







1. 模型训练
1.1 数据集
数据集设定:训练集train set、开发集dev set、测试集test set。采用训练集对模型进行训练,然后采用验证集验证参数,直到训练集和开发集均能得到较好的结果,再采用测试集进行评估。
在以往的机器学习中,三种数据集的比例train/dev/test为70%/30%/0%或者60%/20%/20%。
在大数据中,可以视数据量来确定三种数据集的比例,例如98%/1%/1%。
数据集的不匹配:如果出现训练集和测试集来源不匹配的情况,例如训练集是从网页上抓取的猫咪图片,而测试集是用户上传的猫咪图片,应当确保开发集与测试集具有相同的来源。
此外,仅有开发集、没有测试集也是可行的。
1.2 偏差/方差权衡(Bias/Variance Tradeoff)
下图给出了三种情况。左图训练的模型无法很好表征训练集的分布,偏差较高,也就是欠拟合(underfitting);右图训练的模型过于复杂,能够比较完美表征训练集的分布,但是预测开发集的准确率会降低,方差较高,也就是过拟合(overfitting);中图的模型介于两者之间,对于训练集和开发集都能较好的拟合。
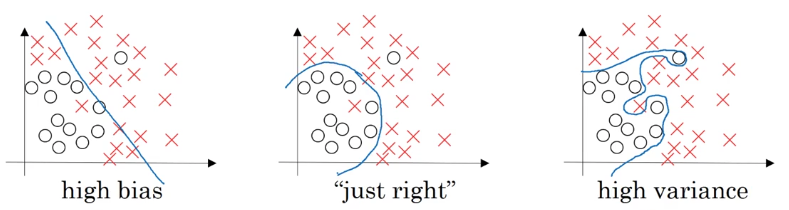
也可以用训练集误差和开发集误差来判断(假设误差可以达到0%):
|
|
|
|
|
|
|---|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
1.3 模型训练的偏差/方差权衡问题
先看偏差,如果偏差较高欠拟合,尝试更大的神经网络、增加训练集数据或者选择其他神经网络算法,直到偏差较小。
再看方差,如果方差较高过拟合,尝试增加训练集数据、正则化算法或者选择其他神经网络算法,直到方差和偏差均较小。
在过去的机器学习时代,很难做到偏差和方差的权衡;但是在大数据时代,只要能够得到足够多的数据,来训练较大的网络,就能够同时做到低偏差、低方差。
2. 正则化
2.1 L2正则化
回顾逻辑回归算法中的代价函数如下:
J(w,b)=1m∑i=1mL(a(i),y(i))+λ2m∥w∥22(1)
上式在之前的代价函数中添加了L2正则化项:
λ2m∥w∥22=λ2m∑j=1nxw2j=λ2mwTw(2)
也可以使用L1正则化项如下,得到的w向量会比较稀疏,会有很多0值,虽然可以降低存储空间,不过帮助不大,通常很少使用:
λ2m∥w∥21=λ2m∑j=1nx∣∣wj∣∣(3)
式中,λ为正则化参数,是一个需要调整的超参数。
对于神经网络,也可以得到类似的正则化:
J(W[1],b[1],⋯,W[L],b[L])=1m∑i=1mL(a(i),y(i))+λ2m∑l=1L∥∥W[l]∥∥2F(4)
式中:
∥∥W[l]∥∥2F=∑i=1n[l−1]∑j=1n[l](W[l]ij)2(5)
也称作Frobenius范数,是矩阵元素绝对值的平方和再开方。
正则化后,梯度项也需要作相应的修正:
dW[l]=(dW[l])non−regularization+λmW[l](6)
式中, 表示没有正则化算法的梯度项。然后利用下式对参数进行更新:
W[l]=W[l]−αdW[l]b[l]=b[l]−αdb[l](7)
可以将权值写成如下形式:
W[l]=W[l]−α[(dW[l])non−regularization+λmW[l]]=(1−αλm)W[l]−α(dW[l])non−regularization(8)
可以看出,正则化相当于在权值上添加了一个衰减系数,因此也称作权值衰减(weight decay)。
2.2 为什么正则化可以避免过拟合?
假如一个模型过拟合,也就是高方差,将正则化参数λ设置的非常大,可以得到W[l] ≈ 0,那么就去除了很多隐藏单元的功能,使得神经网络更加简单,也就从高方差转变为高偏差的情况。那么一些中间的λ值可能会存在低偏差、低方差的情况。
2.3 Dropout正则化
Dropout:神经网络从左到右的每一层,设定概率来随机消除神经网络中的节点。
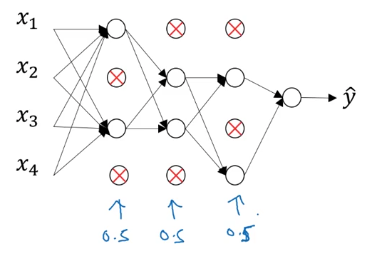
对于第l层,可以设置一个随机的0、1矩阵:
dl=np.random.rand(al.shape[0],al.shape[1])<keep_prob(9)
式中,keep_prob为保留节点的概率,例如keep_prob = 0.8表示有0.2的概率去除任一个隐藏节点,keep_prob = 1表示不采用Dropout正则化。然后进行如下消除:
al=np.multiply(al,dl)(10)
由于以上消除节点的过程会降低a[l]的期望值,因此还要作如下操作,以确保z[l]的期望值正确:
al=al/keep_prob(11)
注意:Dropout正则化只应用于训练集上,而不用于开发集或者测试集上。
2.4 为什么Dropout是一种正则化?
一方面,Dropout会使得神经网络更简单,类似于正则化;
另一方面,采用Dropout,一些节点会被消除掉,由于每个节点都会分担部分的权值,部分节点的消除就会导致权值降低,类似于L2正则化的权值衰减。
在设置keep_prob时,可以为不同层设置不同的数值,对于比较复杂的层可以设置较小的数值以避免过拟合,而对于一些不担心会出现过拟合的层可以将keep_prob设置为1,输入层的keep_prob也通常设置为1。
注意:在训练过程中,由于节点的随机消除,很难确保代价函数J的单调递减。
2.5 其他正则化方法
数据扩增:例如图像翻转、裁剪、扭曲,语音加噪等。
Early stopping:将代价函数与开发集误差曲线放在一张图上,提前终止于开发集误差较小的状态,而非代价函数较小的状态。缺点在于,early stopping破坏了最优化代价函数的目标,使用一种方法来处理两个问题,使得问题更复杂。

3. 提升模型训练的效率
3.1 训练集归一化
首先,将均值归一化:
μ=1m∑i=1mx(i)x=x−μ(12)
然后,将方差归一化:
σ2=1m∑i=1m[x(i)]2x=xσ2(13)
开发集和测试集需要采用与训练集相同的归一化。
归一化的解释:假如数据集的分布比较广泛,非归一化时的代价函数例如下图左,梯度下降可能需要多步来回迭代才能找到代价函数的最优质。而归一化代价函数例如下图右,能够更快地迭代到最小的代价函数。

不过,如果数据集的分布比较集中,不使用归一化的影响较小。
3.2 梯度消失/梯度爆炸(Gradient Vanishing/Exploding)
当训练一个非常深的神经网络时,可能出现梯度非常大或者非常小的情形,使得训练很难进行下去。
给定以下的L层神经网络,为了便于推导,采用线性激活函数g(z) = z,并忽略b:

根据正向传播,可以将输出写作:
y=W[L]W[L−1]⋯W[1]X(14)
假如将W[l]写成如下的形式:
W[l]=[u00u],l=1,2,…,L−1(15)
则输出为:
y=W[L][u00u]L−1X(16)
可以看出,输出为uL-1量级,输出值会指数级增加或下降。对于非常深的神经网络,如果u较小,输出会非常小,此时的梯度也会非常小,出现梯度消失(Gradient Vanishing)的现象;如果u较大,输出会非常大,此时的梯度也会非常大,出现梯度爆炸(Gradient Exploding)的现象。
3.3 权值初始化
较好的权值初始化可以在一定程度上缓解梯度消失/梯度爆炸现象。
对于神经网络模型,正向传播为:
Z[l]=W[l]X+b(17)
可以看出,为了保持Z不变,当输入层nx越大时,W应当越小,从而可以将权值的方差设定为:
Var(W[l])=2n[l−1](18)
上式的方差项主要针对ReLU激活函数。从而采用如下的初始化:
W[l]=np.random.randn(nl,nl−1)∗np.sqrt(2n[l−1])(19)
对于不同的激活函数,方差项也有所不同:
tanh:Var(W[l])=1n[l−1]xavierinitialization:Var(W[l])=2n[l−1]+n[l](20)
3.4 梯度检查技巧
将所有参数W[1], b[1], …, W[L], b[L]归入一个参数θ中:
J(W[1],b[1],…,W[L],b[L])=J(θ)(21)
可以得到近似梯度:
dθ[i]approximate=J(θ1,θ2,…,θi+ε,…)−J(θ1,θ2,…,θi−ε,…)2ε≈dθ[i]=∂J∂θi(22)
然后计算近似梯度与实际梯度之间的误差:
error(θ)=∥∥dθapproximate−dθ∥∥2∥∥dθapproximate∥∥2+∥dθ∥2(23)
将ε取为较小的数值,例如ε = 10-7,如果上式也较小(小于10-7),就表明梯度计算正确。
4. 代码实现
4.1 初始化的影响
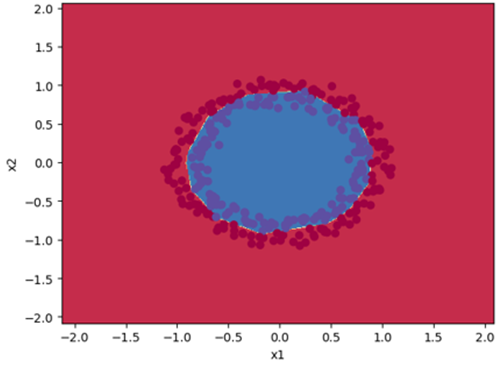
案例:对蓝点和红点进行二分类,研究不同的初始化参数对结果的影响。
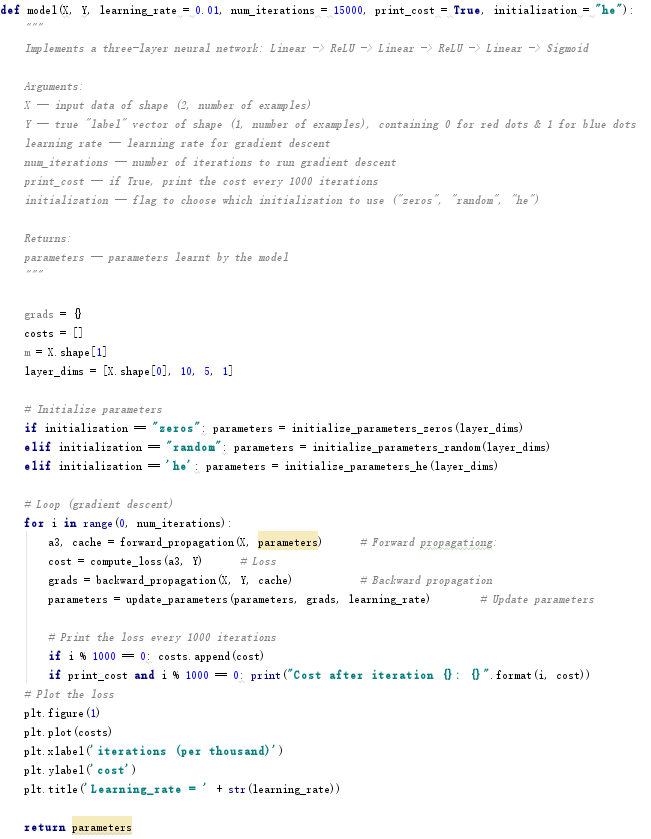
采用三层神经网络,模型代码如下,各个模块代码已在前面的学习给出。
4.1.1 零初始化
对参数进行零初始化如下。

训练得到参数,并分别对训练集和测试集进行预测,核心代码如下:

得到如下结果,可以看出,零初始化的情况下代价函数没有任何变化,对于任意样本的预测输出全为0。
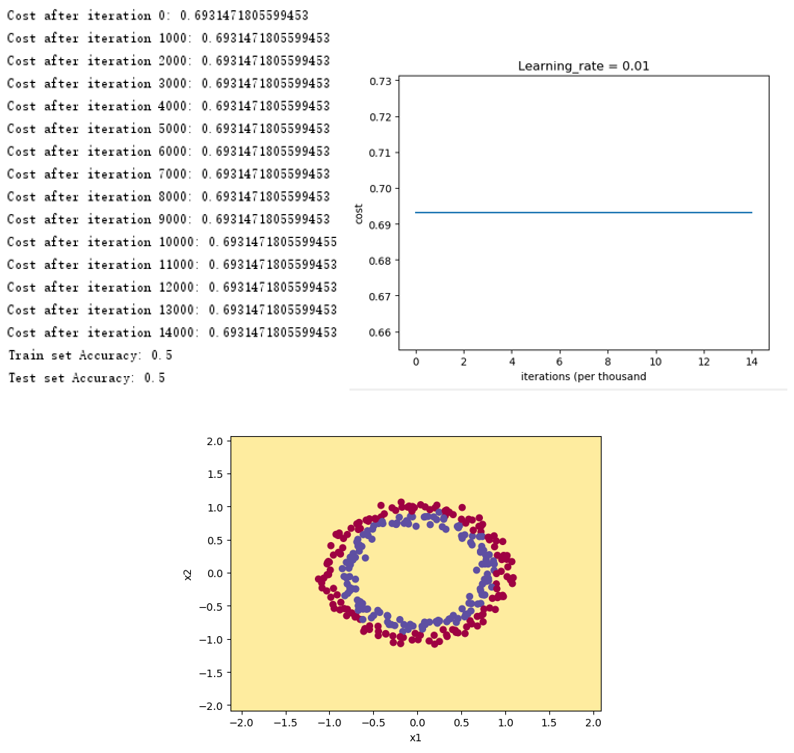
4.1.2 随机初始化
将参数W随机初始化,并乘以10,参数b全部初始化为0,核心代码如下:

得到如下结果,可以看出,初始时代价函数的数值非常大,这是因为初始化的参数W较大,减小初始化参数的数值有利于加快训练速度。
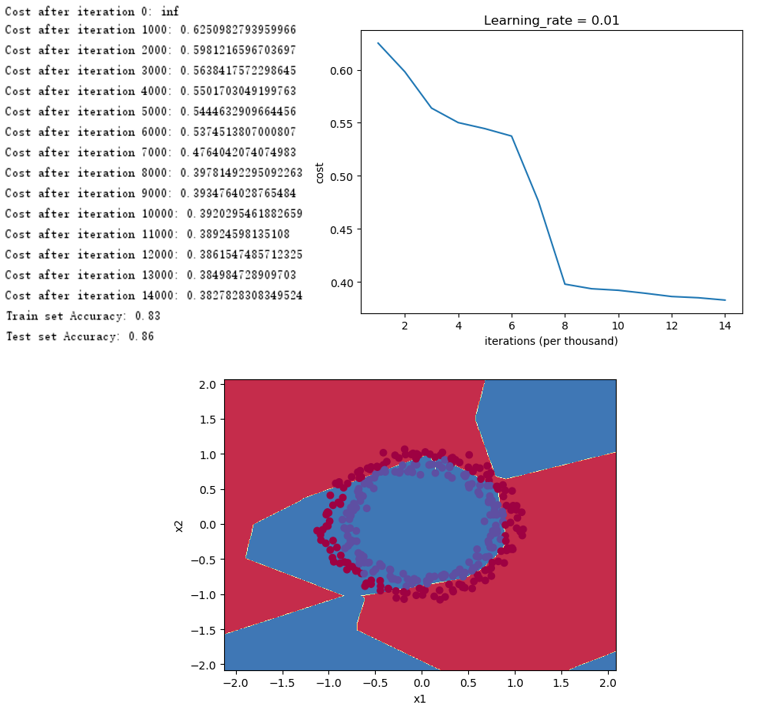
4.1.3 He初始化
采用下式进行He初始化:
W[l]=np.random.randn(nl,nl−1)∗np.sqrt(2n[l−1])(24)
核心代码如下:

得到如下结果,可以看出,合适的初始化使得代价函数下降很快,能够很好地对蓝点和红点进行分类。
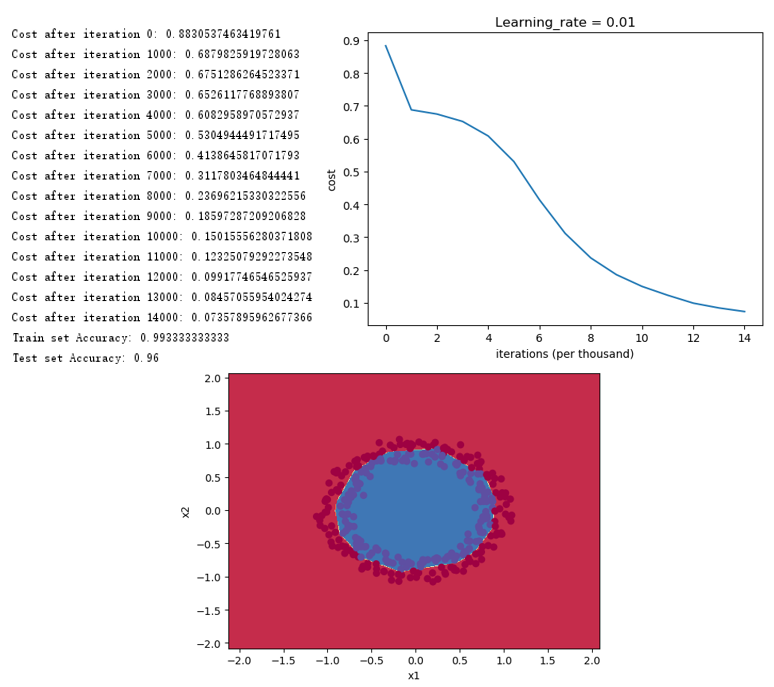
4.2 正则化
案例:对蓝点和红点进行二分类,研究不同的正则化对结果的影响。
采用三层神经网络,模型代码如下,包含了非正则化、L2正则化和Dropout,其他模块已在之前的学习中给出。
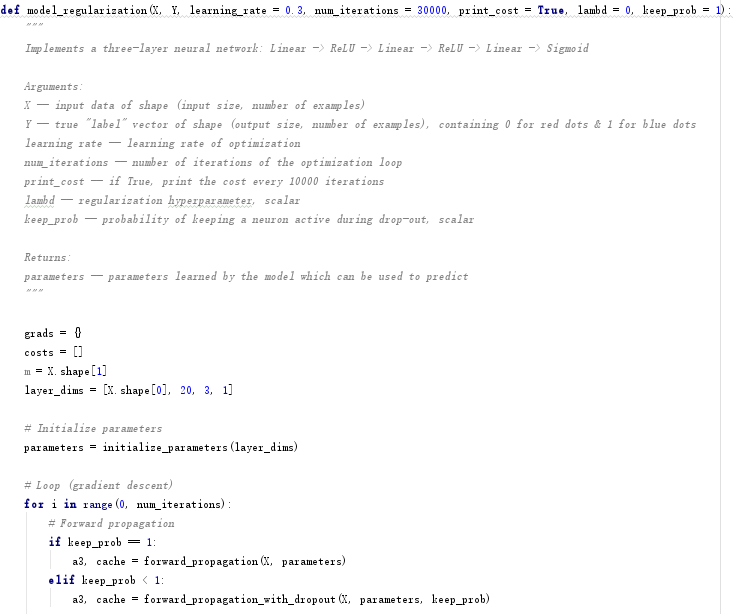
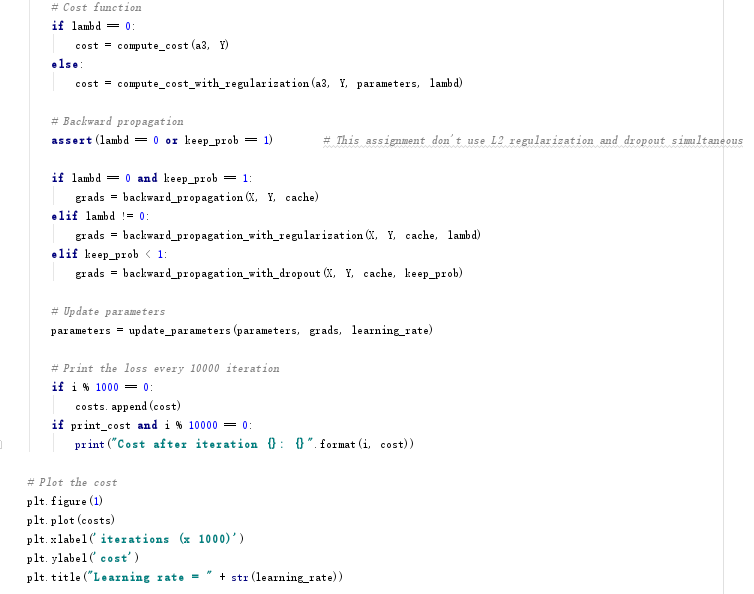
4.2.1 非正则化
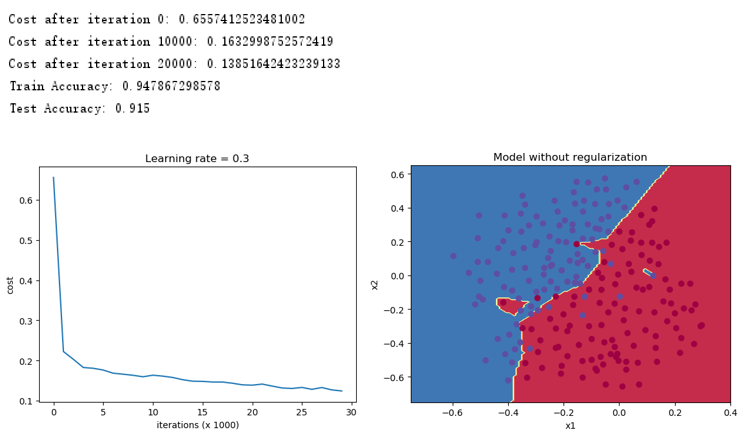
不使用正则化,得到如下的结果,存在一定的过拟合。
4.2.2 L2正则化
L2正则化下,需要对代价函数进行改写:
Jregularized=1m∑i=1m(y(i)log(a[L](i))+(1−y(i))log(1−a[L](i)))cross−entropycost+1mλ2∑l∑k∑jW[l]2k,jL2regularizationcost(25)
核心代码如下:
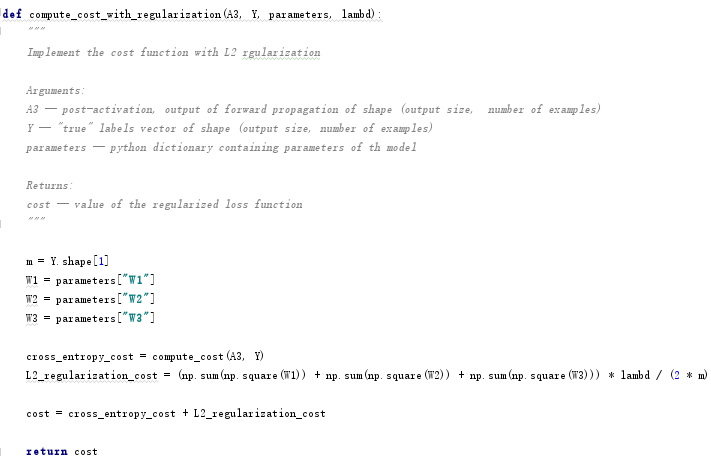
同样要对反向传播进行修正:
dW[l]=(dW[l])non−regularization+λmW[l](26)
核心代码如下:

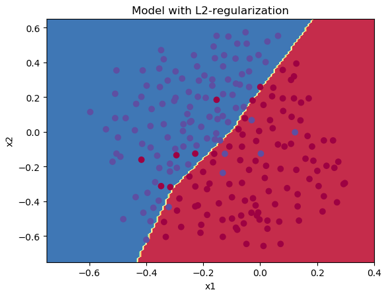
使用L2正则化得到如下结果,可以看出,采用L2正则化有利于处理过拟合的问题,不过需要调整正则化参数。
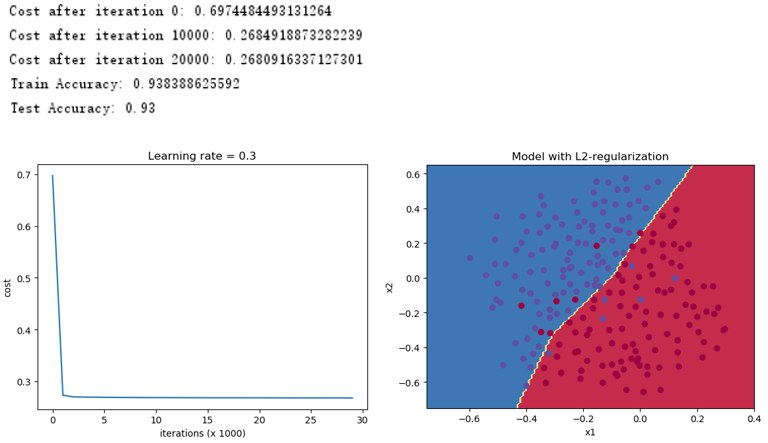
4.2.3 Dropout
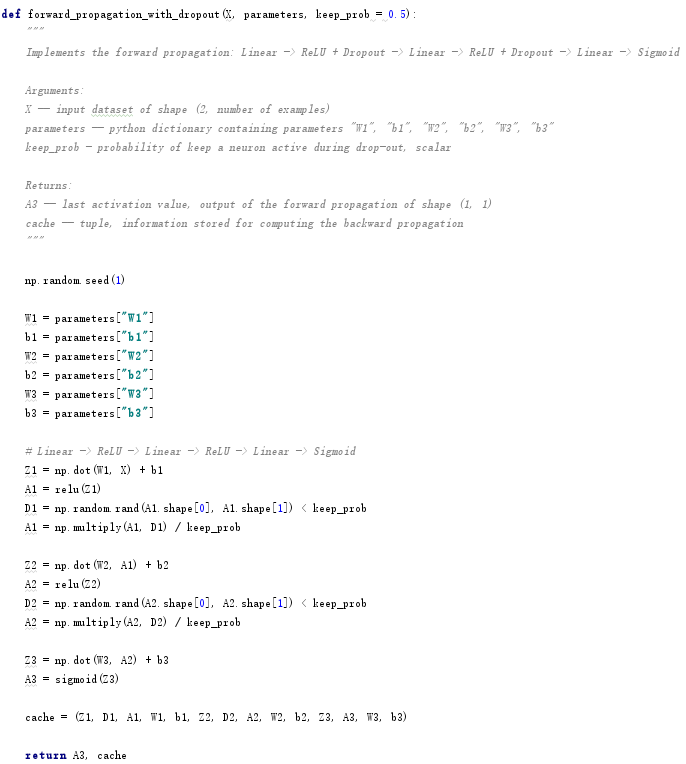
采用Dropout,先要定义一个与A[l]相同维度的矩阵D[l],并按照概率随机初始化为0、1矩阵,矩阵元素为0的概率为keep_prob,矩阵元素为1的概率为1 – keep_prob,然后计算 。需要同时对正向传播和反向传播进行修正,需要确保每次迭代正向传播和反向传播消除的节点是相同的,核心代码如下:

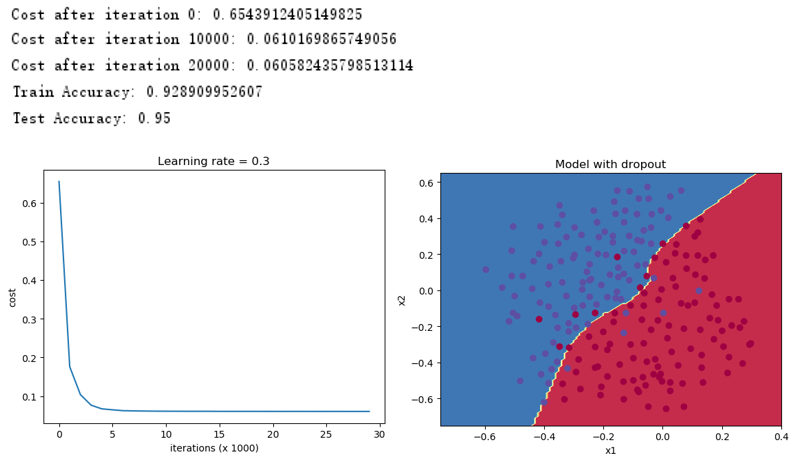
使用Dropout正则化得到如下结果,可以看出,采用Dropout有利于处理过拟合的问题,得到了95%的测试准确率。
4.2.4 总结
下表给出3层神经网络下,非正则化、L2正则化、Dropout三种情况下的训练和测试准确率:
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
可以看出,正则化限制了模型对训练样本的匹配程度,会使得训练准确率有所下降,但是得到了更高的测试准确率,从而使得系统运行得更好。
代码下载地址:https://gitee.com/tuzhen301/Coursera-deeplearning.ai2-1















 1765
1765

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









