







kohya-ss/sd-scripts搭建Flux Lora训练环境
文本主要阐述如何使用 kohya-ss/sd-scripts代码仓库,搭建一个Flux lora训练环境,当然可以训练Flux基础模型(finetune)。
作者:
B站 且漫CN | https://space.bilibili.com/306301113
拉取代码
获取代码
kohya-ss/sd-scripts github | https://github.com/kohya-ss/sd-scripts
创建工作目录
mkdir flux_lora_train
cd flux_lora_train
git clone https://github.com/kohya-ss/sd-scripts
切换到 sd3分支
cd sd-scripts
git checkout sd3
搭建Python环境
创建虚拟环境,使用python 3.10
python3.10 -m venv .venv
激活环境
source ./.venv/bin/activate
配置安装包
pip3 install torch==2.4.0 torchvision==0.19.0 --index-url https://download.pytorch.org/whl/cu124
cd sd-scripts
pip install -r requirements.txt
Okay, 虚拟环境搭建完整,注意有时候安装会有包冲突,建议安装时指定安装包的版本。
下载模型
下载训练时,需要的基础模型
- flux1-dev.safetensors
- t5xxl_fp16.safetensors
- clip_l.safetensors
- ae.safetensors
基础模型有fp16和fp8两个,也可以一起都下载了
cd flux_lora_train
bash download_files.sh
文件download_files.sh 的内容
#!/bin/bash
# 创建目录
mkdir -p data/models/unet
mkdir -p data/models/clip
mkdir -p data/models/vae
# 下载并发执行
wget -O data/models/unet/flux1-dev.safetensors "https://huggingface.co/black-forest-labs/FLUX.1-dev/resolve/main/flux1-dev.safetensors?download=true" &
wget -O data/models/unet/flux1-dev-fp8.safetensors "https://huggingface.co/lllyasviel/flux1_dev/resolve/main/flux1-dev-fp8.safetensors?download=true" &
wget -O data/models/clip/t5xxl_fp16.safetensors "https://huggingface.co/comfyanonymous/flux_text_encoders/resolve/main/t5xxl_fp16.safetensors?download=true" &
wget -O data/models/clip/t5xxl_fp8_e4m3fn.safetensors "https://huggingface.co/comfyanonymous/flux_text_encoders/resolve/main/t5xxl_fp8_e4m3fn.safetensors?download=true" &
wget -O data/models/clip/clip_l.safetensors "https://huggingface.co/comfyanonymous/flux_text_encoders/resolve/main/clip_l.safetensors?download=true" &
wget -O data/models/vae/flux_ae.safetensors "https://huggingface.co/black-forest-labs/FLUX.1-dev/resolve/main/ae.safetensors?download=true" &
# 等待所有后台任务完成
wait
echo "所有文件下载完成!"
训练数据准备
下载:
通过网盘分享的文件:lora_of_hanfu_girl.zip
链接: https://pan.baidu.com/s/1lFkbNTkrIHJtldmDQfvr2g?pwd=7860 提取码: 7860
mkdir -p data/train_data
cp lora_of_hanfu_girl.zip data/train_data/
unzip lora_of_hanfu_girl.zip
配置参数
下面配置一下训练时,需要修改的参数,主要是模型路径和训练数据路径,其他参数可以在自己了解的情况下做修改。
cd flux_lora_train
mkdir output & mkdir logs
accelerate launch --num_cpu_threads_per_process=2 ./sd-scripts/flux_train_network.py \
--pretrained_model_name_or_path="./data/models/unet/flux1-dev.safetensors" \
--ae="./data/models/vae/flux-ae.sft" \
--clip_l="./data/models/clip/clip_l.safetensors" \
--t5xxl="./data/models/clip/t5xxl_fp16.safetensors" \
--output_dir="./output" \
--logging_dir="./logs" \
--train_data_dir="./data/train_data/lora_of_hanfu_girl" \
--max_train_epochs=5 \
--learning_rate=1e-5 \
--output_name=flux-test-lora24G \
--save_every_n_epochs=1 \
--save_precision=bf16 \
--seed=1026 \
--max_token_length=225 \
--caption_extension=.txt \
--vae_batch_size=4 \
--apply_t5_attn_mask \
--discrete_flow_shift=3.185 \
--timestep_sampling=flux_shift \
--sigmoid_scale=1 \
--model_prediction_type=raw \
--cache_text_encoder_outputs \
--cache_text_encoder_outputs_to_disk \
--sdpa \
--train_batch_size=2 \
--resolution=1024,1024 \
--enable_bucket \
--min_bucket_reso=256 \
--max_bucket_reso=2048 \
--bucket_no_upscale \
--save_model_as=safetensors \
--clip_skip=2 \
--network_dim=32 \
--network_alpha=32 \
--persistent_data_loader_workers \
--cache_latents \
--cache_latents_to_disk \
--gradient_checkpointing \
--optimizer_type=PagedAdamW8bit \
--optimizer_args weight_decay=0.01 betas=0.9,0.95 \
--unet_lr=8e-4 \
--text_encoder_lr=1e-5 \
--keep_tokens=1 \
--fp8_base_unet \
--mixed_precision=bf16 \
--network_module=networks.lora_flux \
--gradient_accumulation_steps=1 \
--lr_scheduler=cosine_with_min_lr \
--lr_scheduler_num_cycles=2 \
--lr_decay_steps=0.5 \
--lr_scheduler_min_lr_ratio=0.1
训练时,每一轮次或者每个steps步数,输出一张测试图
--sample_every_n_epochs=1 \
--sample_prompts="/work/stable-diffusion-webui-docker/data/models/prompts.txt" \
--sample_every_n_steps=1000
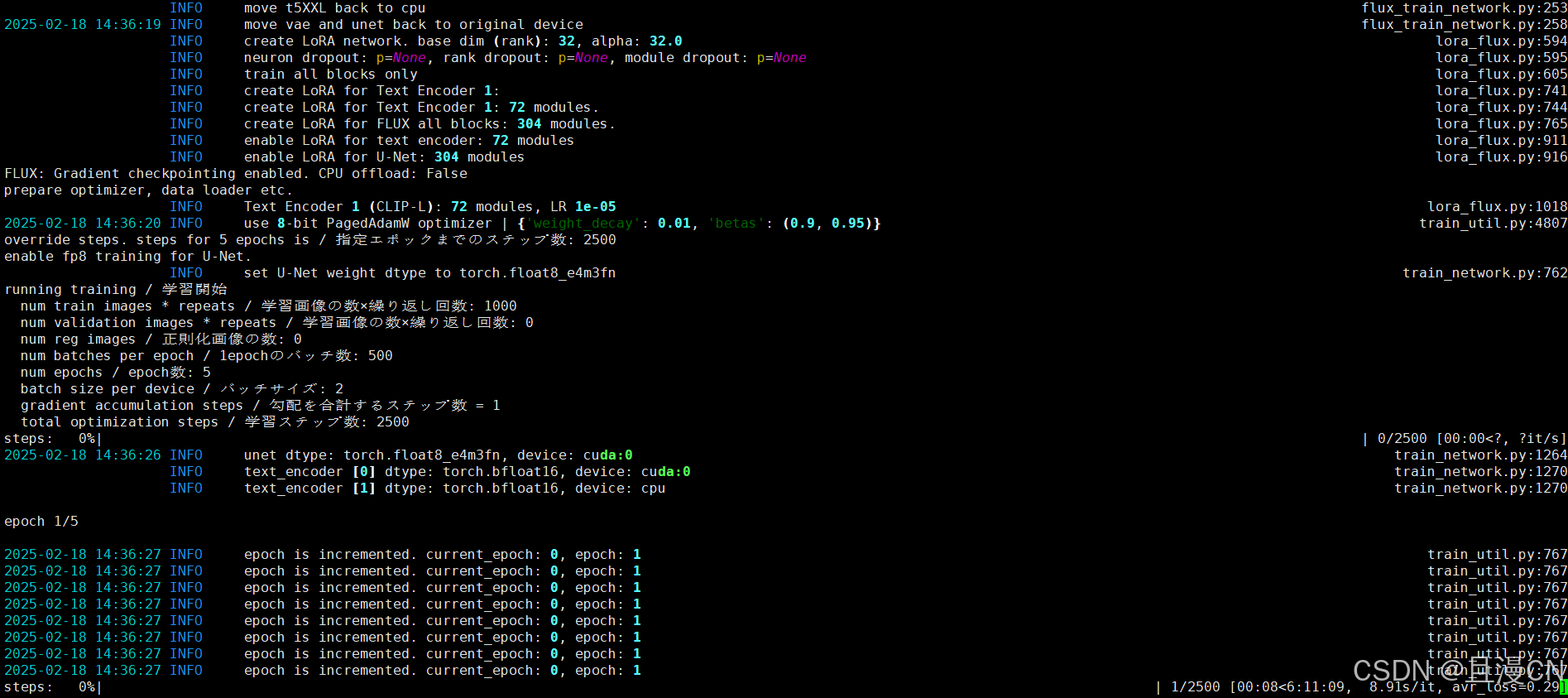
训练中
全部参数参考
usage: flux_train_network.py [-h] [--console_log_level {DEBUG,INFO,WARNING,ERROR,CRITICAL}] [--console_log_file CONSOLE_LOG_FILE] [--console_log_simple] [--v2] [--v_parameterization]
[--pretrained_model_name_or_path PRETRAINED_MODEL_NAME_OR_PATH] [--tokenizer_cache_dir TOKENIZER_CACHE_DIR]
[--num_last_block_to_freeze NUM_LAST_BLOCK_TO_FREEZE] [--train_data_dir TRAIN_DATA_DIR] [--cache_info] [--shuffle_caption]
[--caption_separator CAPTION_SEPARATOR] [--caption_extension CAPTION_EXTENSION] [--caption_extention CAPTION_EXTENTION] [--keep_tokens KEEP_TOKENS]
[--keep_tokens_separator KEEP_TOKENS_SEPARATOR] [--secondary_separator SECONDARY_SEPARATOR] [--enable_wildcard] [--caption_prefix CAPTION_PREFIX]
[--caption_suffix CAPTION_SUFFIX] [--color_aug] [--flip_aug] [--face_crop_aug_range FACE_CROP_AUG_RANGE] [--random_crop] [--debug_dataset]
[--resolution RESOLUTION] [--network_multiplier NETWORK_MULTIPLIER] [--cache_latents] [--vae_batch_size VAE_BATCH_SIZE] [--cache_latents_to_disk]
[--enable_bucket] [--min_bucket_reso MIN_BUCKET_RESO] [--max_bucket_reso MAX_BUCKET_RESO] [--bucket_reso_steps BUCKET_RESO_STEPS] [--bucket_no_upscale]
[--token_warmup_min TOKEN_WARMUP_MIN] [--token_warmup_step TOKEN_WARMUP_STEP] [--alpha_mask] [--dataset_class DATASET_CLASS]
[--caption_dropout_rate CAPTION_DROPOUT_RATE] [--caption_dropout_every_n_epochs CAPTION_DROPOUT_EVERY_N_EPOCHS]
[--caption_tag_dropout_rate CAPTION_TAG_DROPOUT_RATE] [--reg_data_dir REG_DATA_DIR] [--in_json IN_JSON] [--dataset_repeats DATASET_REPEATS]
[--output_dir OUTPUT_DIR] [--output_name OUTPUT_NAME] [--huggingface_repo_id HUGGINGFACE_REPO_ID] [--huggingface_repo_type HUGGINGFACE_REPO_TYPE]
[--huggingface_path_in_repo HUGGINGFACE_PATH_IN_REPO] [--huggingface_token HUGGINGFACE_TOKEN] [--huggingface_repo_visibility HUGGINGFACE_REPO_VISIBILITY]
[--save_state_to_huggingface] [--resume_from_huggingface] [--async_upload] [--save_precision {None,float,fp16,bf16}]
[--save_every_n_epochs SAVE_EVERY_N_EPOCHS] [--save_every_n_steps SAVE_EVERY_N_STEPS] [--save_n_epoch_ratio SAVE_N_EPOCH_RATIO]
[--save_last_n_epochs SAVE_LAST_N_EPOCHS] [--save_last_n_epochs_state SAVE_LAST_N_EPOCHS_STATE] [--save_last_n_steps SAVE_LAST_N_STEPS]
[--save_last_n_steps_state SAVE_LAST_N_STEPS_STATE] [--save_state] [--save_state_on_train_end] [--resume RESUME] [--train_batch_size TRAIN_BATCH_SIZE]
[--max_token_length {None,150,225}] [--mem_eff_attn] [--torch_compile]
[--dynamo_backend {eager,aot_eager,inductor,aot_ts_nvfuser,nvprims_nvfuser,cudagraphs,ofi,fx2trt,onnxrt,tensort,ipex,tvm}] [--xformers] [--sdpa] [--vae VAE]
[--max_train_steps MAX_TRAIN_STEPS] [--max_train_epochs MAX_TRAIN_EPOCHS] [--max_data_loader_n_workers MAX_DATA_LOADER_N_WORKERS]
[--persistent_data_loader_workers] [--seed SEED] [--gradient_checkpointing] [--gradient_accumulation_steps GRADIENT_ACCUMULATION_STEPS]
[--mixed_precision {no,fp16,bf16}] [--full_fp16] [--full_bf16] [--fp8_base] [--ddp_timeout DDP_TIMEOUT] [--ddp_gradient_as_bucket_view] [--ddp_static_graph]
[--clip_skip CLIP_SKIP] [--logging_dir LOGGING_DIR] [--log_with {tensorboard,wandb,all}] [--log_prefix LOG_PREFIX] [--log_tracker_name LOG_TRACKER_NAME]
[--wandb_run_name WANDB_RUN_NAME] [--log_tracker_config LOG_TRACKER_CONFIG] [--wandb_api_key WANDB_API_KEY] [--log_config] [--noise_offset NOISE_OFFSET]
[--noise_offset_random_strength] [--multires_noise_iterations MULTIRES_NOISE_ITERATIONS] [--ip_noise_gamma IP_NOISE_GAMMA] [--ip_noise_gamma_random_strength]
[--multires_noise_discount MULTIRES_NOISE_DISCOUNT] [--adaptive_noise_scale ADAPTIVE_NOISE_SCALE] [--zero_terminal_snr] [--min_timestep MIN_TIMESTEP]
[--max_timestep MAX_TIMESTEP] [--loss_type {l1,l2,huber,smooth_l1}] [--huber_schedule {constant,exponential,snr}] [--huber_c HUBER_C]
[--immiscible_noise IMMISCIBLE_NOISE] [--lowram] [--highvram] [--sample_every_n_steps SAMPLE_EVERY_N_STEPS] [--sample_at_first]
[--sample_every_n_epochs SAMPLE_EVERY_N_EPOCHS] [--sample_prompts SAMPLE_PROMPTS]
[--sample_sampler {ddim,pndm,lms,euler,euler_a,heun,dpm_2,dpm_2_a,dpmsolver,dpmsolver++,dpmsingle,k_lms,k_euler,k_euler_a,k_dpm_2,k_dpm_2_a}]
[--config_file CONFIG_FILE] [--output_config] [--metadata_title METADATA_TITLE] [--metadata_author METADATA_AUTHOR]
[--metadata_description METADATA_DESCRIPTION] [--metadata_license METADATA_LICENSE] [--metadata_tags METADATA_TAGS] [--prior_loss_weight PRIOR_LOSS_WEIGHT]
[--conditioning_data_dir CONDITIONING_DATA_DIR] [--masked_loss] [--deepspeed] [--zero_stage {0,1,2,3}] [--offload_optimizer_device {None,cpu,nvme}]
[--offload_optimizer_nvme_path OFFLOAD_OPTIMIZER_NVME_PATH] [--offload_param_device {None,cpu,nvme}] [--offload_param_nvme_path OFFLOAD_PARAM_NVME_PATH]
[--zero3_init_flag] [--zero3_save_16bit_model] [--fp16_master_weights_and_gradients] [--optimizer_type OPTIMIZER_TYPE] [--use_8bit_adam]
[--use_lion_optimizer] [--learning_rate LEARNING_RATE] [--max_grad_norm MAX_GRAD_NORM] [--optimizer_args [OPTIMIZER_ARGS ...]]
[--lr_scheduler_type LR_SCHEDULER_TYPE] [--lr_scheduler_args [LR_SCHEDULER_ARGS ...]] [--lr_scheduler LR_SCHEDULER] [--lr_warmup_steps LR_WARMUP_STEPS]
[--lr_decay_steps LR_DECAY_STEPS] [--lr_scheduler_num_cycles LR_SCHEDULER_NUM_CYCLES] [--lr_scheduler_power LR_SCHEDULER_POWER] [--fused_backward_pass]
[--lr_scheduler_timescale LR_SCHEDULER_TIMESCALE] [--lr_scheduler_min_lr_ratio LR_SCHEDULER_MIN_LR_RATIO]
[--optimizer_accumulation_steps OPTIMIZER_ACCUMULATION_STEPS] [--gradfilter_ema_alpha GRADFILTER_EMA_ALPHA] [--gradfilter_ema_lamb GRADFILTER_EMA_LAMB]
[--gradfilter_ma_window_size GRADFILTER_MA_WINDOW_SIZE] [--gradfilter_ma_lamb GRADFILTER_MA_LAMB] [--gradfilter_ma_filter_type {mean,sum}]
[--gradfilter_ma_warmup_false] [--dataset_config DATASET_CONFIG] [--min_snr_gamma MIN_SNR_GAMMA] [--scale_v_pred_loss_like_noise_pred]
[--v_pred_like_loss V_PRED_LIKE_LOSS] [--debiased_estimation_loss] [--weighted_captions] [--cpu_offload_checkpointing] [--no_metadata]
[--save_model_as {None,ckpt,pt,safetensors}] [--unet_lr UNET_LR] [--text_encoder_lr [TEXT_ENCODER_LR ...]] [--fp8_base_unet]
[--network_weights NETWORK_WEIGHTS] [--network_module NETWORK_MODULE] [--network_dim NETWORK_DIM] [--network_alpha NETWORK_ALPHA]
[--network_dropout NETWORK_DROPOUT] [--network_args [NETWORK_ARGS ...]] [--network_train_unet_only] [--network_train_text_encoder_only]
[--training_comment TRAINING_COMMENT] [--dim_from_weights] [--scale_weight_norms SCALE_WEIGHT_NORMS] [--base_weights [BASE_WEIGHTS ...]]
[--base_weights_multiplier [BASE_WEIGHTS_MULTIPLIER ...]] [--no_half_vae] [--skip_until_initial_step] [--initial_epoch INITIAL_EPOCH]
[--initial_step INITIAL_STEP] [--clip_l CLIP_L] [--t5xxl T5XXL] [--ae AE] [--t5xxl_max_token_length T5XXL_MAX_TOKEN_LENGTH] [--apply_t5_attn_mask]
[--cache_text_encoder_outputs] [--cache_text_encoder_outputs_to_disk] [--text_encoder_batch_size TEXT_ENCODER_BATCH_SIZE] [--disable_mmap_load_safetensors]
[--weighting_scheme {sigma_sqrt,logit_normal,mode,cosmap,none}] [--logit_mean LOGIT_MEAN] [--logit_std LOGIT_STD] [--mode_scale MODE_SCALE]
[--guidance_scale GUIDANCE_SCALE] [--guidance_rescale] [--timestep_sampling {sigma,uniform,sigmoid,shift,flux_shift}] [--sigmoid_scale SIGMOID_SCALE]
[--model_prediction_type {raw,additive,sigma_scaled}] [--discrete_flow_shift DISCRETE_FLOW_SHIFT] [--split_mode]
联系
作者:
B站 且漫CN | https://space.bilibili.com/306301113



















 1176
1176

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











