != nil {
fmt.Fprintf(os.Stderr, "outline: %v\n", err)
os.Exit(1)
}
outline(nil, doc)
}
func outline(stack []string, n *html.Node) {
if n.Type == html.ElementNode {
stack = append(stack, n.Data) // 把标签压入栈
fmt.Println(stack)
}
for c := n.FirstChild; c != nil; c = c.NextSibling {
outline(stack, c)
}
}
注意一个细节:尽管outline会将元素压栈但并不会出栈。当outline递归调用自己时,被调用的函数会接收到栈的副本(实际是slice的指针)。尽管被调用者可能会对slice进行元素的添加、修改甚至创建新数组的操作,但它并不会修改调用者原来传递的元素,所以当被调函数返回时,调用者的栈依旧保持原样。
注:slice传给一个函数时(假如函数不会返回修改后的slice),类似于传指针,你可以修改它的当前值,但如果你在函数中对其调用append,那么如果底层数组的空间还能容纳新元素,那么会把新元素直接放到当前slice的底层数组里,如果底层数组空间不能容纳新元素,那么会重新分配一个新slice,这个新slice大小一般为原大小的2倍(取决于实现),然后把原slice里的内容移动到新slice里,再把新元素放到新slice里。对于该函数的实参来说,调用后的slice可能是新的,也可能是旧的,但它的len是没有变化的,因此append的内容不能直接访问到。但如果slice不是新的,我们可以通过切片访问到新append的元素(如10个元素,函数中append了一个元素,我们可以通过[:12]访问到最后一个元素)。
以下是https://golang.org页面的outline:


通过outline可以发现,大多数的HTML文档都只会经过几层递归处理,但即使是一些需要复杂递归处理的文档也能轻松应对。
许多编程语言使用固定长度的函数调用栈:大小在64KB到2MB之间。递归的深度会受限于固定长度的栈大小,所以当进行深度递归调用时必须谨防栈溢出。固定长度的栈甚至会造成一定的安全隐患。相比固定长的栈,Go语言的实现使用了可变长度的栈,栈的大小会随着使用而增长,可达到1GB左右的上限,初始值很小。这使得我们可以安全地使用递归而不用担心溢出问题。
练习5.1:改变findlinks程序,使用递归调用visit(而不是循环)遍历n.FirstChild链表。
// 遍历节点树(深度优先)
func Visit(links []string, n *html.Node) []string {
// 如果当前节点为空,递归结束
if n == nil {
return links
}
// 寻找元素节点,并且是a标签的元素节点
if n.Type == html.ElementNode && n.Data == "a" {
// 寻找a标签的链接属性
for _, val := range n.Attr {
if val.Key == "href" {
links = append(links, val.Val)
}
}
}
// 递归
// 进入子节点
links = Visit(links, n.FirstChild)
// 继续下一个兄弟节点
links = Visit(links, n.NextSibling)
return links
}
5.3 多返回值
一个函数能够返回不止一个结果。我们之前已经见过标准包内的许多函数返回两个值,一个期望得到的计算结果与一个错误值,或者一个表示函数调用是否正确的布尔值。下面来看看怎样写一个这样的函数。
下面程序中的findLinks函数有一个小的变化,它将自己发送HTTP请求,因此不再需要运行fetch函数。因为HTTP请求和解析操作可能会失败,所以findLinks声明了两个结果:一个是发现的链接列表,另一个是错误。另外,HTML的解析一般能够修正错误的输入以及构造一个存在错误节点的文档,所以Parse很少失败;通常情况下,出错是由基本的I/O错误引起的:
// gopl.io/ch5/findlinks2
func main() {
for _, url := range os.Args[1:] {
links, err := findLinks(url)
if err != nil {
fmt.Fprintf(os.Stderr, "findlinks2: %v\n", err)
continue
}
for _, link := range links {
fmt.Println(link)
}
}
}
// findLinks发起一个HTTP的GET请求,解析返回的HTML页面,并返回所有链接
func findLinks(url string) ([]string, error) {
resp, err := http.Get(url)
if err != nil {
return nil, err
}
if resp.StatusCode != http.StatusOK {
resp.Body.Close()
return nil, fmt.Errorf("getting %s: %s", url, resp.Status)
}
doc, err := html.Parse(resp.Body)
resp.Body.Close()
if err != nil {
return nil, fmt.Errorf("parsing %s as HTML: %v", url, err)
}
return visit(nil, doc), nil
}
findLinks函数有4个返回语句,每一个语句返回一对值。前3个返回语句将函数从http何html包中获得的错误信息传递给调用者。第一个返回语句中,错误直接返回;第二个返回语句和第三个返回语句则使用fmt.Errorf(参考7.8节)格式上下文信息,并将信息附加到错误中。如果findLinks调用成功,最后一个返回语句将返回链接的slice,且error为空。
我们必须保证resp.Body正确关闭使得网络资源正常释放。即使在发生错误的情况下也必须释放资源。Go语言的垃圾回收机制将回收未使用的内存,但不能指望它会释放未使用的操作系统资源,比如打开的文件以及网络连接。必须显式地关闭它们。
调用多返回值函数时,返回给调用者的是一组值。调用者必须显式地将这些值分配给变量:
links, err := findLinks(url)
如果某个值不被使用,可以将其分配给blank identifier(空标识符):
links, _ := findLinks(url) // 忽略错误
一个函数内部可以将另一个有多返回值的函数调用作为返回值,下面的例子展示了与findLinks有相同功能的函数,两者的区别在于下面的例子先输出参数:
func findLinksLog(url string) ([]string, error) {
log.Printf("findLinks %s", url)
return findLinks(url)
}
当你调用接受多参数的函数时,可以将一个返回多参数的函数调用作为该函数的参数。虽然这很少出现在实际生产代码中,但这个特性在debug时很方便,我们只需要一条语句就可以输出所有的返回值。下面的代码是等价的:
log.Println(findLinks(url))
links, err := findLinks(url)
log.Println(links, err)
准确的变量名可以传达函数返回值的含义。尤其在返回值的类型都相同时,就像下面这样:
func Size(rect image.Rectangle) (width, height int)
func Split(path string) (dir, file string)
func HourMinSec(t time.Time) (hour, minute, second int)
虽然良好的命名很重要,但你也不必为每一个返回值都取一个适当的名字。比如,按照惯例,函数的最后一个bool类型的返回值表示函数是否运行成功,error类型的返回值代表函数的错误信息,对于这些类似的惯例,我们不必思考合适的命名,它们都无需解释。
如果一个函数所有的返回值都有显式的变量名,那么该函数的return语句可以省略操作数。这称之为bare return。
// CountWordsAndImages does an HTTP GET request for the HTML
// document url and returns the number of words and images in it.
func CountWordsAndImages(url string) (words, images int, err error) {
resp, err := http.Get(url)
if err != nil {
return
}
doc, err := html.Parse(resp.Body)
resp.Body.Close()
if err != nil {
err = fmt.Errorf("parsing HTML: %s", err)
return
}
words, images = countWordsAndImages(doc)
return
}
func countWordsAndImages(n *html.Node) (words, images int) { /* ... */ }
按照返回值列表的次序,返回所有的返回值,在上面的例子中,每一个return语句等价于:
return words, images, err
当一个函数有多处return语句以及许多返回值时,bare return可以减少代码的重复,但是使得代码难以被理解。举个例子,如果你没有仔细地审查代码,很难发现前2处return等价于return 0, 0, err(Go会将返回值words和images在函数体的开始处,根据它们的类型,将其初始化为0),最后一处return等价于return words, image, nil。基于以上原因,不宜过度使用bare return。
5.4 错误
在Go中有一部分函数总是能成功运行。比如strings.Contains和strconv.FormatBool函数,对各种可能的输入都做了良好的处理,使得运行时几乎不会失败,除非遇到灾难性的、不可预料的情况,比如运行时的内存溢出。导致这种错误的原因很复杂,难以处理,从错误中恢复的可能性也很低。
还有一部分函数只要输入的参数满足一定条件,也能保证运行成功。比如time.Date函数,该函数将年月日等参数构造成time.Time对象,除非最后一个参数(时区)是nil。这种情况下会引发panic异常。panic异常是来自被调用函数的信号,表示发生了某个已知的bug。一个良好的程序永远不应该发生panic异常。
对于大部分函数而言,永远无法确保能否成功运行。这是因为错误地原因超出了程序员的控制。举个例子,任何进行I/O操作的函数都会面临出现错误的可能,只有没有经验的程序员才会相信读写操作不会失败,即使是简单的读写。因此,当本该可信的操作出乎意料地失败后,我们必须弄清楚导致失败的原因。
在Go的错误处理中,错误是软件包API和应用程序用户界面的一个重要组成部分,程序运行失败仅被认为是几个预期的结果之一。
对于那些将运行失败看作是预期结果之一的函数,它们会返回一个额外的返回值,通常是最后一个,来传递错误信息。如果导致失败的原因只有一个,额外的返回值可以是一个布尔值,通常被命名为ok。比如,cache.Lookup失败的唯一原因是key不存在,那么代码可以按照下面的方式组织:
value, ok := cache.Lookup(key)
if !ok {
// ...cache[key] does not exist...
}
通常,导致失败的原因不止一种,尤其是对I/O操作而言,用户需要了解更多的错误信息。因此,额外的返回值不再是简单的布尔类型,而是error类型。
内置的error是接口类型。我们将在第七章了解接口类型的含义,以及它对错误处理的影响。现在我们只需要明白error类型可能是nil或者non-nil。nil意味着函数运行成功,non-nil表示失败。对于non-nil的error类型,我们可以通过调用error的Error函数或者像下面这样直接输出错误消息:
fmt.Println(err)
fmt.Printf("%v\n", err)
通常,当函数返回non-nil的error时,其他的返回值是未定义的(undefined),这些未定义的返回值应该被忽略。然而,有少部分函数在发生错误时,仍然会返回一些有用的返回值。比如,当读取文件发生错误时,Read函数会返回已读取的字节数和对应的错误值。对于这种情况,正确的处理方式应该是先处理这些不完整的数据,再处理错误。因此对函数的返回值要有清晰的说明,以便于其他人使用。
在Go中,函数运行失败时会返回错误信息,这些错误信息被认为是一种预期的值而非异常(exception),这使得Go有别于那些将函数运行失败看作是异常的语言。虽然Go有各种异常机制,但这些机制仅被使用在处理那些未被预料的错误,即bug,而不是那些在健壮程序中应该被避免的程序错误。对于Go的异常机制我们将在5.9介绍。
Go这样设计的原因是由于对于某个应该在控制流程中处理的错误而言,将这个错误以异常的形式抛出会混乱对错误的描述,这通常会导致一些糟糕的后果。当某个程序错误被当作异常处理后,这个错误会以难以理解的堆栈跟踪信息报告给最终用户,这些信息大都是关于程序结构方面的而不是简单明了的错误消息。
相比之下,Go程序使用通常的控制流机制(比如if和return语句)应对错误,这使得编码人员能更多地关注错误处理。
5.4.1 错误处理策略
当一次函数调用返回错误时,调用者应该选择合适的方式处理错误。根据情况的不同,有很多处理方式,让我们来看看常用的五种方式。
首先,也是最常用的方式是传播错误。这意味着程序中某个子程序的失败,会变成该函数的失败。下面,我们以5.3节的findLinks函数作为例子。如果findLinks对http.Get的调用失败,findLinks会直接将这个HTTP错误返回给调用者:
resp, err := http.Get(url)
if err != nil {
return nil, err
}
当对html.Parse的调用失败时,findLinks不会直接返回html.Parse函数返回的错误,因为它缺少两条重要信息:1.错误发生在解析器中;2.发生错误的url。因此,findLinks构造了一个新的错误信息,既包含了这两项,也包括了底层的解析出错信息。
doc, err := html.Parse(resp.Body)
resp.Body.Close()
if err != nil {
return nil, fmt.Errorf("parsing %s as HTML: %v", url, err)
}
fmt.Errorf函数使用fmt.Sprintf格式化错误信息并返回一个新error值。这样我们就创建了一个新error,这个新error在原error的message的基础上添加了一个前缀信息。当错误最终被程序的main函数处理时,该错误会提供一个清晰的错误原因链,描述了从问题的发生到结束的完整过程,让人想起NASA的事故调查:
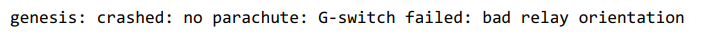
由于错误信息会频繁地链到一起,消息字符串不应该大写并且应该避免换行。最终的错误可能会很长,我们可以通过类似grep的工具处理错误信息。
编写错误信息时,我们要确保错误信息对问题细节的描述是详尽的。尤其是要注意错误信息表达的一致性,即相同的函数或同包内的同一组函数返回的错误在构成和处理方式上是相似的。
以os包为例,os包确保文件操作(如os.Open、Read、Write、Close)返回的每个错误描述不仅仅包含错误地原因(如无权限,文件目录不存在)也包含文件名,这样调用者在构造新的错误信息时无需再添加这些信息。
一般而言,被调用函数f(x)会将调用信息和参数信息作为错误发生时的上下文放在错误信息中并返回给调用者,调用者需要添加一些错误信息中不包含的信息,比如添加url到html.Parse返回的错误中。
让我们来看看处理错误的第二种策略。如果错误的发生是偶然性的,或由不可预知的问题导致的。一个明智的选择是重新尝试失败的操作。在重试时,我们需要限制重试的时间间隔或重试的次数,防止无限制地重试。
// gopl.io/ch5/wait
// WaitForServer attempts to contact the server of a URL.
// It tries for one minute using exponential back-off.
// It reports an error if all attempts fail.
func WaitForServer(url string) error {
const timeout = 1 * time.Minute
deadline := time.Now().Add(timeout)
for tries := 0; time.Now().Begore(deadline); tries++ {
_, err := http.Head(url)
if err == nil {
return nil // sucdess
}
log.Printf("server not responding (%s);retrying...", err)
time.Sleep(time.Second << uint(tries)) // exponential back-off
}
return fmt.Errorf("server %s failed to respond after %s", url, timeout)
}
如果错误发生后,程序无法继续运行,我们就可以采用第三种策略:输出错误信息并结束程序。需要注意的是,这种策略只应在main中执行。对库函数而言,应仅向上传播错误,除非该错误意味着程序内部包含不一致性,即遇到了bug,才能在库函数中结束程序。
// (In function main.)
if err := WaitForServer(url); err != nil {
fmt.Fprintf(os.Stderr, "Site is down: %v\n", err)
os.Exit(1)
}
调用log.Fatalf可以以更简洁的代码达到与上文相同的效果。log中的所有函数,都默认会在错误信息之前输出时间信息。
if err := WaitForServer(url); err != nil {
log.Fatalf("Site is down: %v\n", err)
}
长时间运行的服务器常采用默认的时间格式,而交互式工具很少采用包含如此多信息的格式。

我们可以设置log的前缀信息来屏蔽时间信息,一般而言,前缀信息会被设置成命令名。
log.SetPrefix("wait: ")
log.SetFlags(0)
第四种策略:有时,我们只需要输出错误信息就足够了,不需要中断程序的运行。我们可以通过log包提供的函数:
if err := Ping(); err != nil {
// log.Printf函数将格式化后的字符串输出到标准日志(通常是控制台)
log.Printf("ping failed: %v; networking disabled", err)
}
或者标准错误流输出错误信息。
if err := Ping(); err != nil {
fmt.Fprintf(os.Stderr, "ping failed: %v; networking disabled\n", err)
}
第五种,也是最后一种策略:我们可以直接忽略掉错误。
// 在第一个参数指定的目录内(空表示$TMPDIR)创建一个以第二个参数scratch为前缀的临时目录
dir, err := ioutil.TempDir("", "scratch")
if err != nil {
return fmt.Errorf("failed to create temp dir: %v", err)
}
// ...use temp dir...
os.RemoveAll(dir) // ignore errors; $TMPDIR is cleaned periodically
尽管os.RemoveAll可能会失败,但上面的例子并没有做错误处理。这是因为操作系统会定期地清理临时目录。正因如此,虽然程序没有处理错误,但程序的逻辑不会因此受到影响。我们应该在每次函数调用后,都养成考虑错误处理的习惯,当你决定忽略某个错误时,你应该清晰地写下你的意图。
在Go中,错误处理有一套独特的编码风格。检查某个子函数是否失败后,我们通常将处理失败的逻辑代码放在处理成功的代码之前。如果某个错误会导致函数返回,那么成功时的逻辑代码不应放在else语句块中,而应直接放在函数体中。Go中大部分函数的代码结构几乎相同,首先是一系列的初始检查,防止错误发生,之后是函数的实际逻辑。
5.4.2 文件结尾错误(EOF)
函数经常会返回多种错误,对程序而言,这使得情况变得复杂。很多时候,程序必须根据错误类型,作出不同的响应。让我们考虑这样一个例子:从文件中读取n个字节。如果n等于文件的长度,读取过程的任何错误都表示失败。如果n小于文件的长度,调用者会重复地读取固定大小的数据直到文件结束。这会导致调用者必须分别处理由文件结束引起的各种错误。基于这样的原因,io包保证任何由文件结束引起的读取失败都返回同一个错误——io.EOF,该错误定义在io包中:
package io
import "errors"
// EOF is the error returned by Read when no more input is available.
var EOF = errors.New("EOF")
调用者只需通过简单的比较,就可以检测出这个错误。下面的例子展示了如何从标准输入中读取字符,以及判断文件结束。
in := bufio.NewReader(os.Stdin)
for {
r, _, err := in.ReadRune()
if err == io.EOF {
break // finished reading
}
if err != nil {
return fmt.Errorf("read failed: %v", err)
}
// ...use r...
}
因为文件结束这种错误不需要更多的描述,所以io.EOF有固定的错误信息——“EOF”。对于其他错误,我们可能需要在错误信息中描述错误的类型和数量,这使得我们不能像io.EOF一样采用固定的错误信息。在7.11节中,我们会提出更系统的方法区分某些固定的错误值。
5.5 函数值
在Go中,函数被看作第一类值(first-class values):函数像其他值一样,拥有类型,可以被赋值给其他变量,传递给函数,从函数返回。对函数值(function value)的调用类似函数调用。例子如下:
func square(n int) int { return n * n }
func negative(n int) int { return -n }
func product(m, n int) int { return m * n }
f := square
fmt.Println(f(3)) // 9
f = negative
fmt.Println(f(3)) // -3
fmt.Printf("%T\n", f) // func(int, int) int
f = product // compile error: can't assign func(int, int) int to func(int) int
函数类型的零值是nil。调用值为nil的函数值会引发panic错误:
var f func(int) int
f(3) // 此处f的值为nil,会引起panic错误
函数值可以与nil比较:
var f func(int) int
if f != nil {
f(3)
}
但是函数值之间是不可比较的,也不能用函数值作为map的key。
函数值使得可以将函数的行为当作参数进行传递。标准库中包含许多这样的例子。下面的代码展示了如何使用这个技巧。strings.Map对字符串中的每个字符调用add1函数,并将每个add1函数的返回值组成一个新的字符串返回给调用者。
func add1(r rune) rune { return r + 1 }
fmt.Println(strings.Map(add1, "HAL-9000")) // "IBM.:111"
fmt.Println(strings.Map(add1, "VMS")) // "WNT"
fmt.Println(strings.Map(add1, "Admix")) // "Benjy"
5.3节的findLinks函数使用了辅助函数visit,遍历和操作了HTML页面的所有节点。使用函数值,我们可以将遍历节点的逻辑和操作节点的逻辑分离,使得我们可以复用遍历的逻辑,从而对节点进行不同的操作。
// gopl.io/ch5/outline2
// forEachNode针对每个节点x,都会调用pre(x)和post(x)
// pre和post都是可选的
// 遍历孩子节点之前,pre被调用
// 遍历孩子节点之后,post被调用
func forEachNode(n *html.Node, pre, post func(n *html.Node)) {
if pre != nil {
pre(n)
}
for c := n.FirstChild; c != nil; c = c.NextSibling {
forEachNode(c, pre, post)
}
if post != nil {
post(n)
}
}
该函数接收两个函数作为参数,分别在节点的孩子被访问前和访问后调用。这样的设计给调用者更大的灵活性。举个例子,现在我们有startElement和endElement两个函数用于输出HTML元素的开始标签和结束标签<b>...</b>:
var depth int
func startElement(n *html.Node) {
if n.Type == html.ElementNode {
fmt.Printf("%*s<%s>\n", depth*2, "", n.Data)
depth++
}
}
func endElement(n *html.Node) {
if n.Type == html.ElementNode {
depth--
fmt.Printf("%*s</%s>\n", depth*2, "", n.Data)
}
}
上面的代码利用fmt.Printf的一个小技巧控制输出的缩进。%*s中的*会在字符串之前填充一些空格。在例子中,每次输出会先填充depth*2数量的空格,再输出"",最后再输出HTML标签。
如果我们想下面这样调用forEachNode:
forEachNode(doc, startElement, endElement)
与之前的outline程序相比,我们得到了更加详细的页面结构:

练习5.9:编写函数expand,将s中的“foo”替换为f(“foo”)的返回值:
package main
import (
"fmt"
"strings"
)
func main() {
fmt.Println(expand("fooabcfoodeffoo", f))
}
func expand(s string, f func(string) string) string {
ans := ""
pre := 0
replace := f("foo")
idx := 0
for idx < len(s) {
i := strings.Index(s[idx:], "foo")
if i == -1 {
ans += s[pre:]
break
} else {
ans += s[pre:idx+i] + replace
idx += i + 3
pre = idx
}
}
return ans
}
func f(s string) string {
return "1"
}
运行它:

5.6 匿名函数
命名函数只能在包级别的作用于进行声明,但我们能够使用函数字面量在任何表达式内指定函数变量。函数字面量就像函数声明,但在func关键字后没有函数的名称。它是一个表达式,它的值称作匿名函数。
函数字面量在我们需要使用的时候才定义。就像下面这个例子,之前的函数调用strings.Map可以写成:
strings.Map(func(r rune) rune { return r + 1 }, "HAL-9000")
更重要的是,以这种方式定义的函数能够获取到整个词法环境,因此里层的函数可以使用外层函数中的变量,如下面这个示例所示:
package main
import "fmt"
// squares函数返回一个匿名函数
// 该匿名函数每次被调用时都会返回下一个数的平方
func squares() func() int {
var x int
return func() int {
x++
return x * x
}
}
func main() {
f := squares()
fmt.Println(f()) // 1
fmt.Println(f()) // 4
fmt.Println(f()) // 9
fmt.Println(f()) // 16
}
函数squares返回了另一个函数,类型是func() int。调用squares创建了一个局部变量x而且返回了一个匿名函数,每次调用squares都会递增x的值然后返回x的平方。第二次调用squares函数将创建第二个变量x,然后返回一个递增x值的新匿名函数。
这个求平方的示例演示了函数变量不仅是一段代码还可以拥有状态。里层的匿名函数能够获取和更新外层squares函数的局部变量。这些隐藏的变量引用就是我们把函数归类为引用类型而且函数变量无法进行比较的原因。函数变量类似于使用闭包方法实现的变量,Go程序员通常把函数变量称为闭包。
我们再一次看到这个例子里面变量的生命周期不是由它的作用域所决定的:变量x在main中返回squares函数后依旧存在(虽然x在这个时候是隐藏在函数变量f中的)。
在下面这个与学术课程相关的匿名函数例程中,考虑学习计算机科学课程的顺序,每个课程都有前置课程,只有完成了前置课程才可以开始当前课程的学习。先决课程在下面的prereqs表中已经给出,其中给出了学习每一门课程必须提前完成的课程列表关系。
// prereqs记录了每个课程的前置课程
var prereqs = map[string][]string{
"algorithms": {"data structures"},
"calculus": {"linear algebra"},
"compilers": {
"data structures",
"formal languages",
"computer organization",
},
"data structures": {"discrete math"},
"databases": {"data structures"},
"discrete math": {"intro to programming"},
"formal languages": {"discrete math"},
"networks": {"operating systems"},
"operating systems": {"data structures", "computer organization"},
"programming languages": {"data structures", "computer organization"},
}
这样的问题是我们熟知的拓扑排序。概念上,先决条件的内容构成一张有向图,每一个节点代表一门课程,每一条边代表一门课程所依赖另一门课程的关系。图是无环的:没有节点可以通过图上的路径回到它自己。我们可以使用深度优先搜索算法计算得到合法的学习路径,如以下代码所示:
func main() {
for i, course := range topoSort(prereqs) {
fmt.Printf("%d:\t%s\n", i+1, course)
}
}
func topoSort(m map[string][]string) []string {
var order []string
seen := make(map[string]bool)
var visitAll func(items []string)
visitAll = func(items []string) {
for _, item := range items {
if !seen[item] {
seen[item] = true
visitAll(m[item])
order = append(order, item)
}
}
}
var keys []string
for key := range m {
keys = append(keys, key)
}
sort.Strings(keys)
visitAll(keys)
return order
}
当一个匿名函数需要进行递归,在这个例子中,必须先声明一个变量然后将匿名函数赋给这个变量。如果将两个步骤合并成一个声明,函数字面量将不能存在于visitAll变量的作用域中,这样也就不能递归地调用自己了。
visitAll := func(items []string) {
// ...
visitAll(m[item]) // compile error: undefind: visitAll
// ...
}
下面是拓扑排序的程序输出。它是确定的结果,而确定的结果并不总是免费获得的。在这里,prereqs的值都是slice而不是map,所以它们的迭代顺序是确定的并且我们在调用最初的visitAll之前将prereqs的键值进行了排序。

回到findLinks例子。由于在第8章还需要用到它,因此我们将解析链接的函数移动到了links包下,并将函数重命名为Extract。新的匿名函数被引入,用于替换原来的visit函数。该匿名函数负责将新链接添加到切片中。在Extract中,使用forEachNode遍历HTML页面,由于Extract只需要在遍历节点前操作节点,所以forEachNode的post参数被传入nil。
// gopl.io/ch5/links
// link包提供了解析链接的函数
package links
import (
"fmt"
"net/http"
"golang.org/x/net/html"
)
// Extract makes an HTTP GET request to the specified URL, parses
// the response as HTML, and returns the links in the HTML document.
func Extract(url string) ([]string, error) {
resp, err := http.Get(url)
if err := nil {
return nil, err
}
if resp.StatusCode != http.StatusOK {
resp.Body.Close()
return nil, fmt.Errorf("getting %s: %s", url, resp.Status)
}
doc, err := html.Parse(resp.body)
resp.Body.Close()
if err != nil {
return nil, fmt.Errorf("parsing %s as HTML: %v", url, err)
}
var links []string
visitNode := func(n *html.Node) {
if n.Type == html.ElementNode && n.Data == "a" {
for _, a := range n.Attr {
if a.Key != "href" {
continue
}
link, err := resp.Request.URL.Parse(a.Val)
if err != nil {
continue // ignore bad URLs
}
links = append(links, link.String())
}
}
}
forEachNode(doc, visitNode, nil)
return links, nil
}
上面的代码对之前的版本做了改进,现在links中存储的不是href属性的原始值,而是通过resp.Request.URL解析后的值。解析后,这些连接以绝对路径的形式存在,可以直接被http.Get访问。
网页抓取的核心问题就是如何遍历图。在topoSort的例子中,已经展示了深度优先遍历,在网页抓取中,我们会展示如何用广度优先遍历图。在第8章,我们会介绍如何将深度优先和广度优先结合使用。
下面的函数实现了广度优先算法。调用者需要输入一个初始的待访问列表和一个函数f。待访问列表中的每个元素被定义为string类型。广度优先算法会为每个元素调用一次f。每次f执行完毕后,会访问一组待访问元素。这些元素会被加入到待访问列表中。当待访问列表中的所有元素都被访问后,breadthFirst函数运行结束。为了避免同一个元素被访问两次,代码中维护了一个map。
// gopl.io/ch5/findlinks3
// breadthFirst calls f for each item in the worklist.
// Any items returned by f are added to the worklist.
// f is called at most once for each item.
func breadthFirst(f func(item string) []string, worklist []string) {
seen := make(map[string]bool)
for len(worklist) > 0 {
items := worklist
worklist = nil
for _, item := range items {
if !seen[item] {
seen[item] = true
worklist = append(wordlist, f(item)...)
}
}
}
}
就像我们在章节3解释的那样,append的参数f(item)...,会将f返回的一组元素一个个添加到worklist中。
在我们网页抓取器中,元素是url。crawl函数会将URL输出,提取其中的新链接,并将这些新链接返回。我们会将crawl作为参数传递给breadthFirst。
func crawl(url string) []string {
fmt.Println(url)
list, err := links.Extract(url)
if err != nil {
log.Print(err)
}
return list
}
为了使抓取器开始运行,我们用命令行输入的参数作为初始的待访问url。
func main() {
// Crawl the web breadth-first,
// starting from the command-line arguments.
breadthFirst(crawl, os.Args[1:])
}
让我们从https://golang.org开始,下面是程序的输出结果:

当所有发现的链接都已经被访问或电脑的内存耗尽时,程序运行结束。
5.6.1 警告:捕获迭代变量
本节,将介绍Go词法作用域的一个陷阱。请务必仔细阅读,弄清楚问题发生的原因。即使是经验丰富的程序员也会在这个问题上犯错误。
考虑这样一个问题:你被要求首先创建一些目录,再将目录删除。在下例中我们用函数值来完成删除操作。下例需要引入os包。为了使代码简单,我们忽略了所有异常处理。
var rmdirs []func()
for _, d := range tempDirs() {
dir := d // NOTE: necessary!
// 创建一个路径为dir的目录,整个路径中不存在的目录会被创建
os.MkdirAll(dir, 0755) // creates parent directories too
rmdirs = append(rmdirs, func() {
// 删除dir以及dir中的内容
os.RemoveAll(dir)
})
}
// ...do some work...
for _, rmdir := range rmdirs {
rmdir() // clean up
}
你可能会感到困惑,为什么要在循环体中用循环变量d赋值一个新的局部变量,而不是像下面的代码一样直接使用循环变量dir。需要注意,下面的代码是错误的。
var rmdirs []func()
for _, dir := range tempDirs() {
os.MkdirAll(dir, 0755)
rmdirs = append(rmdirs, func() {
os.RemoveAll(dir) // NOTE: incorrect!
})
}
问题的原因在于循环变量的作用域。在上面的程序中,for循环语句引入了新的词法块,循环变量dir在这个词法块中被声明。在该循环中生成的所有函数值都共享相同的循环变量。需要注意,函数值中记录的是循环变量的内存地址,而不是循环变量某一时刻的值。以dir为例,后续的迭代会不断地更新dir的值,当删除操作执行时,for循环已完成,dir中存储的值等于最后一次迭代的值。这意味着,每次对os.RemoveAll的调用删除的都是相同的目录。
通常,为了解决这个问题,我们会引入一个与循环变量同名的局部变量,作为循环变量的副本。比如下面的变量dir,虽然这看起来有些奇怪,但很有用。
for _, dir := range tempDirs() {
dir := dir // declares inner dir, initialized to outer dir
// ...
}
这个问题不仅存在于基于range的循环中,在下例中,对循环变量i的使用也存在同样的问题:
var rmdirs []func()
dirs := tempDirs()
for i := 0; i < len(dirs); i++ {
os.MkdirAll(dirs[i], 0755) // OK
rmdirs = append(rmdirs, func() {
os.RemoveAll(dirs[i]) // NOTE: incorrect!
})
}
如果你使用go语句(第八章)或者defer语句(5.8节)会经常遇到此类问题。这不是go或defer本身导致的,而是因为它们都会等循环结束后,再执行函数值。
5.7 可变参数
参数数量可变的函数称为可变参数函数。典型的例子就是fmt.Printf和类似函数。Printf首先接收一个必备的参数,之后接收任意个数的后续参数。
在声明可变参数函数时,需要在参数列表的最后一个参数类型前加上省略号...,这表示该函数会接收任意数量的该类型参数。
// gopl.io/ch5/sum
func sum(vals ...int) int {
total := 0
for _, val := range vals {
total += val
}
return total
}
sum函数返回任意个int型参数的和。在函数体中,vals被看作是类型为[]int的切片。sum可以接收任意数量的int型参数:
fmt.Println(sum()) // 0
fmt.Println(sum(3)) // 3
fmt.Println(sum(1, 2, 3, 4)) // 10
在上面的代码中,调用者隐式创建一个数组,并将原始参数赋值到数组中,再把数组的一个切片作为参数传给被调用函数。如果原始参数已经是切片类型,我们该如何传递给sum?只需在最后一个参数后加上省略号。下面代码的功能与上例中最后一条语句相同。
values := []int{1, 2, 3, 4}
fmt.Println(sum(values...)) // 10
虽然在可变参数函数内部,...int型参数的行为看起来很像切片类型,但实际上,可变参数函数和以切片作为参数的函数是不同的。
func f(...int) {}
func g([]int) {}
fmt.Printf("%T\n", f) // func(...int)
fmt.Printf("%T\n", g) // func([]int)
可变参数函数经常被用于格式化字符串。下面的errorf函数构造了一个以行号开头的,经过格式化的错误信息。函数名的后缀f是一种通用的命名规范,代表该可变参数函数可以接收Printf风格的格式化字符串。
func errorf(linenum int, format string, args ...interface[]) {
fmt.Fprintf(os.Stderr, "Line %d: ", linenum)
fmt.Fprintf(os.Stderr, format, args...)
// fmt.Fprintln会在最后输出换行
fmt.Fprintln(os.Stderr)
}
linenum, name := 12, "count"
errorf(linenum, "undefined: %s", name) // Line 12: undefined: count
interface{}表示函数的最后一个参数可以接收任意类型,我们会在第七章介绍。
5.8 Deffered函数
在findLinks的例子中,我们用http.Get的输出作为html.Parse的输入。只有url的内容的确是HTML格式的,html.Parse才可以正常工作,实际上,url指向的内容很丰富,可能是图片,纯文本或其他。将这些格式传递给html.Parse,会产生不良后果。
下例获取HTML页面并输出页面的标题。title函数会检查服务器返回的Content-Type字段,如果发现页面不是HTML,将终止函数的运行,返回错误:
// gopl.io/ch5/title1
func title(url string) error {
resp, err := http.Get(url)
if err != nil {
return err
}
// Check Content-Type is HTML (e.g., "text/html;charset=utf-8").
ct := resp.Header.Get("Content-Type")
if ct != "text/html" && !strings.HasPrefix(ct, "text/html;") {
resp.Body.Close()
return fmt.Errorf("%s has type %s, not text/html", url, ct)
}
doc, err := html.Parse(resp.Body)
resp.Body.Close()
if err != nil {
return fmt.Errorf("parsing %s as HTML: %v", url, err)
}
visitNode := func(n *html.Node) {
if n.Type == html.ElementNode && n.Data == "title" && n.FirstChild != nil {
fmt.Println(n.FirstChild.Data)
}
}
forEachNode(doc, visitNode, nil)
return nil
}
运行它,运行结果进行了折行以便显示:
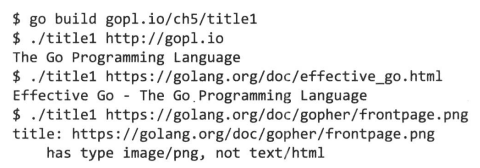
resp.Body.Close调用了多次,这是为了确保title在所有执行路径下(即使函数运行失败了)都关闭了网络连接。随着函数变得复杂,需要处理的错误也变多,维护清理逻辑变得越来越困难。而Go语言独有的defer机制可以让事情变得简单。
你只需要在调用普通函数或方法前加上关键字defer,就完成了defer所需要的语法。当执行到该条语句时,函数和参数表达式得到计算,但直到包含该defer语句的函数执行完毕时,defer后的函数才会被执行,不论包含defer语句的函数是通过return正常结束,还有由于panic导致的异常结束。你可以在一个函数中执行多条defer语句,它们的执行顺序与声明顺序相反。
defer语句经常用于处理成对的操作,如打开、关闭,连接、断开连接,加锁、释放锁。通过defer机制,不论函数逻辑多复杂,都能保证在任何执行路径下,资源被释放。释放资源的defer应该直接跟在请求资源的语句后。在下面的代码中,一条defer语句替代了之前所有的resp.Body.Close。
// gopl.io/ch5/title2
func title(url string) error {
resp, err := http.Get(url)
if err != nil {
return err
}
defer resp.Body.Close()
ct := resp.Header.Get("Content-Type")
if ct != "text/html" && !strings.HasPrefix(ct, "text/html;") {
return fmt.Errorf("%s has type %s, not text/html", url, ct)
}
doc, err := html.Parse(resp.Body)
if err != nil {
return fmt.Errorf("parsing %s as HTML: %v", url, err)
}
// ...print doc's title element...
return nil
}
在处理其他资源时,也可以采用defer机制,比如对文件的操作:
// io/ioutil
package ioutil
func ReadFile(filename string) ([]byte, error) {
f, err := os.Open(filename)
if err != nil {
return nil, err
}
defer f.Close()
return ReadAll(f)
}
或是互斥锁(9.2章):
var mu sync.Mutex
var m = make(map[string]int)
func lookup(key string) int {
mu.Lock()
defer mu.Unlock()
return m[key]
}
调试复杂程序时,defer机制也常用于记录何时进入和退出函数。下例的bigSlowOperation函数,直接调用trace记录函数的被调情况。bigSlowOperation被调时,trace会返回一个函数值,该函数值会在bigSlowOperation退出时被调用。通过这种方式,我们可以只通过一条语句控制函数的入口和所有出口,甚至可以记录函数的运行时间,如下例中的start。需要注意一点:不要忘记defer函数后的圆括号,否则本该在进入时执行的操作会在退出时执行,而本该在退出时执行的,永远不会执行。
// gopl.io/ch5/trace
func bigSlowOperation() {
defer trace("bigSlowOperation")() // don't forget the extra parentheses
// ...lots of work...
time.Sleep(10 * time.Second) // simulates slow operation by sleeping
}
func trace(msg string) func() {
start := time.Now()
log.Printf("enter %s", msg)
return func() {
log.Printf("exit %s (%s)", msg, time.Since(start))
}
}
每一次bigSlowOperation被调用,程序都会记录函数的进入、退出、持续时间。

我们知道,defer语句中的函数会在return语句后再执行,又因为在函数中定义的匿名函数可以访问该函数包括返回值在内的所有变量,所以,对匿名函数采用defer机制,可以使其观察函数返回值。
以double函数为例:
func double(x int) int {
return x + x
}
我们只需要首先命名double的返回值,再增加defer语句,我们就可以在double每次被调用时,输出参数以及返回值。
func double(x int) (result int) {
defer func() { fmt.Printf("double(%d) = %d\n", x, result) })()
return x + x
}
_ = double(4)
// Output:
// "double(4) = 8"
可能double函数过于简单,看不出这个小技巧的作用,但对于有很多return语句的函数而言,这个技巧很有用。
被延迟执行的匿名函数甚至可以修改函数返回给调用者的返回值:
func triple(x int) (result int) {
defer func() { result += x }()
return double(x)
}
fmt.Println(triple(4)) // "12"
在循环体中的defer语句要特别注意,因为只有在函数执行完毕后,这些被延迟的函数才会执行。下面的代码将导致系统的文件描述符耗尽,因为在所有文件都被处理前,没有文件会被关闭。
for _, filename := range filenames {
f, err := os.Open(filename)
if err != nil {
return err
}
defer f.Close() // NOTE: risky; could run out of file descriptors
// ...process f...
}
一种解决方法是将循环体中的defer移到另一个函数。每次循环时,调用这个函数。
for _, filename := range filenames {
if err := doFile(finename); err != nil {
return err
}
}
func doFile(filename string) error {
f, err := os.Open(filename)
if err != nil {
return err
}
defer f.Close()
// ...process f...
}
下面的代码是fetch(1.5节)的改进版,我们将http响应信息写入本地文件而不是从标准输出流输出。我们通过path.Base提出url路径的最后一段作为文件名。
// gopl.io/ch5/fetch
// Fetch downloads the URL and returns the
// name and length of the local file.
func fetch(url string) (filename string, n int64, err error) {
resp, err := http.Get(url)
if err != nil {
return "", 0, err
}
defer resp.Body.Close()
// resp.Request.URL.Path是请求url的路径部分
// path.Base获取/分隔的最后一个元素
// 如果path只有一个/,则返回"/"
// 如果path为空,则返回"."
local := path.Base(resp.Request.URL.Path)
if local == "/" {
local = "index.html"
}
f, err := os.Create(local)
if err != nil {
return "", 0, err
}
n, err = io.Copy(f, resp.Body)
// Close file, but prefer error from Copy, if any.
if closeErr := f.Close(); err == nil {
err = closeErr
}
return local, n, err
}
对resp.Body.Close的延迟调用我们已经见过了,在此不做解释。上例中,通过os.Create打开文件进行写入,在关闭文件时,我们没有对f.close采用defer机制,因为这会产生一些微妙的错误。许多文件系统,尤其是NFS,写入文件时发生的错误会被延迟到文件关闭时反馈。如果没有检查文件关闭时的反馈信息,可能会导致数据丢失,而我们还误以为写入操作成功。如果io.Copy和f.Close都失败了,我们倾向于将io.Copy的错误信息反馈给调用者,因为它先于f.Close发生,更有可能接近问题的本质。
5.9 Panic异常(宕机)
Go的类型系统会在编译时捕获很多错误,但有些错误只能在运行时检查,如数组访问越界、空指针引用等。这些运行时错误会引起painic异常。
一般而言,当panic异常发生时,程序会中断运行,并立即执行在该goroutine(可以先理解成线程,在第8章会详细介绍)中被延迟的函数(defer机制)。随后,程序崩溃并输出日志信息。日志信息包括panic value和函数调用的堆栈跟踪信息。panic value通常是某种错误信息。对于每个goroutine,日志信息中都会有与之相对的,发生panic时的函数调用堆栈信息。通常,我们不需要再次运行程序去定位问题,日志信息已经提供了足够的诊断依据。因此,在我们填写问题报告时,一般会将panic异常和日志信息一并记录。
不是所有的panic异常都来自运行时,直接调用内置的panic函数也会引发panic异常;panic函数接受任何值作为参数。当某些不应该发生的场景发生时,我们就应该调用panic。比如,当程序到达了某条逻辑上不可能到达的路径:
switch s := suit(drawCard()); s {
case "Spades": // ...
case "Hearts": // ...
case "Diamonds": // ...
case "Clubs": // ...
default:
panic(fmt.Sprintf("invalid suit %q", s)) // Joker?
}
断言函数必须满足的前置条件时明智的做法,但这很容易被滥用。除非painc能提供更多的错误信息,或者让你能更快速地发现错误,否则运行时进行panic断言检测是没意义的:
func Reset(x *Buffer) {
if x == nil {
panic("x is nil") // unnecessary!
}
s.elements = nil
}
虽然Go的panic机制类似于其他语言的异常,但panic的使用场景有一些不同。由于panic会引起程序的崩溃,因此panic一般用于严重错误,如程序内部的逻辑不一致。勤奋的程序员认为任何崩溃都表明代码中存在漏洞,所以对于大部分漏洞,我们应该使用Go提供的错误机制,而不是panic,尽量避免程序的崩溃。在健壮的程序中,任何可以预料到的错误,如不正确的输入、错误的配置或是失败的I/O操作都应该被优雅地处理,最好的处理方式,就是使用Go的错误机制。
考虑regexp.Compile函数,该函数将正则表达式编译成有效的可匹配格式。当输入的正则表达式不合法时,该函数会返回一个错误。当调用者明确地知道某个输入不会引起函数错误时,要求调用者检查这个错误是不必要和累赘的。我们应该假设函数的输入是合法的,就如前面的断言一样:当调用者输入了不应该出现的输入时,触发panic异常。
在程序中,大多数正则表达式是字符串字面值(string literals),regexp包提供了一个包裹函数regexp.MustCompile,该包裹函数替调用者做了前面所说的检查,即调用者输入了不合法的正则表达式时,调用panic:
package regexp
func Compile(expr string) (*Regexp, error) { /* ... */ }
func MustCompile(expr string) *Regexp {
re, err := Compile(expr)
if err != nil {
panic(err)
}
return re
}
包装函数使得调用者可以便捷地用一个编译后的正则表达式为包级别的变量赋值:
// 以下正则表达式中,^表示以http开头
// ?表示有一个或零个s
var httpSchemeRE = regexp.MustCompile(`^https?:`) // "http:" or "https:"
显然,MustCompile不能接收不合法的输入。函数名中的Must前缀是一种针对此类函数的命名约定,比如template.Must(4.6节)。
func main() {
f(3)
}
func f(x int) {
fmt.Printf("f(%d)\n", x+0/x) // panics if x == 0
defer fmt.Printf("defer %d\n", x)
f(x - 1)
}
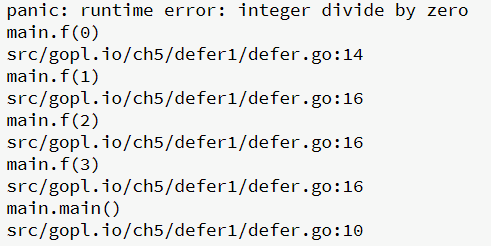
上例的运行输出如下:

当f(0)被调用时,发生panic异常,之前被延迟执行的3个fmt.Printf被调用。程序中断执行后,panic信息和堆栈信息会被输出(下面是简化的输出):
我们下一节将看到如何从panic异常中恢复,阻止程序的崩溃。
为了方便诊断问题,runtime包允许程序员输出堆栈信息。在下例中,我们通过在main函数中延迟调用printStack输出堆栈信息。
// gopl.io/ch5/defer2
func main() {
defer printStack()
f(3)
}
func printStack() {
var buf[4096]byte
n := runtime.Stack(buf[:], false)
os.Stdout.Write(buf[:n])
}
printStack的简化输出如下(只是printStack的输出,不包括panic的日志信息):
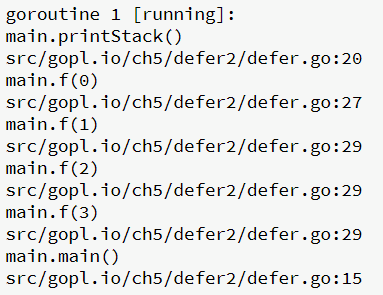
将panic机制类比其他语言异常机制的读者可能会惊讶,runtime.Stack为何能输出已经被释放的函数堆栈信息?在Go的panic机制中,延迟函数的调用在释放堆栈信息前。
5.10 Recover捕获异常
通常来说,不应该对panic异常做任何处理,但有时我们希望从异常中恢复,至少让我们可以在程序崩溃前做一些操作。举个例子,当web服务器遇到不可预料的严重问题时,在崩溃前至少应将所有连接关闭(进程关闭不会自动关闭连接吗?);如果不做任何处理,会使客户端一直处于等待状态。如果web服务器还在开发阶段,服务器甚至可以将异常信息反馈到客户端,帮助调试。
如果在deferred函数中调用了内置函数recover,并且定义该defer语句的函数发生了panic异常,recover会使程序从panic中恢复,并返回panic value。导致panic异常的函数不会继续运行,但能正常返回。在未发生panic时调用recover,recover会返回nil。
让我们以语言解析器为例,说明recover的使用场景。考虑到语言解析器的复杂性,即使某个语言解析器目前工作正常,也无法肯定它没有漏洞。因此,当某个异常出现时,我们不会选择让解析器崩溃,而是会将panic异常当做普通的解析错误,并附加额外信息提醒用户报告此错误。
func Parse(input string) (s *Syntax, err error) {
defer func() {
if p := recover(); p != nil {
err = fmt.Errorf("internal error: %v", p)
}
}()
// ...parser...
}
recover函数帮助Parse从panic中恢复。在deferred函数内部,panic value被附加到错误信息中;并用err变量接收错误信息,返回给调用者。我们也可以通过调用runtime.Stack往错误信息中添加完整的堆栈调用信息。
不加区分地恢复所有的panic异常,不是可取的做法;因为在panic之后,无法保证包级变量的状态仍然和我们预期的一致。比如,对数据结构的一次重要更新没有被完整完成、文件或者网络连接没有被关闭、获得的锁没有被释放。此外,如果写日志时产生的panic被不加区分地恢复,可能会导致漏洞被忽略。
虽然把对panic的处理都集中在一个包下,有助于简化对复杂和不可预料问题的处理,但作为被广泛遵守的规范,你不应该去恢复其他包引起的panic。公有API应该将函数的运行失败作为error返回,而不是panic。同样地,你也不应恢复一个由他人开发的函数引起的panic,比如说调用者传入的回调函数,因为你无法保证这样做是安全的。
有时我们很难完全遵循规范,举个例子,net/http包中提供了一个web服务器,将收到的请求分发给用户提供的处理函数。很显然,我们不能因为某个处理函数引发的panic异常,杀掉整个进程;web服务器遇到处理函数导致的panic时会调用recover,输出堆栈信息,继续运行。这样的做法在实践中很便捷,但也会引起资源泄露,或是因为recover操作,导致其他问题。
基于以上原因,安全的做法是有选择地recover。换句话说,只恢复应该被恢复的异常,此外,这些异常所占比例应尽可能低。为了标识某个panic是否应该被恢复,我们可以将panic value设置成特殊类型。在recover时对panic value进行检查,如果发现panic value是特殊类型,就将这个panic作为error处理,如果不是,则按照正常的panic进行处理(如下例)。
下例是title函数的变形,如果HTML页面包含多个<title>,该函数会给调用者返回一个错误(error)。在soleTitle内部处理时,如果检测到有多个<title>,会调用panic,阻止函数继续递归,并将错误类型bailout作为panic的参数。
// soleTitle returns the text of the first non-empty title element
// in doc, and an error if there was not exactly one.
func soleTitle(doc *html.Node) (title string, err error) {
type bailout struct{}
defer func() {
switch p := recover(); p {
case nil: // no panic
case bailout{}: // "expected" panic
err = fmt.Errorf("miltiple title elements")
default:
panic(p) // unexpected panic; carry on panicking
}
}()
// Bail out of recursion if we find more than one nonempty title.
forEachNode(doc, func(n *html.Node) {
if n.Type == html.ElementNode && n.Data == "title" && n.FirstChild != nil {
if title != "" {
panic(bailout{}) // miltiple title elements
}
title = n.FirstChild.Data
}
}, nil)
if title == "" {
return "", fmt.Errorf("no title element")
}
return title, nil
}
在上例中,deferred函数调用recover,并检查panic value。当panic value是bailout{}时,deferred函数生成一个error返回给调用者。当panic value是其他non-nil值时,表示发生了未知的panic异常,deferred函数将调用panic函数并将当前的panic value作为参数传入;此时,等同于recover没有做任何操作。(注意,上例中,对可预期的错误采用了panic,这违反了之前的建议,在此只是想向读者演示这种机制)
有些情况下, 我们无法恢复。某些致命错误会导致Go在运行时终止程序,如内存不足。















 904
904

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









