








摘要:
Cross entropy is the most widely used loss function for supervised training of image classification models. In this paper, we propose a novel training methodology that consistently outperforms cross entropy on supervised learning tasks across different architectures and data augmentations. We modify the batch contrastive loss,which has recently been shown to be very effective at learning powerful representations in the self-supervised setting. We are thus able to leverage label information more effectively than cross entropy. Clusters of points belonging to the same class are pulled together in embedding space, while simultaneously pushing apart clusters of samples from different classes. In addition to this, we leverage key ingredients such as large batch sizes and normalized embeddings, which have been shown to benefit self-supervised learning. On both ResNet-50 and ResNet-200, we outperform cross entropy by over 1%, setting a new state of the art number of 78.8% among methods that use AutoAugment data augmentation. The loss also shows clear benefits for robustness to natural corruptions on standard benchmarks on both calibration and accuracy. Compared to cross entropy, our supervised contrastive loss is more stable to hyperparameter settings such as optimizers or data augmentations.
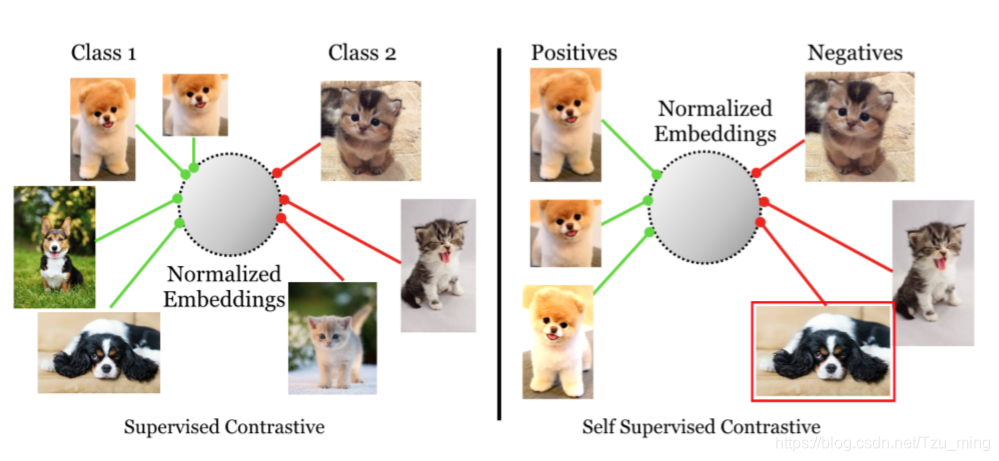
有监督方法vs自监督方法 的对比损失:
-
supervised contrastive loss(左),将一类的positive与其他类的negative进行对比(因为提供了标签), 来自同一类别的图像被映射到低维超球面中的附近点。
-
self-supervised contrastive loss(右),未提供标签。因此,positive是通过作为给定样本的数据增强生成的,negative是batch中随机采样的。这可能会导致false negative(如右下所示),可能无法正确映射,导致学习到的映射效果更差。
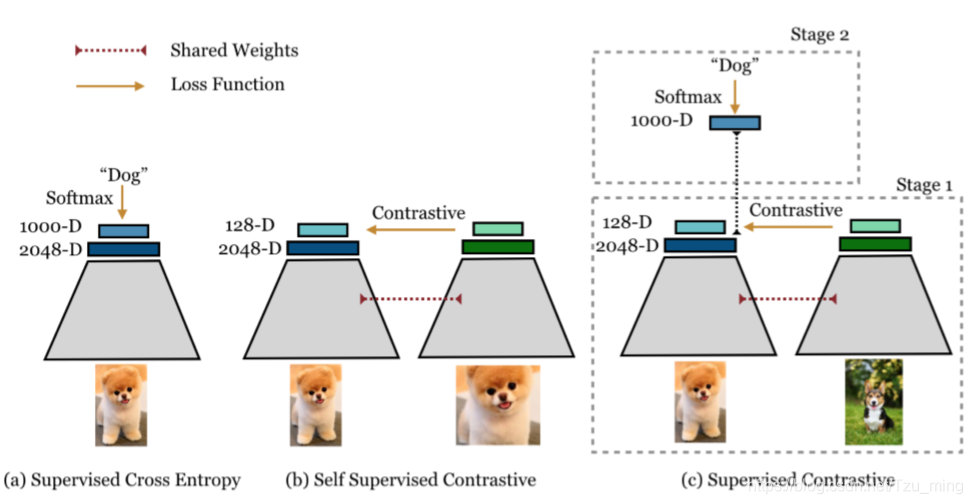
论文核心点:
-
其基于目前常用的contrastive loss提出的新的loss,(但是这实际上并不是新的loss,不是取代cross entropy的新loss,更准确地说是一个新的训练方式)
-
contrastive loss包括两个方面:1 是positive pair, 来自同一个训练样本 通过数据增强等操作 得到的两个 feature 构成, 这两个feature会越来越接近, 2 是negative pair, 来自不同训练样本的 两个feature 构成, 这两个feature 会越来越远离。 本文不同之处在于对一个训练样本(文中的anchor)考虑了多对positive pair,原来的contrastive learning 只考虑一个。
-
其核心方法是两阶段的训练。如上图所示。 从左向右分别是监督学习,自监督对比学习,和本文的监督对比学习。 其第一阶段: 通过已知的label来构建contrastive loss中的positive 和negative pair。 因为有label,所以negative pair 不会有false negative(见图1解释)。 其第二阶段: 冻结主干网络,只用正常的监督学习方法,也就是cross entropy 训练最后的分类层FC layer。
实验方面,主要在ImageNet上进行了实验,通过accuracy验证其分类性能,通过common image corruption 验证其鲁棒性。
Extension:
这里有一个YouTube上的讲解视频
https://www.youtube.com/watch?v=MpdbFLXOOIw
原文来自:CVN计算机视觉















 4264
4264











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









