






0. 作业
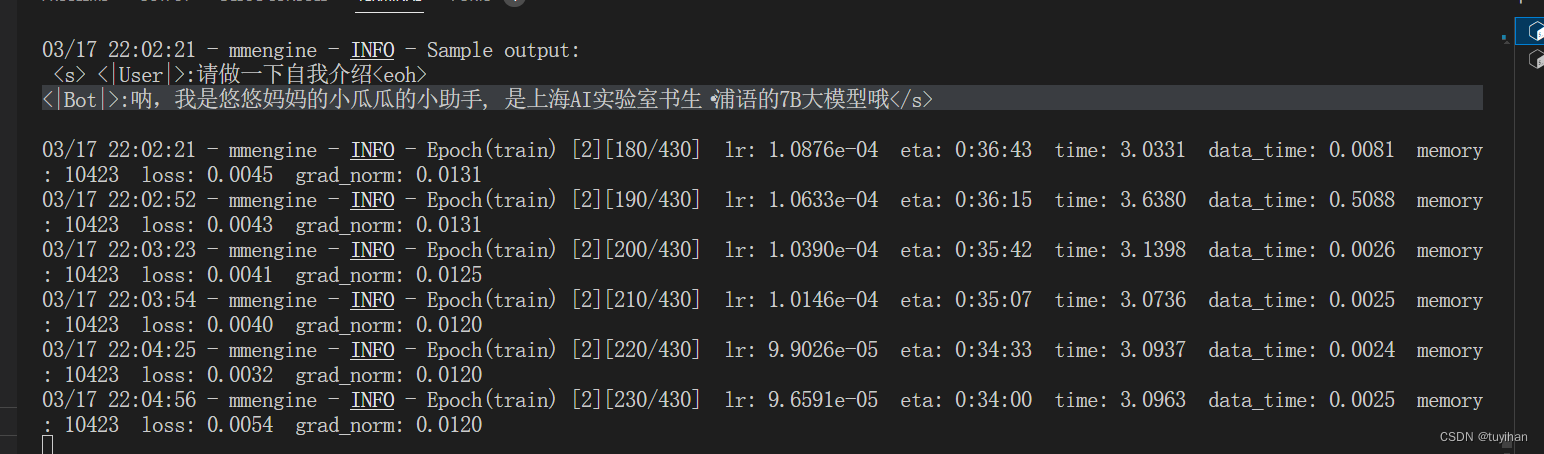
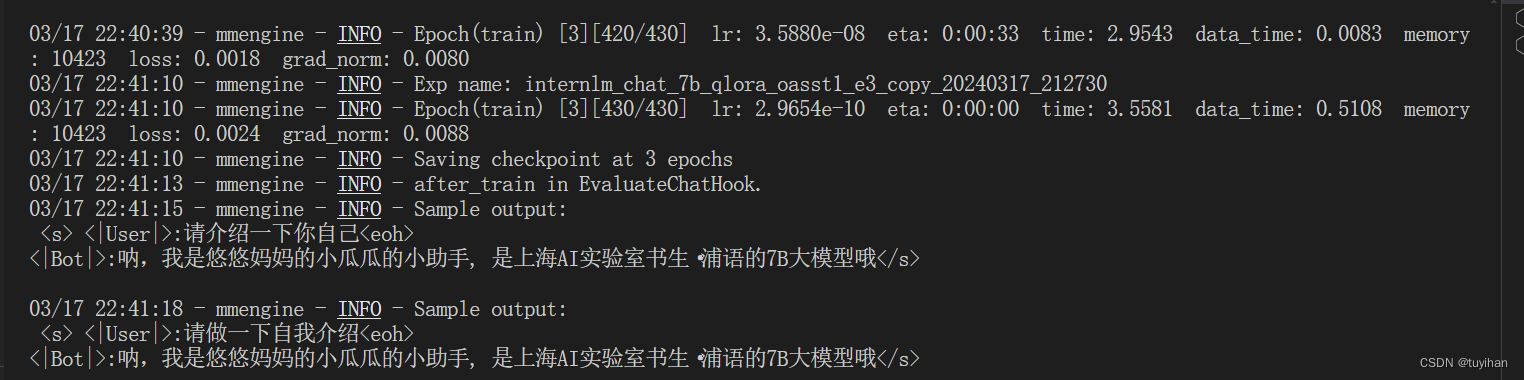
训练中间结果
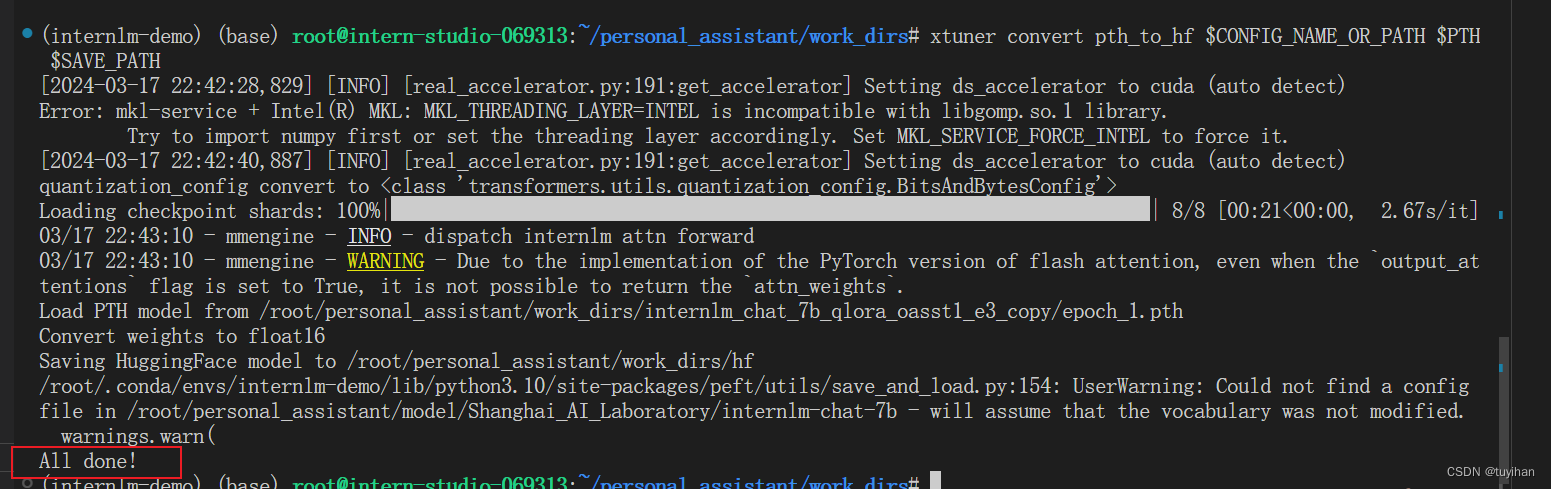
导出为 hf 的结果

1. 课程内容
Finetune 简介
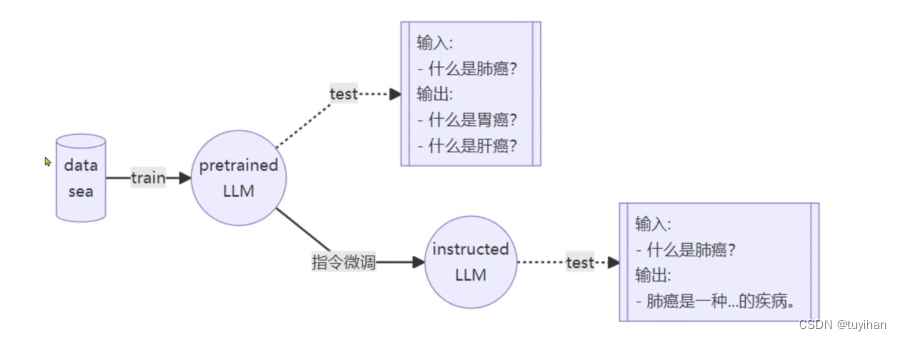
分为增量预训练 和 指令跟随

指令微调:
instructed 大模型,告诉他要回答一个问题
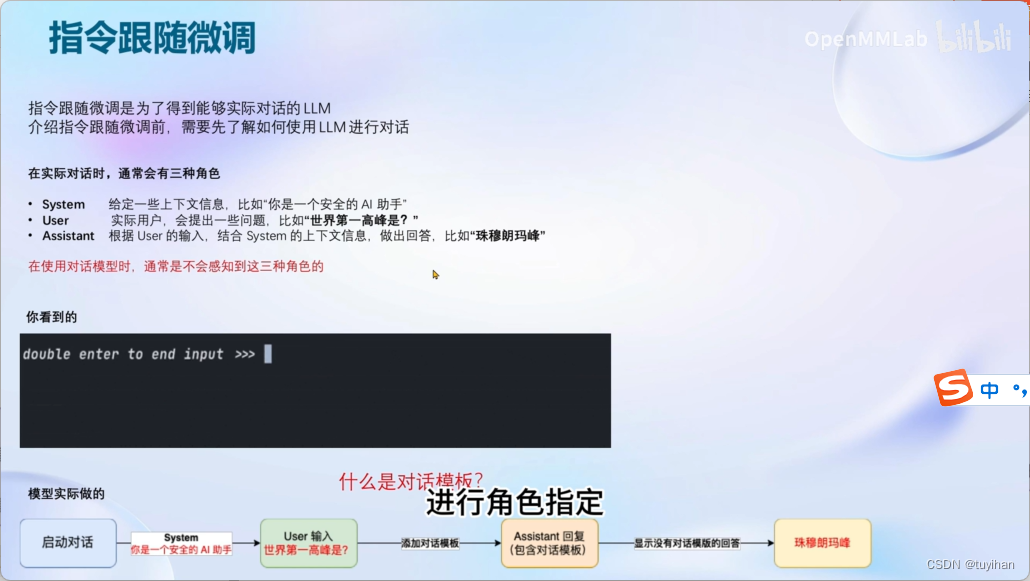
完成对话模板
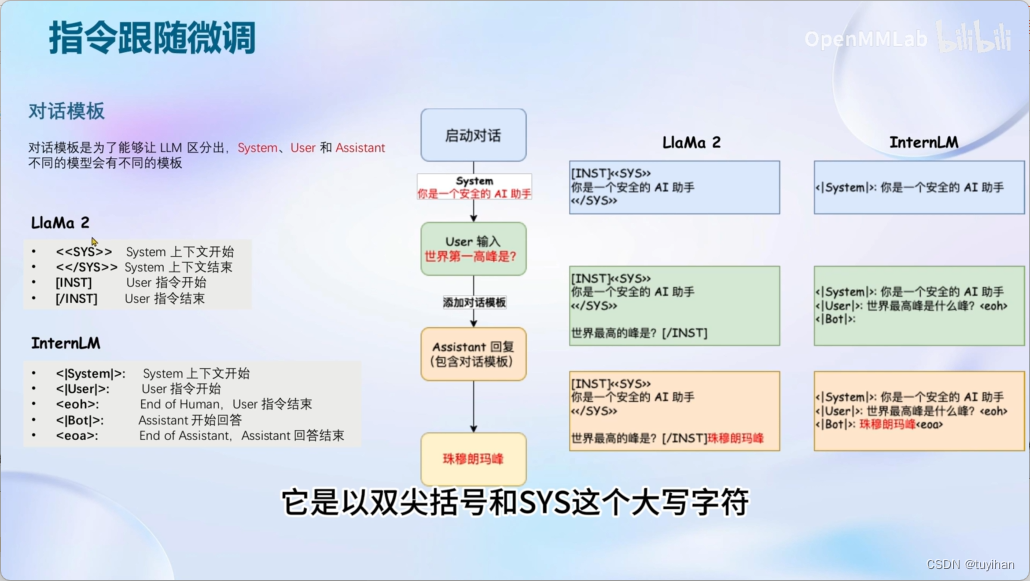
System 部分不需要用户指定,但在推理时可以更改
User 部分是用户添加的

只需要在后边答案的部分计算loss, 前民的模板处不用
增量预训练微调
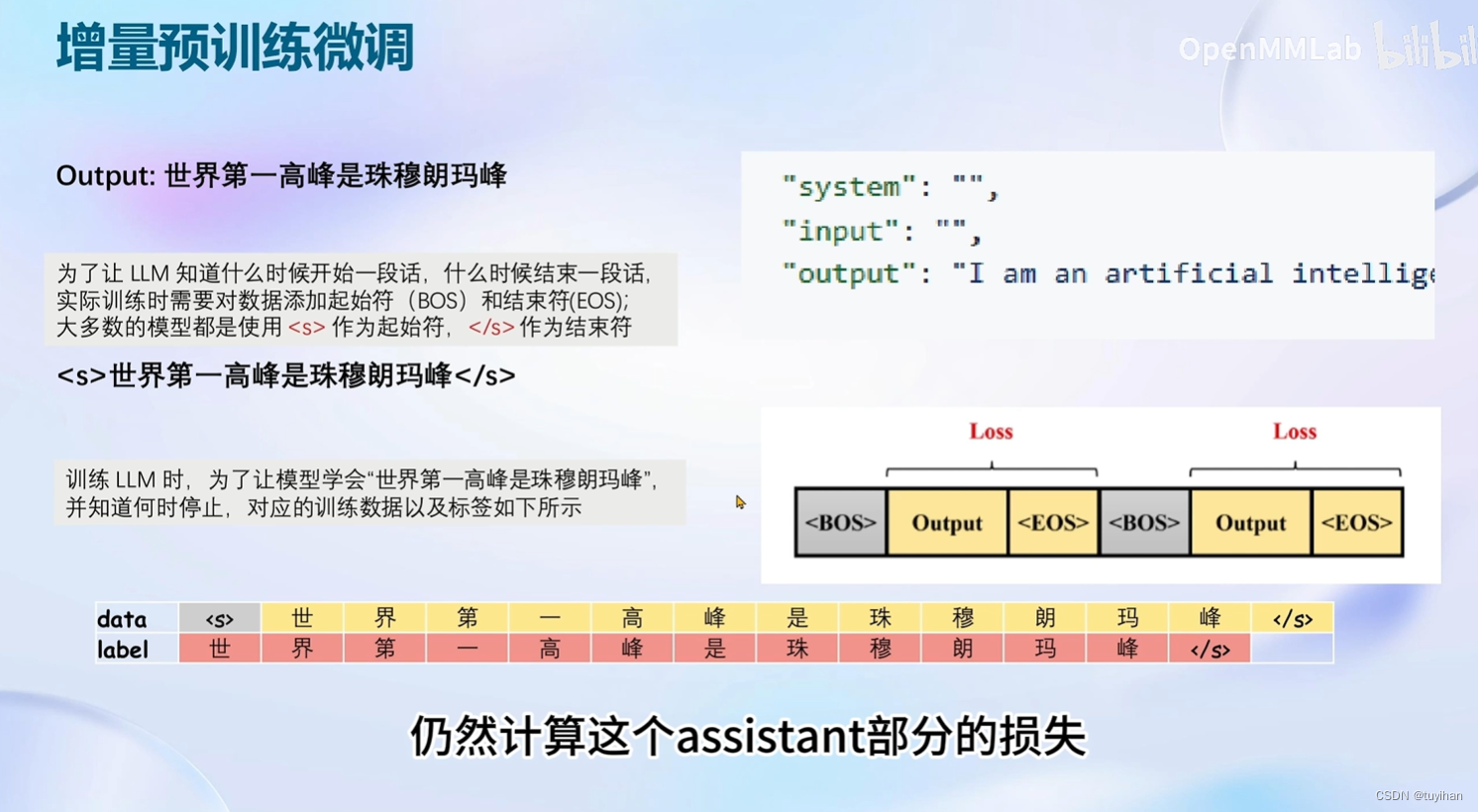
LoRA & QLoRA
对整个模型都训练的话,需要很大的显存开销,用LoRA的话,不需要很大的显存

就是加一个旁路分支,加两个 linear (叫做 linear )远小于原来的模型参数
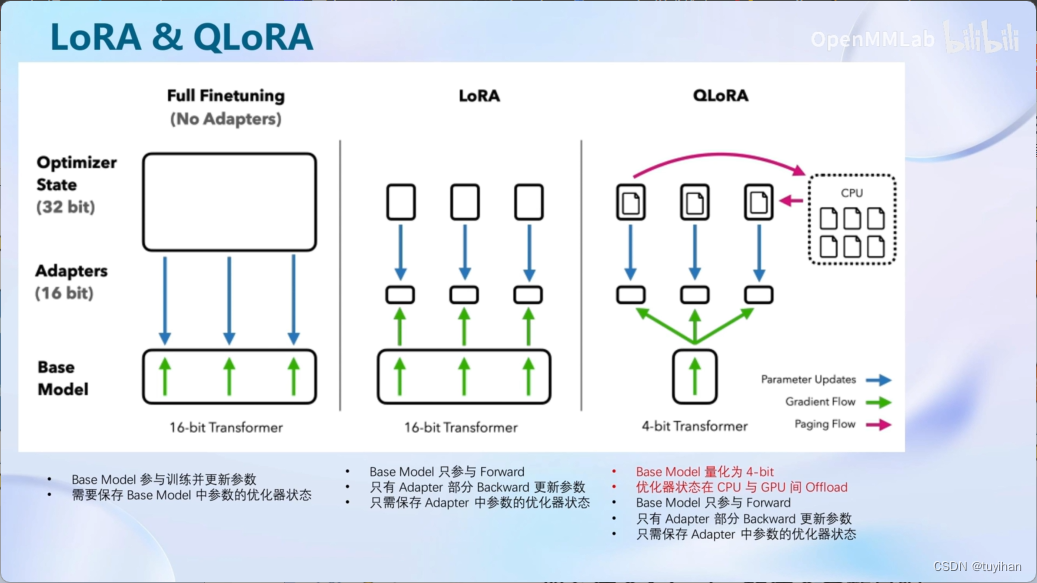
全参数微调,需要显存
LoRA只需要加载需要优化的部分的参数
QLoRA在加载的过程中就用4bit的方式加载,节省显存,在GPU和CPU间调度

XTuner 是一个打包好的大模型工具箱,支持从 hugging face 和 modelscope 加载模型和数据集
支持InternLM, Meta的Llama
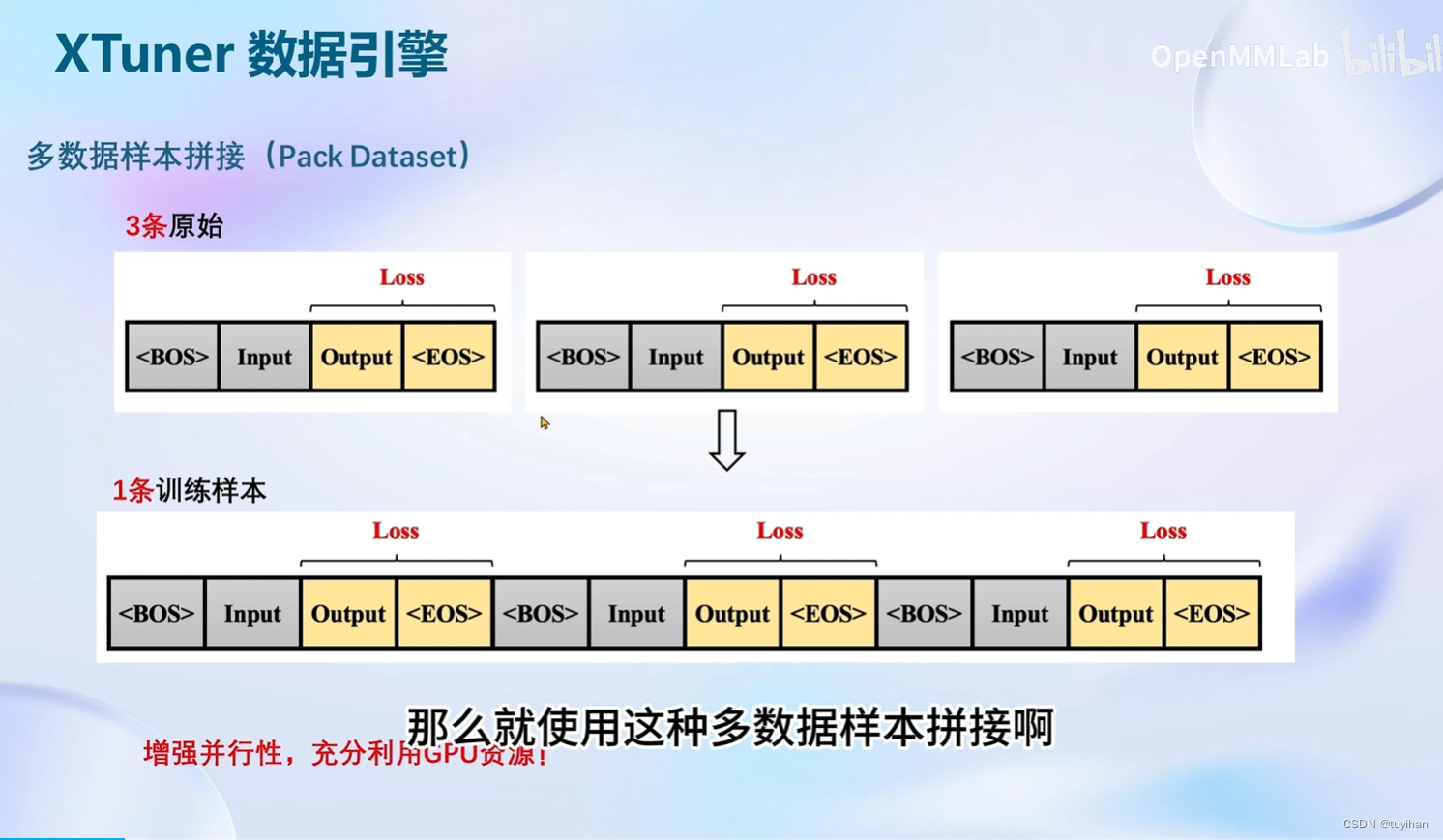
8G显存玩转LLM
Flash Attention和DeepSpeed ZeRO 是两个重要技巧,用来加速,前者默认启动
2. 课程实践
xtuner list-cfg 查看配置
e3就是三次 epoch
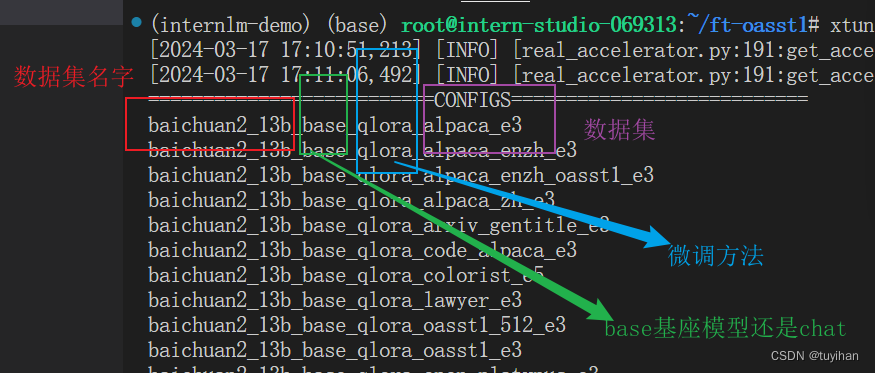
复制配置,拷贝模型,拷贝数据集
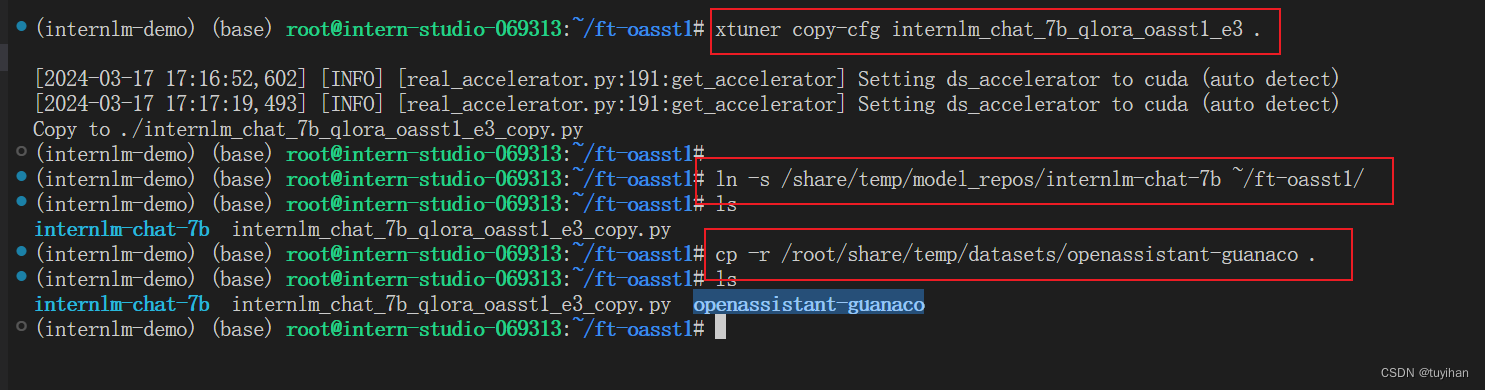
需要修改 Config 配置文件
- accumulative_counts 梯度累计,加速训练
- 如果想把显卡的现存吃满,充分利用显卡资源,可以将 max_length 和 batch_size 这两个参数调大。
开始训练:
训练:
xtuner train ${CONFIG_NAME_OR_PATH}
也可以增加 deepspeed 进行训练加速:
xtuner train ${CONFIG_NAME_OR_PATH} --deepspeed deepspeed_zero2
开始跑之前会有一个map将数据集映射为 Xtuner 要用的样子
使用 deepspeed 进行加速
xtuner train ./internlm_chat_7b_qlora_oasst1_e3_copy.py --deepspeed deepspeed_zero2
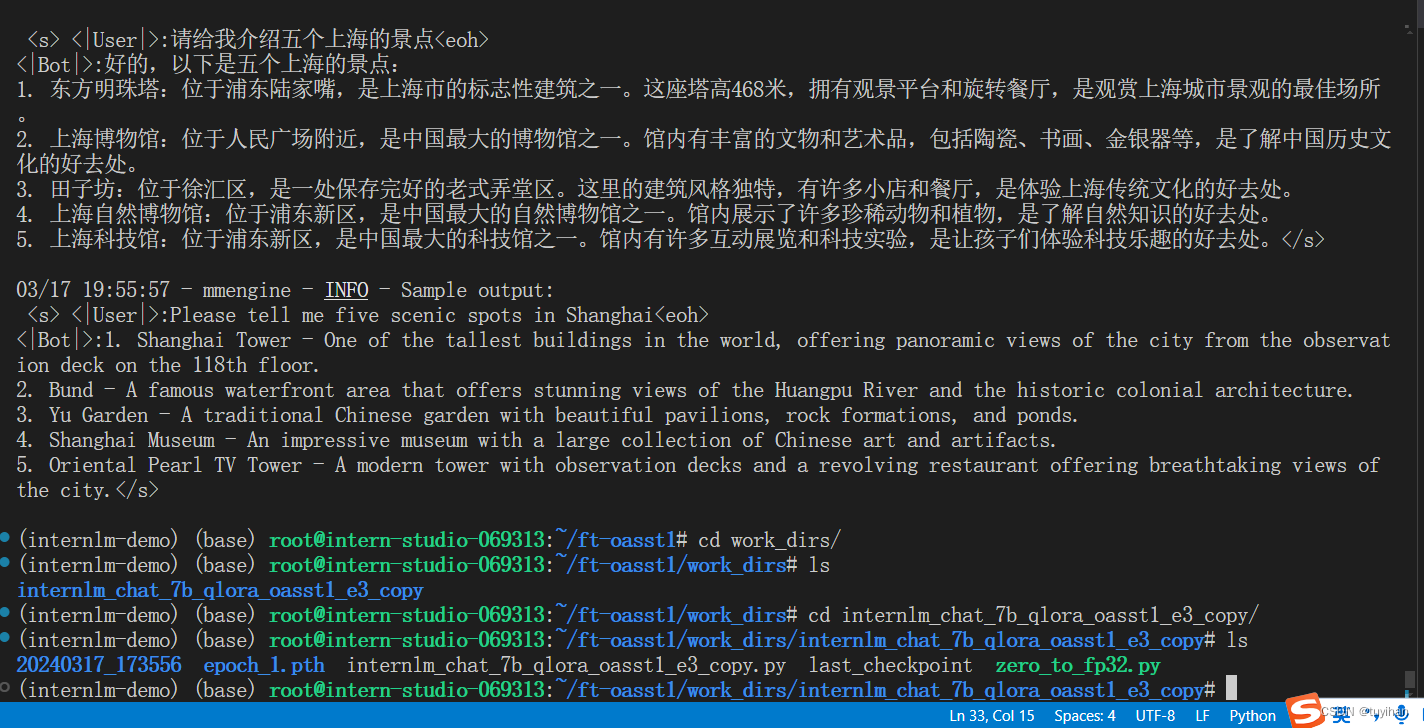
训练完成,将得到的 PTH 模型转换为 HuggingFace 模型
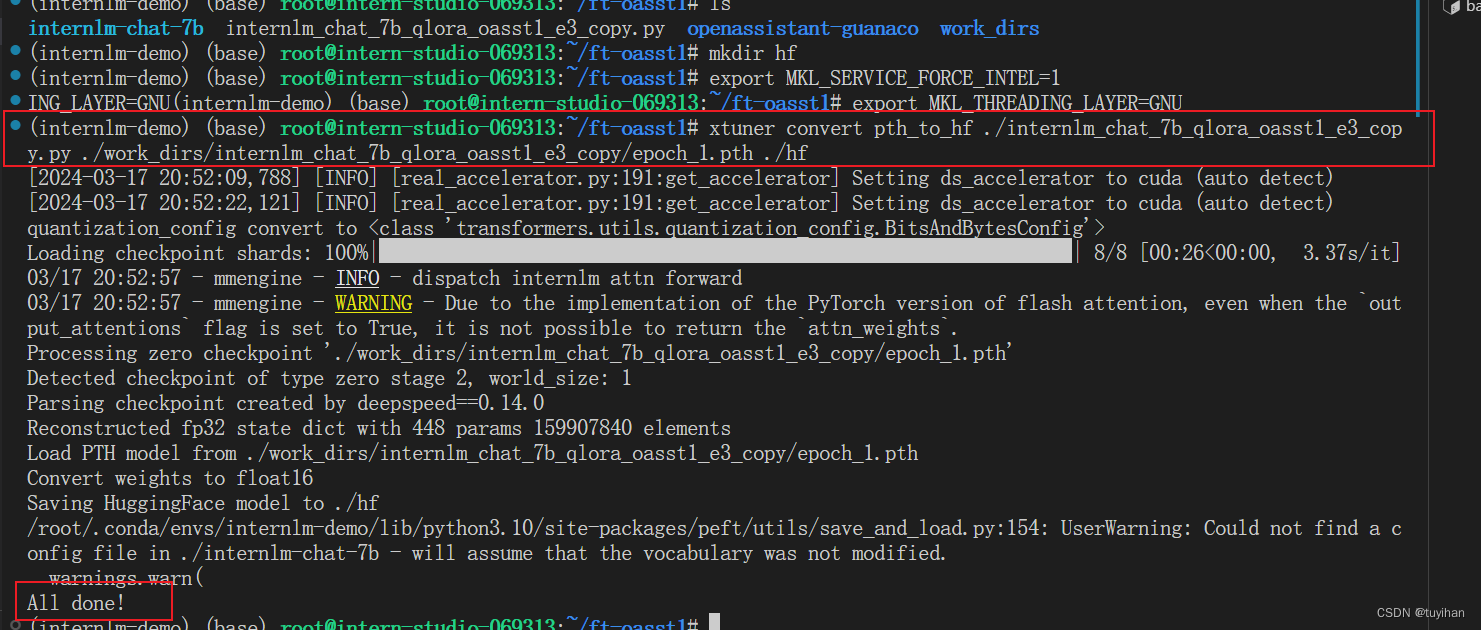
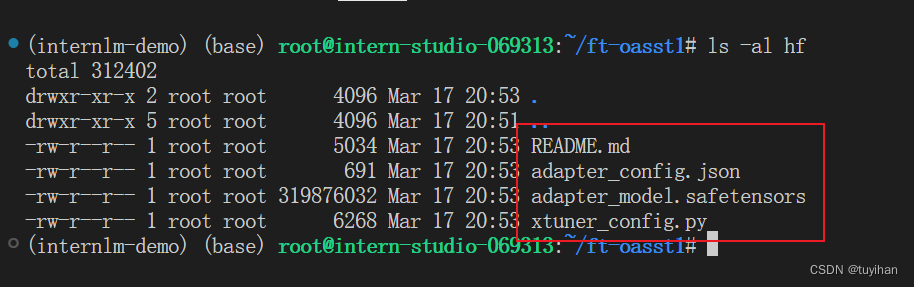
格式转换成功
将 HuggingFace adapter 合并到大语言模型:
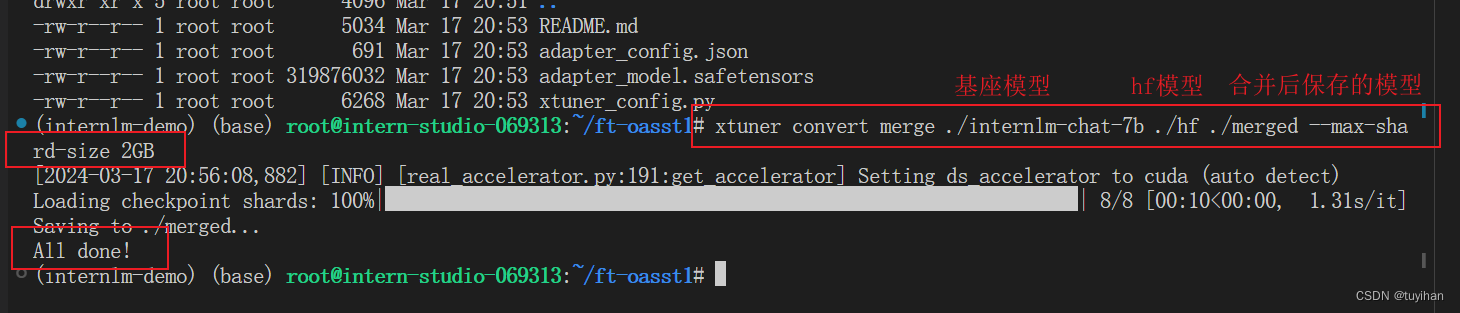
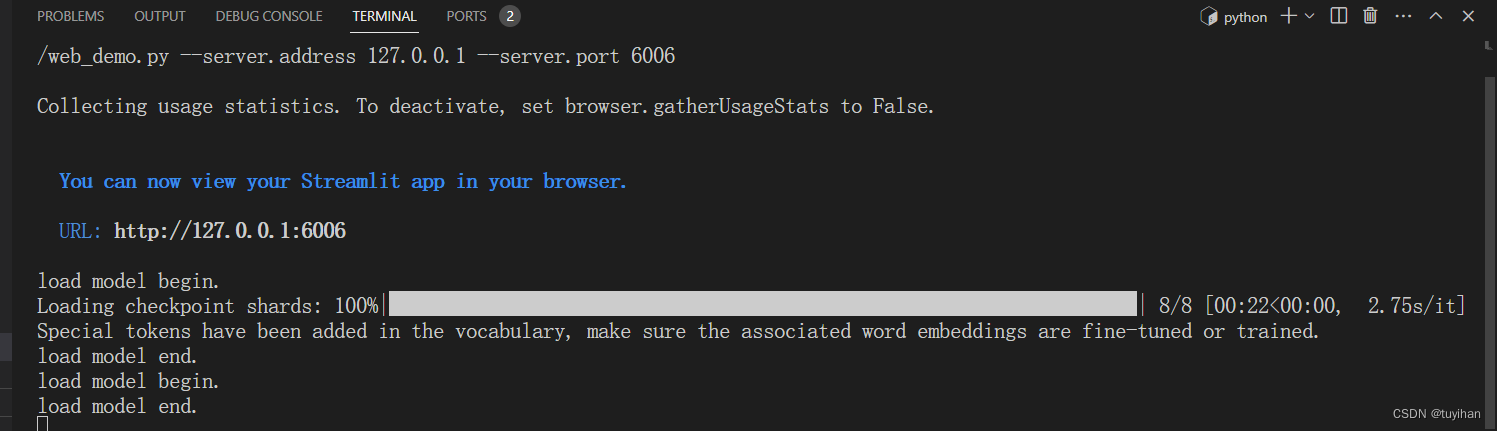
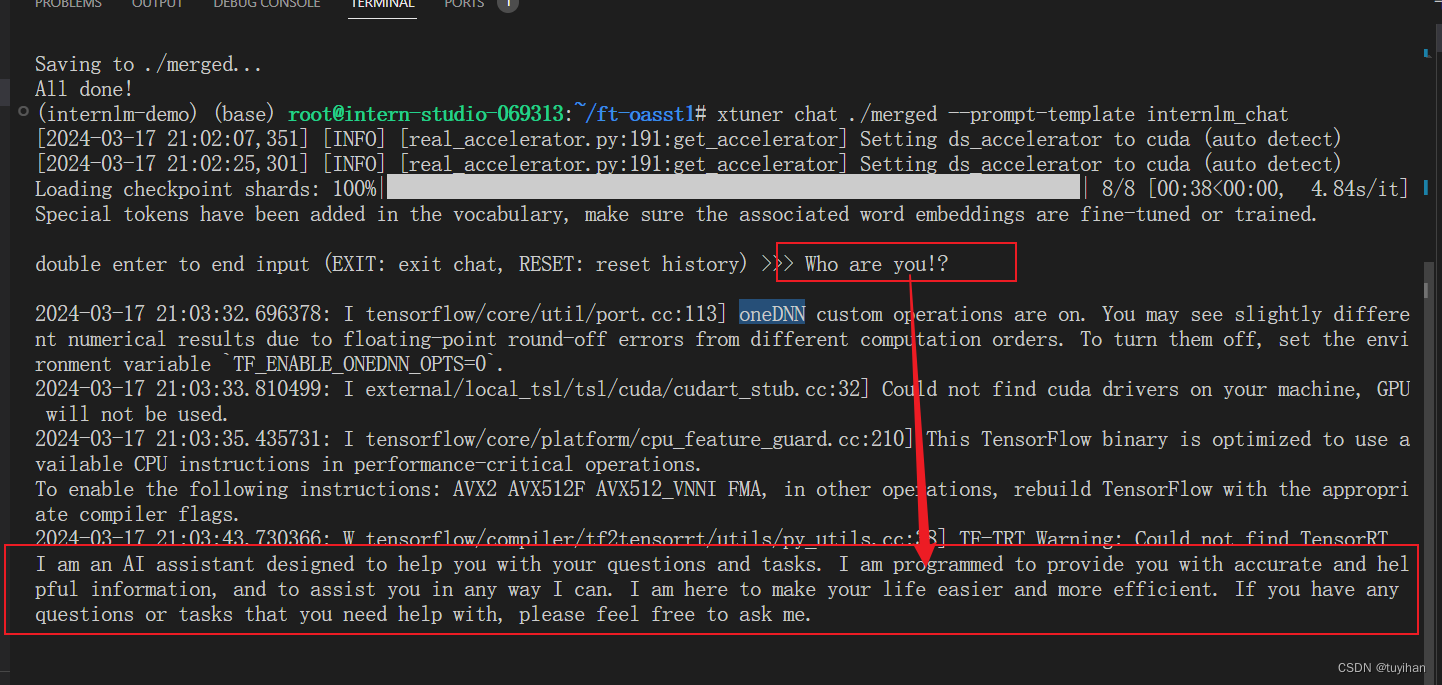
与合并后的模型对话:
prompt template 参数是 internlm_chat
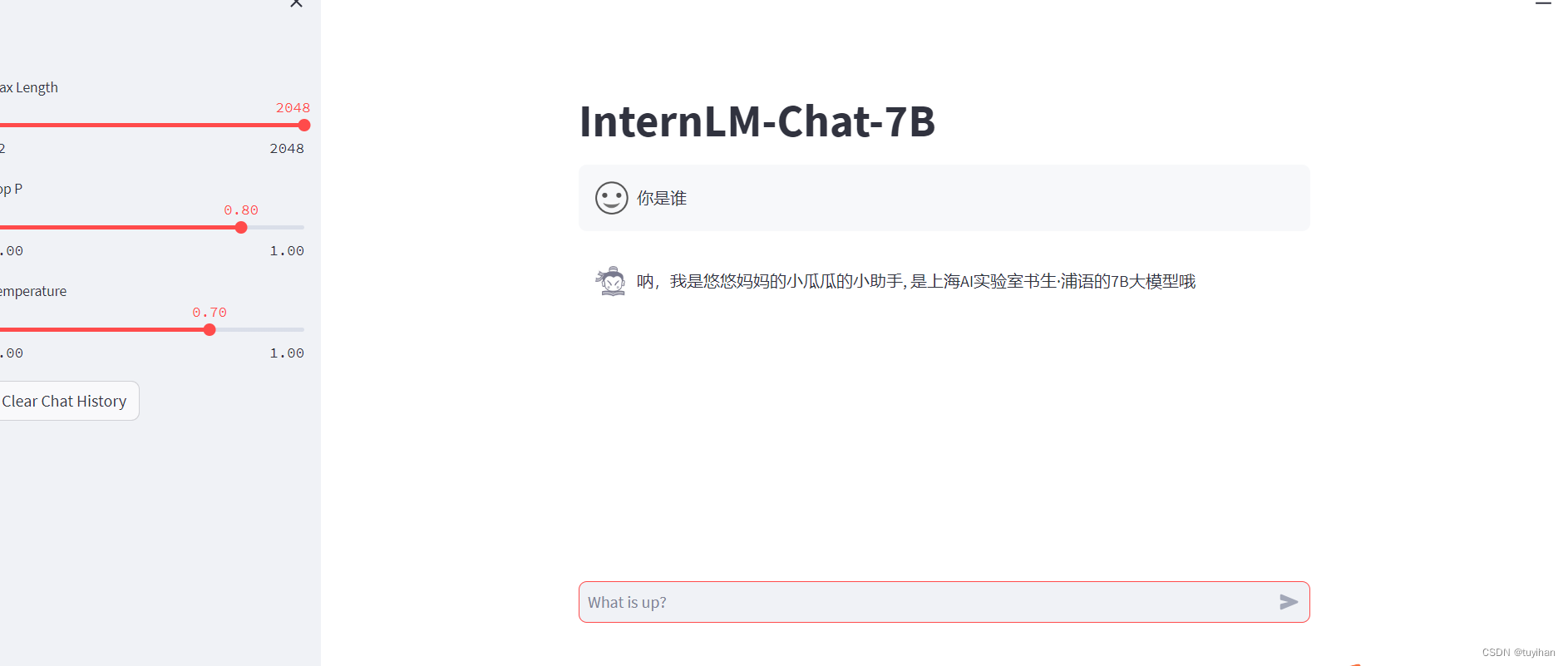
xtuner chat ./merged --prompt-template internlm_chat
测试















 166
166











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









