









哈希表的基本概念
哈希表也叫散列表,哈希表是一种数据结构,它提供了快速的插入操作和查找操作,无论哈希表总中有多少条数据,插入和查找的时间复杂度都是为O(1)
哈希表的核心在于使用哈希函数对数据进行特征化,再通过特征值对数据进行分类存储,求特征值的函数被称为哈希函数。
哈希函数
定义
哈希函数不是一个特定的函数,哈希函数来自于自定义,不同的哈希函数对同一组数据进行处理将会得出不同的结果。
如下是一种常用的哈希函数
int hashfx(int num) //这里直接用和10取余数作为哈希函数(这个哈希函数仅限在int型数据类型时成立,其余数据类型可以考虑截断或者ASCII码)
{
return num % 10;
}哈希冲突
基于上述的函数我们将会发现
2,12,22,32,42.等数在哈希函数处理下得到的特征值是完全相同的,这样的情况被称为哈希冲突。对于哈希冲突的处理方式是多样的,主要从两个角度对这个问题进行处理
选取新的哈希函数,但是这种方法可以减少哈希冲突但是不能完全避免
寻找合适的存储方式存储哈希冲突的数据
哈希表的存储
PS:所有的构造都是基于上述的哈希函数
链式存储
使用链表的方式构建哈希表
链表的方式对空间的操作更加灵活但是在数据量确定的情况下所需的空间更大,遍历操作的时间更长。
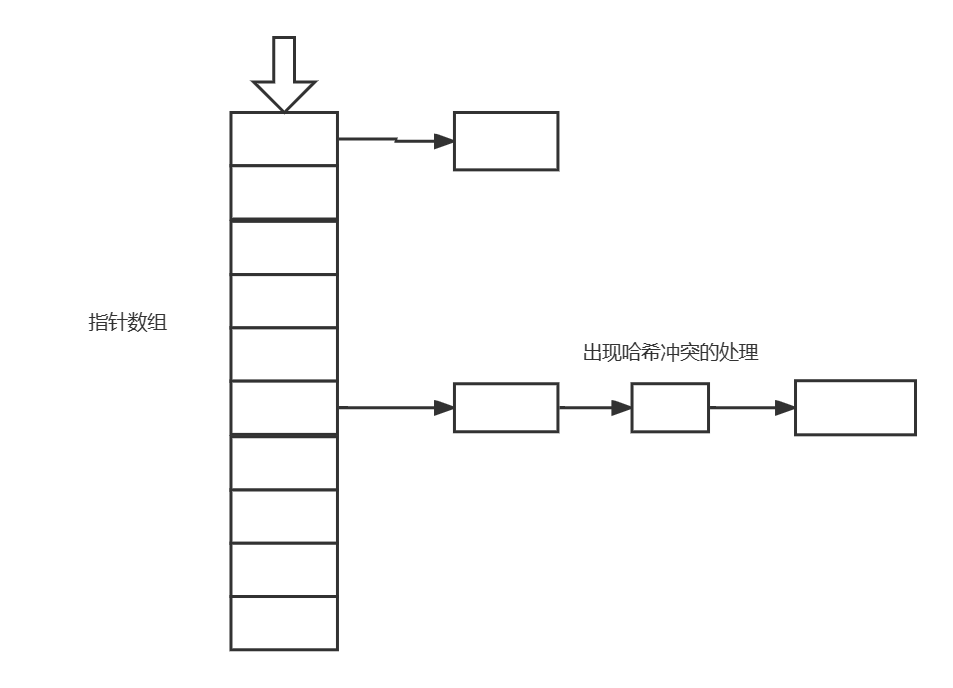
出现哈希冲突直接在链表后续插入即可。
hashmap* Createhash_1() //这里使用了一个指针数组,即指向hashmap数据类型的指针,即指向指针的指针
{
hashmap* p = (hashmap*)malloc(sizeof(hashmap) * 10); //这个二级指针实际上是指向存储空间的首位。
for (int i = 0; i < 10; i++)
{
p[i] = NULL; //指针加中括号 a[i]相当于*(a+i)
}
return p;
}线性存储结构
线性存储结构在于使用线性表存储相应的数据。
typedef struct Hash
{
type* Hashmap; //指向哈希表存储的基址
int* Every; //用于存储每一个函数值对应的数据的数量(哈希冲突)
int count; //哈希表中数据的总数
int Listsize;
}*hashmap;哈希表的构建
链式
实际在创建链表存储结构的同时已经完成了哈希表的构建
线性
void hashInit(hashmap hash)
{
hash->Hashmap = (int*)malloc(sizeof(type) * MAXSIZE); //为哈希表的存储分配初始空间
hash->Every = (int*)malloc(sizeof(int) * 10); //分配每一个结点的存储空间,并初始化为0
for (int i = 0; i < 10; i++)
{
hash->Every[i] = 0;
}
hash->count = 0;
hash->Listsize = MAXSIZE;
}向哈希表中插入数据
链式
void insert(hashmap* p)
{
cout << "请按组输入数据" << endl;
cout << "名字以#结尾" << endl;
cout << "男性为0女性为1" << endl;
cout << "使用$作为终止输入标志" << endl;
int count = 0;
char ch;
int n;
int check;
do
{
stu* middle = (stu*)malloc(sizeof(hashd));
count = 0;
do
{
cin >> ch; //读取数据
if (ch == '$')
{
break;
}
middle->name[count] = ch;
count += 1;
} while (ch != '#');
if (ch == '$')
{
break;
}
cin.get();
cin >> middle->old;
cin.get();
cin >> n;
if (n == 0)
{
middle->people = MAN;
}
else
{
middle->people = WOMAN;
}
cin.get(); //丢弃数据中的分隔字符
check = middle->old % 10; //开始插入哈希表中
if (p[check] == NULL)
{
p[check] = (hashmap)malloc(sizeof(hashd));
p[check]->next = NULL;
p[check]->a = *middle;
}
else
{
hashmap H;
H = p[check];
while (H->next != NULL)
{
H = H->next;
}
H->next= (hashmap)malloc(sizeof(hashd));
H = H->next;
H->a = *middle;
H->next = NULL;
}
} while (count>=0);
}线性
在线性存储时需要考虑数据是否超限
void hashInsert(hashmap hash) //向哈希表中插入数据
{
type node;
std::cin >> node;
int mid;
int count_2 = 0;
if (node == '#') //使用#作为终止结点
{
do
{
mid = hashfx(node);
for (int i = 0; i < mid; i++)
{
count_2 += hash->Every[i];
}
hash->count += 1;
if (hash->count >= MAXSIZE) //如果出现空间超限就扩展空间
{
hash->Hashmap = (int*)realloc(hash->Hashmap, sizeof(type) * (hash->Listsize + INCREANT)); //注意只能使用malloc才能在后续任意拓展空间
hash->Listsize += INCREANT;
}
for (int i = hash->count - 1; i >= count_2; i--) //将插入位置的移出(对哈希冲突的处理)
{
hash->Hashmap[i] = hash->Hashmap[i - 1];
}
hash->Hashmap[count_2] = node;
std::cin >> node;
} while (node != '#');
}
}哈希表的查找
实际上就是通过哈希函数来减小查找次数
以链表为例
bool searchhash(stu b, hashmap* p, int n) //从哈希表中查找数据(注意自定义的指针要限制防止越界)(即查询数据是否存在(GTA5黑历史))
{
int check;
check = b.old % 10;
hashmap middle=NULL;
if (check < n)
{
middle = p[check];
}
int CK = 0;
while (middle->next != NULL)
{
if (middle->a.old == b.old)
{
if (middle->a.people == b.people)
{
int i = 0;
while (middle->a.name[i] != '#')
{
if (middle->a.name[i] != b.name[i])
{
break;
}
i += 1;
}
}
}
}
if (middle->a.old == b.old)
{
if (middle->a.people == b.people)
{
int i = 0;
while (middle->a.name[i] != '#')
{
if (middle->a.name[i] != b.name[i])
{
break;
}
i += 1;
}
}
cout << "存在" << endl;
CK += 1;
return true;
}
if (CK == 0)
{
cout << "不存在" << endl;
return false;
}
}完整代码
链式
#include<stdio.h>
#include<iostream>
using namespace std;
typedef enum { MAN, WOMAN }Gender;
//使用学生数据来作为哈希表的测试样例
typedef struct student
{
char name[15];
int old;
Gender people;
}stu;
//使用链表创建哈希表
typedef struct HashLinkNode
{
stu a;
struct HashLinkNode* next;
}hashd,*hashmap;
//哈希函数(哈希表中最重要的东西,用于赋予哈希表特征)
int Hashf_1(const stu* a) //直接使用年龄取10余数作哈希表的特征(直接使用指针降低在运行过程中空间消耗,用const保护原数据)
{
int middle=a->old;
middle = middle % 10;
return middle;
}
hashmap* Createhash_1()
{
hashmap* p = (hashmap*)malloc(sizeof(hashmap) * 10); //这个二级指针实际上是指向存储空间的首位。
for (int i = 0; i < 10; i++)
{
p[i] = NULL; //指针加中括号 a[i]相当于*(a+i)
}
return p;
}
//向哈希表内插入数据(对于哈希冲突的处理延长侧链即可)
void insert(hashmap* p)
{
cout << "请按组输入数据" << endl;
cout << "名字以#结尾" << endl;
cout << "男性为0女性为1" << endl;
cout << "使用$作为终止输入标志" << endl;
int count = 0;
char ch;
int n;
int check;
do
{
stu* middle = (stu*)malloc(sizeof(hashd));
count = 0;
do
{
cin >> ch; //读取数据
if (ch == '$')
{
break;
}
middle->name[count] = ch;
count += 1;
} while (ch != '#');
if (ch == '$')
{
break;
}
cin.get();
cin >> middle->old;
cin.get();
cin >> n;
if (n == 0)
{
middle->people = MAN;
}
else
{
middle->people = WOMAN;
}
cin.get(); //丢弃数据中的分隔字符
check = middle->old % 10; //开始插入哈希表中
if (p[check] == NULL)
{
p[check] = (hashmap)malloc(sizeof(hashd));
p[check]->next = NULL;
p[check]->a = *middle;
}
else
{
hashmap H;
H = p[check];
while (H->next != NULL)
{
H = H->next;
}
H->next= (hashmap)malloc(sizeof(hashd));
H = H->next;
H->a = *middle;
H->next = NULL;
}
} while (count>=0);
}
bool searchhash(stu b, hashmap* p, int n) //从哈希表中查找数据(注意自定义的指针要限制防止越界)(即查询数据是否存在(GTA5黑历史))
{
int check;
check = b.old % 10;
hashmap middle=NULL;
if (check < n)
{
middle = p[check];
}
int CK = 0;
while (middle->next != NULL)
{
if (middle->a.old == b.old)
{
if (middle->a.people == b.people)
{
int i = 0;
while (middle->a.name[i] != '#')
{
if (middle->a.name[i] != b.name[i])
{
break;
}
i += 1;
}
}
}
}
if (middle->a.old == b.old)
{
if (middle->a.people == b.people)
{
int i = 0;
while (middle->a.name[i] != '#')
{
if (middle->a.name[i] != b.name[i])
{
break;
}
i += 1;
}
}
cout << "存在" << endl;
CK += 1;
return true;
}
if (CK == 0)
{
cout << "不存在" << endl;
return false;
}
}
void DistoryLinknode(hashmap p) //用于销毁支链(实际上就是销毁一个链表)
{
hashmap middle_1=p; //指向当前结点释放空间
hashmap middle_2; //记录下一个结点位置
while (middle_1->next != NULL)
{
middle_2 = middle_1->next;
free(middle_1);
middle_1 = middle_2;
}
if (middle_1->next = NULL)
{
free(middle_1);
}
p = NULL;
}
void Distoryhash(hashmap* a,int n)
{
for (int i=0; i < 10; i++)
{
if (a == NULL)
{
cout << "成功销毁哈希表" << endl;
}
else
{
for (int i = 0; i < n; i++)
{
if (a[i] != NULL)
{
DistoryLinknode(a[i]);
}
}
cout << "成功销毁哈希表" << endl;
}
}
}
int main()
{
hashmap* hashmap_1;
hashmap_1=Createhash_1();
insert(hashmap_1);
stu a1 =
{
{'n'},
15,
MAN
};
bool BO;
BO=searchhash(a1, hashmap_1, 10);
Distoryhash(hashmap_1,10);
}
线性
#include<iostream>
#include<vector>
#include<string>
const int MAXSIZE = 100;
const int INCREANT = 10;
typedef int type;
//线性存储哈希表的好处在于对于空间明显更加节省,同时线性存储的找寻遍历相对更快但是,实现相对于链表更加繁琐,同时在出现哈希冲突时需要操作的数据量大,同时在处理复杂数据类型时会有比较大的劣势。
typedef struct Hash
{
type* Hashmap; //指向哈希表存储的基址
int* Every; //用于存储每一个函数值对应的数据的数量(哈希冲突)
int count; //哈希表中数据的总数
int Listsize;
}*hashmap;
int hashfx(int num) //这里直接用和10取余数作为哈希函数(这个哈希函数仅限在int型数据类型时成立,其余数据类型可以考虑截断或者ASCII码)
{
return num % 10;
}
void hashInit(hashmap hash)
{
hash->Hashmap = (int*)malloc(sizeof(type) * MAXSIZE); //为哈希表的存储分配初始空间
hash->Every = (int*)malloc(sizeof(int) * 10); //分配每一个结点的存储空间,并初始化为0
for (int i = 0; i < 10; i++)
{
hash->Every[i] = 0;
}
hash->count = 0;
hash->Listsize = MAXSIZE;
}
void hashInsert(hashmap hash) //向哈希表中插入数据
{
type node;
std::cin >> node;
int mid;
int count_2 = 0;
if (node == '#') //使用#作为终止结点
{
do
{
mid = hashfx(node);
for (int i = 0; i < mid; i++)
{
count_2 += hash->Every[i];
}
hash->count += 1;
if (hash->count >= MAXSIZE) //如果出现空间超限就扩展空间
{
hash->Hashmap = (int*)realloc(hash->Hashmap, sizeof(type) * (hash->Listsize + INCREANT)); //注意只能使用malloc才能在后续任意拓展空间
hash->Listsize += INCREANT;
}
for (int i = hash->count - 1; i >= count_2; i--) //将插入位置的移出(对哈希冲突的处理)
{
hash->Hashmap[i] = hash->Hashmap[i - 1];
}
hash->Hashmap[count_2] = node;
std::cin >> node;
} while (node != '#');
}
}
bool hashfind(hashmap hash, type n)
{
int mid;
int count0 = 0;
int check = 0;
mid = hashfx(n);
for (int i = 0; i < mid; i++)
{
count0 += hash->Every[i];
}
for (int i = count0; i <= count0 + hash->Every[mid]; i++)
{
if (hash->Hashmap[i] == n)
{
check += 1;
break;
}
}
if (check > 0)
{
return true;
}
else
{
return false;
}
}
int main()
{
}















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









