







1 超参数(Hyperparameter)
神经网络中,最重要的超参数是学习因子α;其次是Momentum参数β(通常0.9)、mini-batch大小、隐含层单元数;再其次是隐含层层数、学习因子衰减率。如果采用Adam算法,其参数通常可以选用默认,β1 = 0.9、β2 = 0.999、ε = 10-8。
在尝试参数时,建议先对比较重要的参数随机取样,并尝试尽可能多的组合。当寻找到参数比较合适的范围后,对随机取样范围进一步细化,从而寻找更加合适的参数范围。
在搜索参数范围时,需要选择合适的尺度,例如学习因子可以在log域上搜索,而Momentum参数β可以对1 - β在log域上搜索。
训练模型的两种方式:
(1) 训练单个模型:没有足够的计算资源,针对单个模型,不断调整参数进行训练。
(2) 训练多个模型:拥有足够的计算资源,设置多个超参数,同时训练多个模型,选取最优的参数。
2 批量归一化(BN, Batch Normalization)
BN算法的思路就是在前向传播的过程中,对每一层的z(1), z(2), …, z(m)进行归一化,从而提高下一层的计算效率。具体如下:
μ=1m∑iz(i)σ2=1m∑i(zi−μ)2z(i)norm=z(i)−μσ2+ε√(1)
式中,ε为小量。由于各个隐含层的分布可能不同,需要作如下修正:
z~(i)=γz(i)norm+β(2)
通过设置不同的γ和β,就可以设置不同的隐含层分布。具体流程如下:
x→z[1]→z~[1]→a[1]→z[2]→z~[2]→a[2]→⋯(3)
如果采用BN算法,每次对Z[l]归一化的过程中,实际会将b[l]项减去,因此可以忽略b[l]项,即前向传播写成:
z[l]=W[l]a[l−1]→z[l]norm→z~[l](4)
采用mini-batch + BN算法的具体流程如下:
fort=1,...,num_minibatches:computeforwardpropagationonX{t},ineachhiddenlayer,useBNtoreplacez[l]withz~[l],usebackwardpropagationtocomputedW[l],dβ[l],dγ[l],updateparameters:⎧⎩⎨⎪⎪⎪⎪W[l]=W[l]−αdW[l]β[l]=β[l]−αdβ[l]γ[l]=γ[l]−αdγ[l](5)
采用BN算法,由于各隐含层的均值和方差已经确定,训练更加受到后面层的影响,前面层的影响较小。同时,BN算法在中引入了一些噪声,与dropout具有类似的效果,因此具有一定的正则化效果,能够提升训练的鲁棒性。不过,不要将BN当作一种正则化来使用,而是当作归一化算法来加速训练。
在训练时采用多个样本训练,但是在测试时可能会选用单个样本来测试,所以需要对均值μ和方差σ2进行估计。例如,对于l层,对于第t个mini-batch的样本X{t},采用BN算法可以得到μ{t}[l],然后使用指数加权平均来估计均值μ的平均值,同样可以得到估计的方差σ2的平均值。
3 Softmax回归
Softmax回归可以对多个类别中的分类进行预测。如果有C种类别,分类标签即为0 ~ C – 1,输出y的维度为(C, 1)。如果C = 2,softmax回归就等同于逻辑回归。
对于第L层,仍然有:
z[l]=W[l]a[l−1]+b[l](6)
不过激活函数与逻辑回归不同:
t=ez[l],a[l]=ez[l]∑j=1Cti(7)
损失函数可以写成:
L(y^,y)=−∑j=1Cyjlogy^j(8)
则代价函数为:
J=1m∑i=1mL(y^(i),y(i))(9)
反向传播过程中有:
dz[L]=y^−y(10)
4 深度学习框架TensorFlow
目前,有多个深度学习框架,如Caffe/Caffe2、CNTK、DL4J、Keras、Lasagne、Mxnet、PaddlePaddle、TensorFlow、Theano、Torch。
选择深度学习框架:编程简单、运行速度快、开源,TensorFlow就是一个十分好用的深度学习框架,下面熟悉一些简单的用法。
在TensorFlow中执行程序,主要有以下几个步骤:
(1) 创建变量Tensors;
(2) 建立Tensors之间的关联;
(3) 初始化Tensors,init = tf.global_variables_initializer();
(4) 创建Session;
(5) 运行Session以执行以上的Tensors。
采用TensorFlow实现损失函数:
Loss=L(y^,y)=(y^−y)2(11)
代码如下:

Placeholder可以在session运行阶段,利用feed_dict的字典结构来提供数据,使用如下:

5 TensorFlow构建DNN代码实现
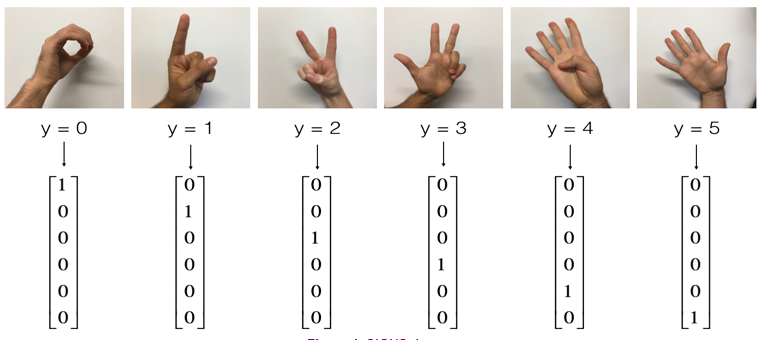
案例:对手势进行分类,总共有6种类别如下。训练集总共1080张图片,每种类别180张;测试集总共120张图片,每种类别20张。采用3层神经网络Linear -> ReLU -> Linear -> ReLU -> Linear -> Softmax,各层单元数分别为25、12、6。
5.1 创建placeholder
先创建输入变量X和Y的placeholder,核心代码如下:

5.2 参数初始化initialize_parameters
采用3层神经网络,各层单元数分别为25、12、6,对W和b进行初始化,W采用xavier初始化tf.contrib.layers.xavier_initializer(seed),b采用tf.zeros_initializer()初始化为0,核心代码如下:

5.3 前向传播forward_propagation
实现3层神经网络的前向传播,a = tf.nn.relu(z)实现ReLU函数,核心代码如下:

5.4 计算代价函数compute_cost
采用tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits = …, labels = …))计算代价函数,注意先要采用tf.transpose()对Z[3]和Y转置,核心代码如下:

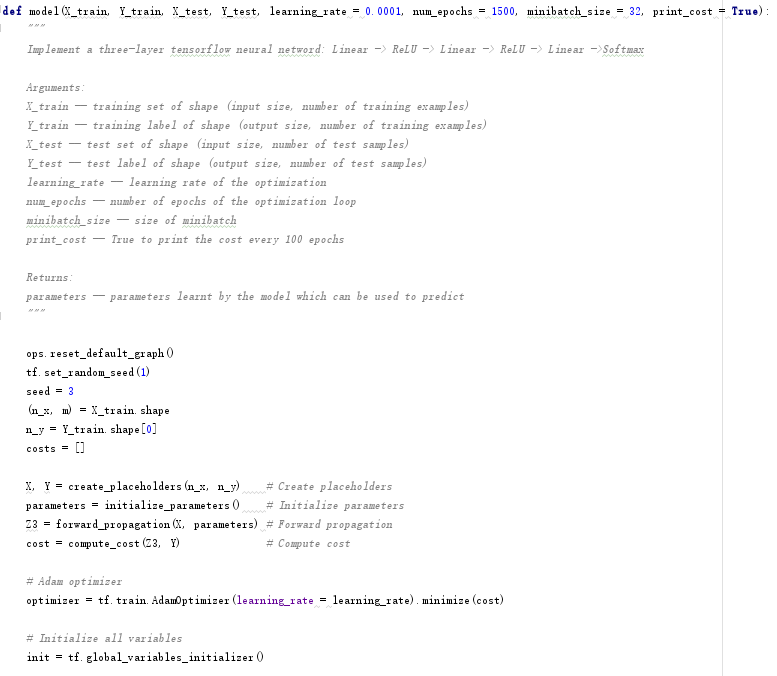
5.5 模型构建model
采用Adam算法进行梯度下降:
optimizer = tf.train.AdamOptimizer(learning_rate = learning_rate).minimize(cost)
然后进行反向传播:
_ , minibatch_cost = sess.run([optimizer, cost], feed_dict = {X: minibatch_X, Y: minibatch_Y})
构建模型的核心代码如下:

5.6 测试
测试核心代码如下:

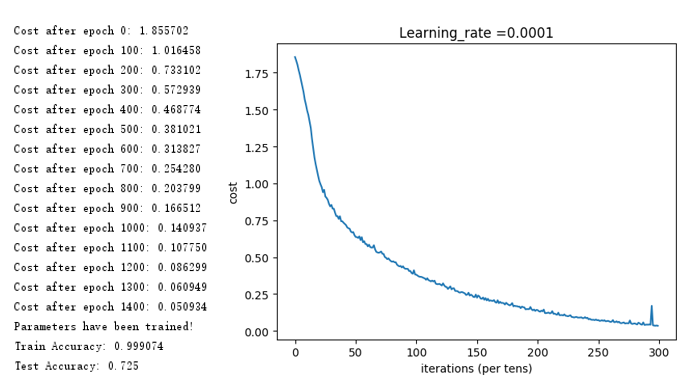
得到如下结果,可以看出,训练得到了99.9%的准确率,测试准确率为71.7%,说明模型过拟合,可以通过L2或者Dropout正则化来缓解过拟合问题。
代码下载地址:https://gitee.com/tuzhen301/Coursera-deeplearning.ai2-3















 5218
5218











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









