






a. 配置信息放到文件中,程序启动时导入,或者在程序运行过程中监控文件的修改重新导入配置文件
b. 公司或者部门范围内构建统一的配置管理系统,应用通过API获取配置服务。
通过配置文件管理配置信息的方式存在一些问题,主要有:
1.部署和更新成本高
当前一个互联网服务常常部署在多台机器上,一个配置的修改,常常涉及到多台机器的修改,运维成本高
2.管理成本高
从开发到上线,我们常常有多个环境,例如开发、测试、预发、线上等。
不同的环境的切换,都需要人力手动修改,成本较高,特别涉及到多个team合作的时候,更容易出现问题,更有甚者将一些线下环境的配置带到线上。这种case也有遇到过。
为此,当公司的服务到达一定规模的时候,构建统一的配置管理系统显得很有必要!
一个配置信息管理系统应该具备的功能包括:
1.提供交互式的配置管理,允许用户对项目的配置进行增删改查。
2.提供统一的配置请求和监听API
当然,在此基础上,一个配置管理系统在稳定性和可靠性要求极高,毕竟,配置服务一旦出现问题,影响是灾难性的!
在此介绍两种不同的构建配置系统的思路
1. Diamond
diamond是淘宝内部使用的一个管理持久配置的系统,它的特点是简单、可靠、易用,目前淘宝内部绝大多数系统的配置,由diamond来进行统一管理。
diamond架构如图:
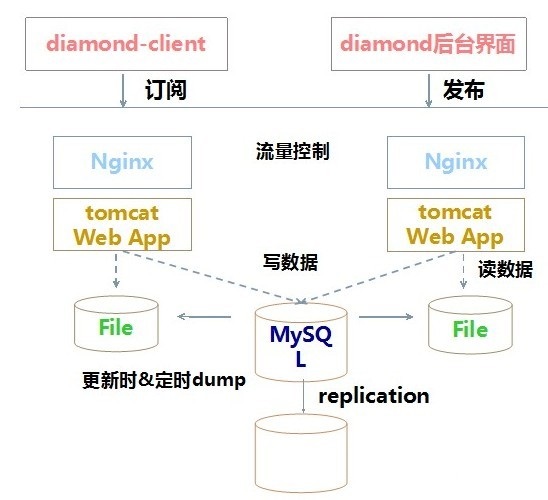
Diamond的架构非常简单,服务端采用本地文件+集中式mysql的方式保存配置信息,采用tomcat作为运行容器,nginx作为流量控制。
Diamond是典型的集中式设计思想,为保证可用性,其采取的策略包括:
1)diamond-server将配置数据存储在mysql和本地文件中,mysql中为绝对正确的数据,本地文件和mysql容忍一定程度的不一致。用户请求数据时,访问的是Server的本地文件。
2)client每次从server获取到数据后,都会将数据保存在本地文件系统,当整个Server集群不可用时,使用本地数据。
更多Dimond的信息可以参考reference。Dimond已经开源,地址是: http://code.taobao.org/p/diamond/src/
2.基于zookeeper构建
ZooKeeper是Apache Hadoop的一个子项目,其实现的功能与Google的Chubby基本一致,主要是用来解决分布式应用中经常遇到的一些数据管理问题,如:统一命名服务、状态同步服务、集群管理、分布式应用配置项的管理等。
基于zookeeper构建架构图如下所示:
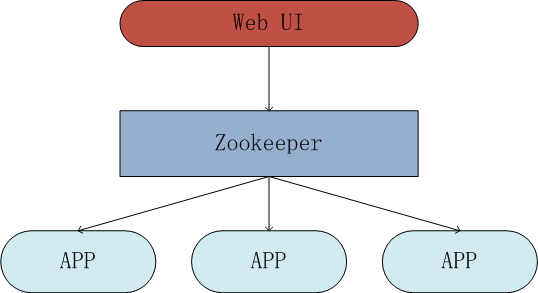
Web UI:用户交互界面,用户可以进行配置的“增删改查”
Zookeeper:配置信息存储中心。负责管理配置数据,配置数据并更时通知相应观察者。
APP:具体应用,向zookeeper请求配置信息,监听配置信息变更
基于zookeeper构建配置管理系统由于zookeeper本身的特点有效的保证了一致性和可靠性!
数据持久性
Diamond主要针对的是持久数据,这些数据有个共同的特点是:集群中一批机器都会使用,但是数据的更新频率不大,且希望diamond能够永久存储。
ZooKeeper即可以存储持久数据,也可以存储非持久数据。持久数据和diamond中的持久数据都类似,所谓的非持久数据是指这些数据的生命周期和数据创建者的会话生命周期绑定,一旦会话结束,那么这些非持久数据也会被清除。
推拉模型
本质上,两个产品都是“拉”模式的,即都是通过客户端自己去服务器获取最新数据。具体实现上,两个产品分别如下:
在Diamond中,客户端每隔15s轮询服务器,比对数据是否更新,从而获取最新数据。
在ZooKeeper中,则是通过客户端对相应的数据path注册Watcher,当数据有更新的时候,服务器会有事件通知,注意,这个通知仅仅是告诉客户端对应的数据有更新了,具体数据内容需要客户端根据自己的情况来决定是否需要获取最新数据。
因此在实时性方面,ZooKeeper比Diamond高一些。
服务器数据存储
在数据存储上,ZooKeeper和Diamond差别比较大。
首先来看下Diamond的数据存储。Diamond的数据存储以mysql数据库为中心,所有在mysql中的数据都是最新的,客户端的所有写请求,都会首先写入数据库,同时会dump数据到Server的本地文件中,所有读请求都是直接走这个静态文件。
在ZooKeeper中,所有运行时数据都是存储在内存中,客户端的所有读写操作都是针对这份内存数据来进行的。同时,内存中的数据,ZK会以快照的形式dump到指定文件中去,配合事务日志,帮助服务器在下次重启的时候,能够加载正确的数据到内存中去。
数据模型
Diamond的数据都是以行组织的,这也更便于它使用mysql来管理数据。Diamond的基本数据结构包含dataid,group和content,根据group,可以将一组相关的数据组合起来。
ZooKeeper中,使用树形结构来组织数据,每个节点类型于一个文件系统的路径,一个节点下面也可以创建多个子节点来规则一些相关的数据。
容灾
在容灾方面,diamond做得相当的完备:
1. 所有客户端的读请求,都是直接读取服务器端的本地静态文件,因此,即使数据库挂了,都不会影响diamond的读服务。而读服务在所有使用diamond的应用场景中,占到了绝大部分。
2. Diamond客户端还保存了数据的快照,客户端每次从服务器成功获取数据后,都会把这份数据保存到本地文件系统中,称为快照文件。这个快照文件是为了防止在服务器无法获取数据的时候,能够在这个快照中获取数据。
3. 客户端还会有一个容灾目录,变个容灾目录是在服务器完全不可用的时候,运维人员可以手动在这个容灾目录中创建相关目录结构的数据,diamond就就会优先从这个目录中获取数据。
4. 说到这里,我们就可以给diamond的数据获取优先级作一个总结:
首先都会从容灾目录中获取数据——无法从容灾目录获取数据的话,就通过网络到服务器请求数据——如果无法从服务器获取数据,那么就从本地的snapshot中获取数据。
接下来看看ZooKeepe的容灾,做得很少,只有以下一点:
1. ZooKeeper实现了paxos算法,有效的解决了分布式单点问题。以一个3台机器构成的集群为例,任意一台ZK挂掉,都不会影响集群的数据一致性。
总结:在容灾方面,diamond有很大的优势,也符合了diamond的稳定性要求。
数据大小
Diamond对单个数据的大小,没有严格的限制,通常2M左右的数据大小都是没有问题的。而在ZooKeeper中,由于全量数据都是存储在内存中,并且需求进行集群机器间的数据两步,所以对单个数据的大小有严格的限制,默认单个数据节点的最大数据大小是1M。
数据追加与聚合
Diamond支持对数据的追加与聚合功能,即对同一个dataid的写入操作,可以设置为追加。而ZooKeeper目前不支持,只有覆盖写。















 1964
1964

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









