







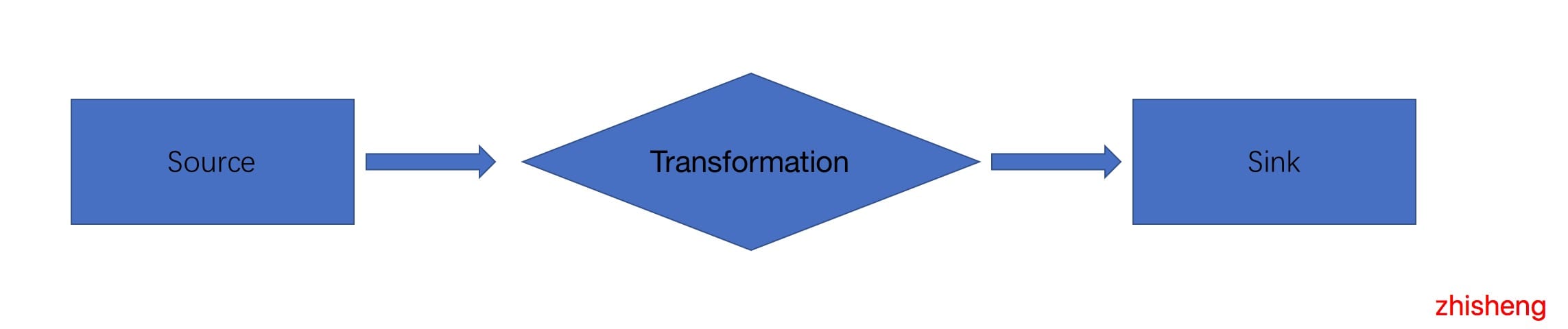
在 Flink 应用程序中,无论你的应用程序是批程序,还是流程序,都是上图这种模型,有数据源(source),有数据下游(sink),我们写的应用程序多是对数据源过来的数据做一系列操作,总结如下。
Source: 数据源,Flink 在流处理和批处理上的 source 大概有 4 类:基于本地集合的 source、基于文件的 source、基于网络套接字的 source、自定义的 source。自定义的 source 常见的有 Apache kafka、Amazon Kinesis Streams、RabbitMQ、Twitter Streaming API、Apache NiFi 等,当然你也可以定义自己的 source。
Transformation: 数据转换的各种操作,有 Map / FlatMap / Filter / KeyBy / Reduce / Fold / Aggregations / Window / WindowAll / Union / Window join / Split / Select / Project 等,操作很多,可以将数据转换计算成你想要的数据。
Sink: 接收器,Sink 是指 Flink 将转换计算后的数据发送的地点 ,你可能需要存储下来。Flink 常见的 Sink 大概有如下几类:写入文件、打印出来、写入 Socket 、自定义的 Sink 。自定义的 sink 常见的有 Apache kafka、RabbitMQ、MySQL、Elast

 订阅专栏 解锁全文
订阅专栏 解锁全文
















 3164
3164











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











