







 本文详细介绍了如何使用快慢指针判断链表是否为环形链表,以及如何找到环形链表中的入环结点。通过实例分析不同步长情况下相遇条件,并提供了两种OJ解题思路:一是利用环形链表的特性重新构造相交链表,二是直接在原链表上操作,避免修改链表结构。
本文详细介绍了如何使用快慢指针判断链表是否为环形链表,以及如何找到环形链表中的入环结点。通过实例分析不同步长情况下相遇条件,并提供了两种OJ解题思路:一是利用环形链表的特性重新构造相交链表,二是直接在原链表上操作,避免修改链表结构。
目录
前言
单链表带环是链表中比较经典的问题,重要是推导和证明
一、什么是环形链表?
链表中最后节点的next不是链接到NULL,而是链接到该链表中任一节点包括自己



二、如何判断链表是否是环形链表呢
我们这里运用到了快慢指针
思路:
slow走一步,fast走两步,如果没有环,fast在会NULL或者是fast->next为NULL就结束(取决于链表的长度),有环fast和slow就会相遇
三种情况:
- fast进环(在环入口),slow走了一半
- slow进环(在环入口),fast已经在环内走了一段路(这里取决于环的长度,可能走了几圈了,可能一圈都没有走完)
- fast开始追击slow,直到最后相遇



1. 假设slow刚进环时,fast与slow之间的距离为N,环的长度为C
- slow每次走1步,fast每次走2步,一定可以相遇吗?
- slow每次走1步,fast每次走3步,一定可以相遇吗?
- slow每次走1步,fast每次走4步,一定可以相遇吗?
2.slow每次走1步,fast每次走2步,一定可以相遇吗?
每次追击,fast和slow的距离就在减1,N,N-1,N-2,…,0,最后一定能相遇
所以这种情况一定能相遇


3.slow每次走1步,fast每次走3步,一定可以相遇吗?
每次追击,fast和slow距离就减2,就需要对N分情况
(1) N是偶数,N-2,N-4,N-6,…,0,那就可以相遇
(2) N是奇数,N-2,N-4,N-6,…,1,-1。-1的意思是fast刚好超过了slow1步,现在fast就需要追C-1的长度,相当于C-1 = N,现在能否相遇就取决于C的长度
- 如果C-1是
偶数,就可以相遇 - 如果C-1是
奇数,就永远不会相遇,因为C-1是奇数,fast追击还是会超1步,陷入死循环了,永远都超slow1步

4.slow每次走1步,fast每次走4步,一定可以相遇吗?
每次追击,fast和slow距离就减3,就需要对N分情况
(1)N是3的倍数,N-3,N-6,N-9,…,0,那就可以相遇
(2)N不是3的倍数,需要对fast和slow相差的步数分情况
- 最后fast超slow1步,C-1 = N,就是C-1必须要是3的倍数,才能相遇,否则永远不相遇
- 最后fast超slow2步,C-2 = N,就是C-2必须要是3的倍数,才能相遇,否则永远不相遇
总结:只有slow走1步,fast走2步,每步差距为1的情况下,一定能相遇,其他情况每步差距 > 1,取决于N(fast和slow相差的距离)和C(环的长度)。
四、OJ:环形链表 I
OJ链接
思路:
通过快慢指针,slow走1步,fast走2步,是环形链表两个指针一定能相遇,fast=NULL或fast->next=NULL,就不是环形链表
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* struct ListNode *next;
* };
*/
bool hasCycle(struct ListNode *head) {
struct ListNode* slow, *fast;
slow = fast = head;
// 快慢指针
while (fast && fast->next)
{
slow = slow->next;
fast = fast->next->next;
// 相遇的话就是环形链表
if (fast == slow)
return true;
}
// 循环走完了,就说明不是环形链表
return false;
}
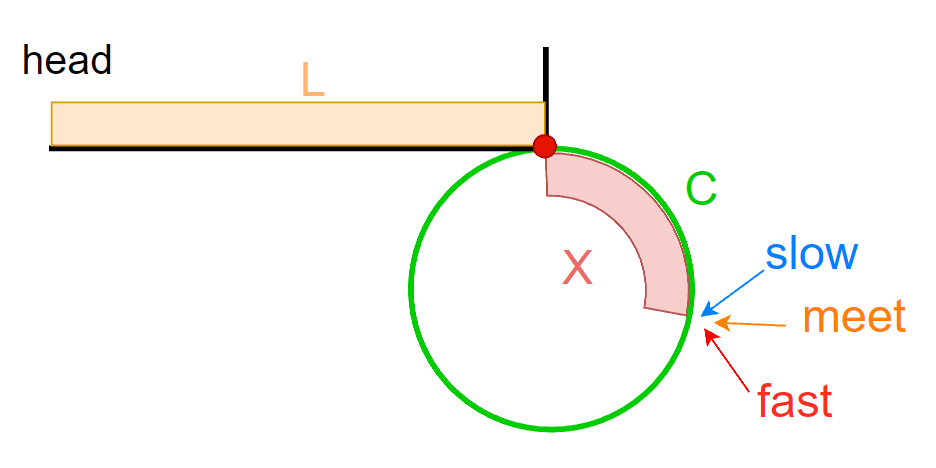
五、环形链表入环结点
带环问题还是用slow走1步,fast走2步,他们两个肯定会相遇,所以有一个相遇点meet,而fast的步数是slow的步数的2倍,得:
为什么x是slow在环内走的这段距离,而不是一圈?
因为slow不可能在环内走超过一圈,就是在一圈内fast绝对能遇到meet,slow走了1圈,fast都走了2圈,因为fast每次走是slow的2倍,(两个指针的差距)N绝对比C小,追的过程差距是逐步-1,不会错过。

还需要说明下slow进环的时候,fast在环内走了多久呢,这是有两种情况
-
当L很长C比较小,fast在环内假设走了很多圈(假设N圈)。

-
当L很短C比较大,fast在环内一圈都没有走。

fast走的距离:
- slow指针走的两倍
- L+N*C+X (N >= 1)
通过这些结论得出关系距离等式:
把N*C 分解成 (N-1)C + C,其中(N-1)C 就是meet又回到meet,绕了几圈又回到了原来的位置,其中C比较大,N = 1,就等于没有走。N > 1的话就等于走了但是最终还是回到原点,所以N >= 1的情况是一样的
最后的结论是L = C-X,C-X是meet到环入口的距离,这段距离和L到环入口的距离是一样的。
主要的原因就是把X的距离给去掉了,x是slow在环入口到环内走了一段的距离,X的起点是入环口,这是最关键的,起定位的作用,不管X有多长,用C-X后得出一段距离的终点是入环点,所以最后会走到环入口的时候相遇
六、OJ:环形链表 II
OJ链接
方法1思路:按照我们刚才的证明和分析,两个结点一个从头开始走,另一个从相遇点meet开始走,最终就可以找到入环口
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* struct ListNode *next;
* };
*/
struct ListNode *detectCycle(struct ListNode *head) {
struct ListNode* slow, *fast;
slow = fast = head;
// 快慢指针
while (fast && fast->next)
{
slow = slow->next;
fast = fast->next->next;
// 找到相遇点meet
if (slow == fast)
{
struct ListNode* meetNode = slow;
struct ListNode* cur = head;
// 一个从头(head)开始走,另一个从相遇点(meetNode)开始
while (meetNode != cur)
{
cur = cur->next;
meetNode = meetNode->next;
}
// 相等后,就说明是找到了入环口,随便返回其一
return meetNode;
}
}
// 链表走完了,就说明不是环形链表
return NULL;
}
方法2思路:
链表相交不需要证明和推导,直接求解,此方法可以分成两种解法
- 第一种:找到相遇点后,把相遇点断开,把meet的next设为新链表的头,meet的next设为NULL,直接断开环。然后就成了链表相交问题了,但是这修改环形链表的结构,OJ上面说明不能修改。

- 第二种:找到相遇点后,把相遇点设为尾,把meet的next设为新链表的头,就成了链表相交问题,没有修改链表结构

我的解法是第二种,不修改链表的结构,两种方法大同小异,本质上都是相交链表
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* struct ListNode *next;
* };
*/
struct ListNode *detectCycle(struct ListNode *head) {
struct ListNode* slow, *fast;
slow = fast = head;
// 快慢指针判断是否是环
while (fast && fast->next)
{
slow = slow->next;
fast = fast->next->next;
// 找到相遇点meet
if (slow == fast)
{
struct ListNode* meetNode = slow; // 假设为尾
struct ListNode* A = head;
struct ListNode* B = meetNode->next; // 新链表
struct ListNode* tailA = A, *tailB = B;
int lenA = 0, lenB = 0;
// 两个链表到meetNode的长度
while (tailA != meetNode)
{
lenA++;
tailA = tailA->next;
}
while (tailB != meetNode)
{
lenB++;
tailB = tailB->next;
}
// 长链表先走gap步
struct ListNode* longList = A, *shortList = B;
int gap = abs(lenA - lenB);
if (lenA < lenB)
{
longList = B;
shortList = A;
}
while (gap--)
longList = longList->next;
// 相等就找到交点了,也就是第一个入环点
while (longList != shortList)
{
shortList = shortList->next;
longList = longList->next;
}
return shortList;
}
}
return NULL;
}

















 1600
1600

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









