









在上一篇文章《Hadoop-2.4.1源码分析--MapReduce作业(job)提交源码跟踪》中,我介绍了Job的提交过程源码,介绍的最后一个方法是submitJobInternal(Jobjob, Cluster cluster),该方法向系统提交作业(该方法不仅设置mapper数量,还执行了一些其它操作如检查输出格式等),在该方法的第394行,涉及到如下一个方法--writeSplits(),该方法是用于切片处理并且返回map任务数的,当时碍于篇幅没有细讲,今天详细的总结一下。

进入writeSplits()方法,该方法会根据是否使用了新API选择不同的方法写,当然,此处都是使用新版API。
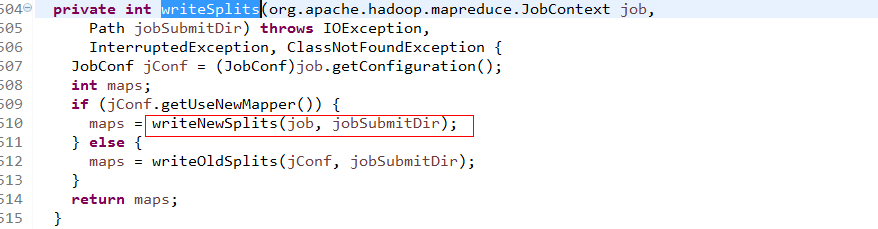
进入writeNewSplits()方法,可以看出该方法首先获取splits数组信息后,排序,将会优先处理大文件。最终返回
mapper数量。这其中又分为两部分:确定切片数量 和 写入切片信息。确定切片数量的任务交由FileInputFormat的
getSplits(job)完成,写入切片信息的任务交由JobSplitWriter.createSplitFiles(jobSubmitDir, conf,
jobSubmitDir.getFileSystem(conf), array)方法,该方法会将切片信息和SplitMetaInfo都写入HDFS中。
下面分别介绍:
一、确定切片数量
实际的mapper数量就是输入切片的数量,而切片的数量又由使用的输入格式决定,默认为TextInputFormat,该类为FileInputFormat的子类。确定切片数量的任务交由FileInputFormat的getSplits(job)完成。FileInputFormat继承自抽象类InputFormat,该类定义了MapReduce作业的输入规范,其中的抽象方法List<InputSplit> getSplits(JobContext context)定义了如何将输入分割为InputSplit,不同的输入有不同的分隔逻辑,而分隔得到的每个InputSplit交由不同的mapper处理,因此该方法的返回值确定了mapper的数量。
首先看InputFormat抽象类。InputFormat抽象类只提供了两个抽象方法,分别用于获取InputSplit和RecordReader。其中的InputSplit只是对输入文件的逻辑分割,而不是物理上将输入文件分割为块,或者说InputSplit只是指定了输入文件的某个范围输入到特定的Mapper中。而RecordReader是负责处理跨InputSplit记录的。
InputFormat为抽象类,其下有多种实现类,用于处理不同来源的数据。在实际的应用中,大多数情况都是使用FileInputFormat的子类做为输入,故重点学习FileInputFormat类。
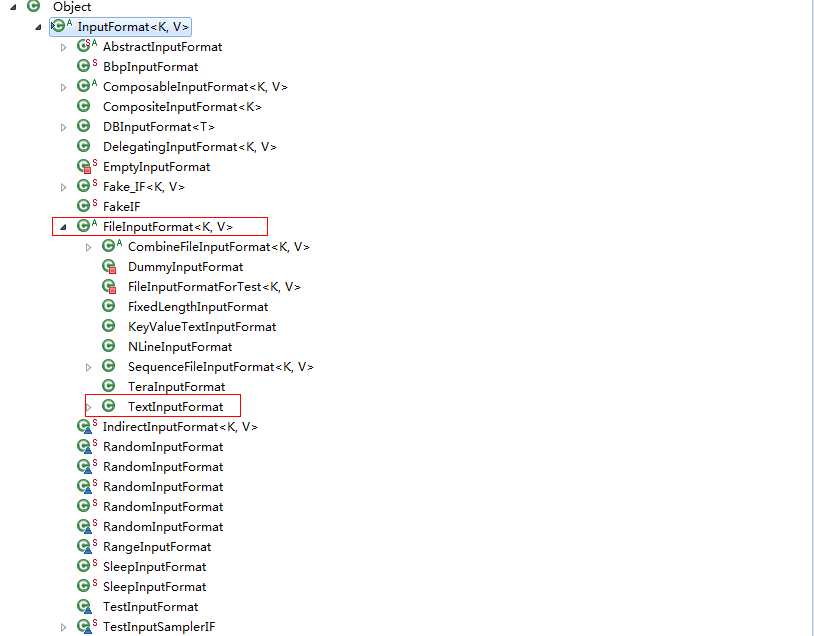
FileInputFormat的主要子类有:TextInputFormat、SequenceFileInputFormat、NLineInputFormat、KeyValueTextInputFormat、FixedLengthInputFormat和CombineFileInputFormat等。实现切片的就是
FileInputFormat.getSplits()方法,其定义如下:
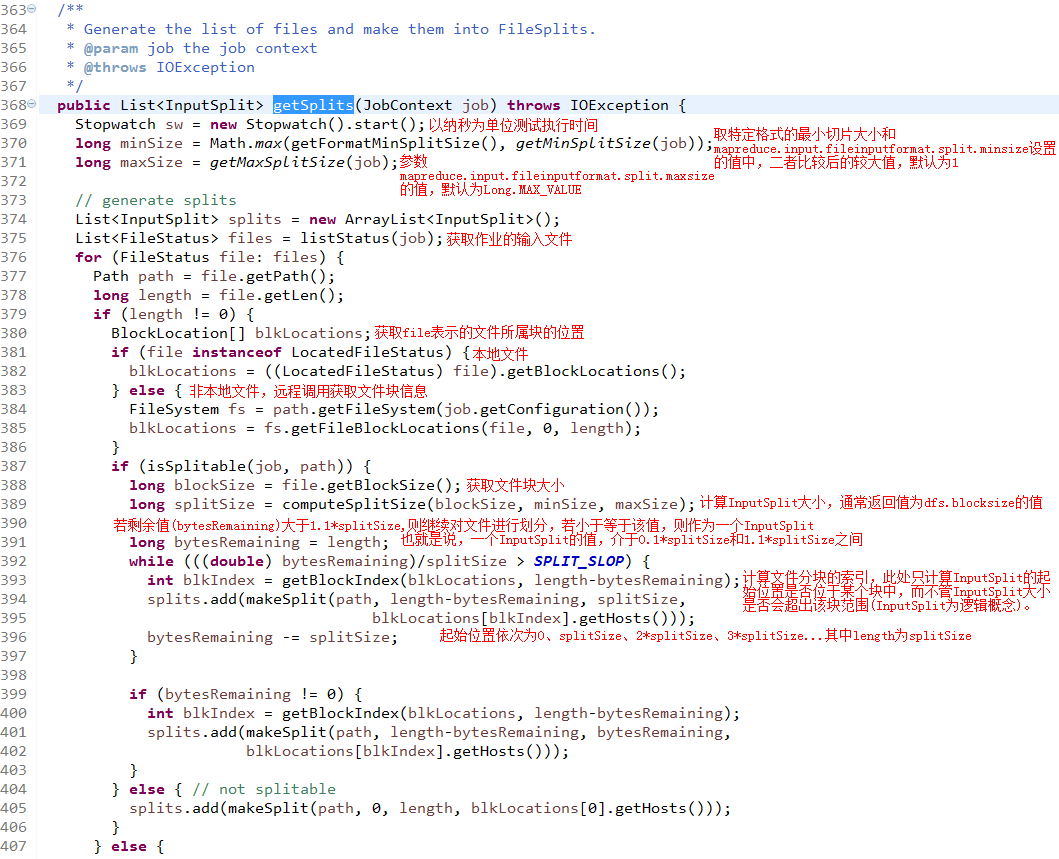
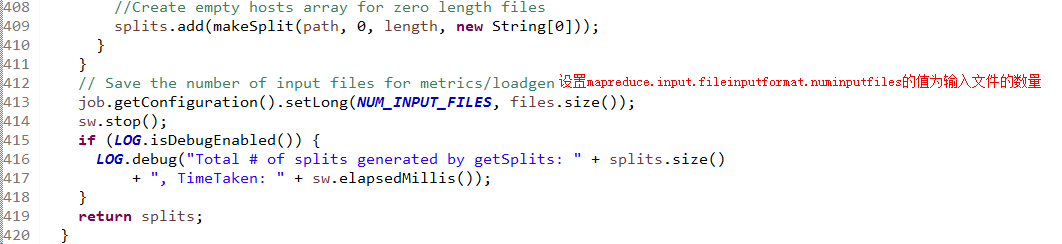
上述代码中,blockSize的值为参数dfs.blocksize的值,默认为128M。方法computeSplitSize(blockSize, minSize, maxSize)根据blockSize,minSize,maxSize确定InputSplit的大小。由此可以得知,InputSplit的大小取决于dfs.blocksize、mapreduce.input.fileinputformat.split.minsize、mapreduce.input.fileinputformat.split.maxsize和所使用的输入格式。在输入格式为TextInputFormat的情况下,且不修改InputSplit的最大值和最小值的情况,InputSplit的最终值为dfs.blocksize的值。
变量SPLIT_SLOP的值为1.1,决定了当剩余文件大小多大时停止按照变量splitSize分割文件。根据代码可知,当剩余文件小于等于1.1倍splitSize时,将把剩余的文件做为一个InputSplit,即最后一个InputSplit的大小最大为1.1倍splitSize。如果splitSize等于blocksize,则InputSplit的起始位置与相应块在文件中offset一致,但如果splitSize小于blocksize,即通过参数mapreduce.input.fileinputformat.split.maxsize控制每个InputSplit的大小,那么InputSplit的起始位置就会位于文件块的内部。上述分割InputSplit的逻辑完全是针对大小进行的,那么就会存在将一行记录划分到两个InputSplit中的可能。但上述代码并未对这种情况进行处理,这也意味着在Map阶段存在数据不完整的可能,Hadoop当然不会允许这种情况的发生,而RecordReader就负责处理这种情况,下面以LineRecordReader为例,看看Hadoop是如何处理记录跨InputSplit的。LineRecordReader中的构造方法在初始化的时候调用一次,此方法将定位InputSplit中第一个换行符的位置,并将实际读取数据的位置定位到第一个换行符之后的位置,如果是第一个InputSplit则不用如此处理。而被过滤的内容则由读取该InputSplit之前的Split的LineRecordReader负责读取,确定第一个换行符位置的代码片段为:
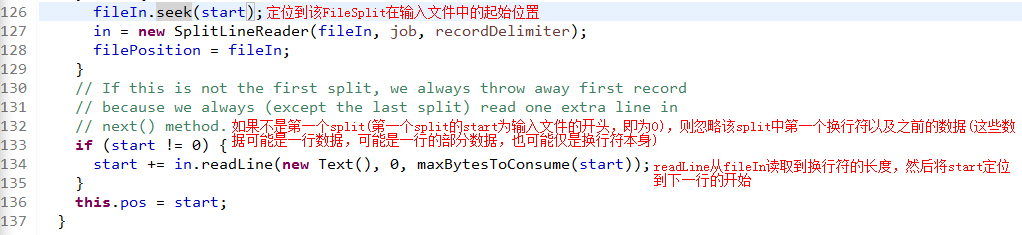
读取InputSplit内容的代码位于next()方法中,具体代码为:
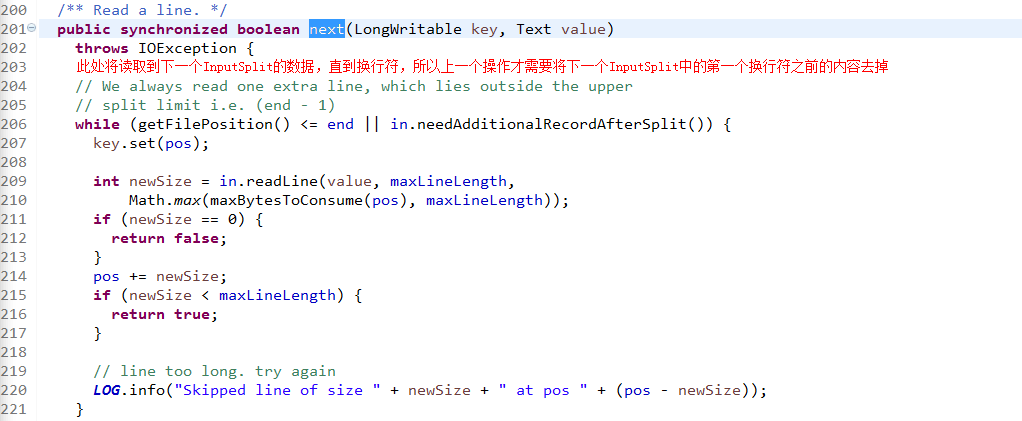
readLine()的功能是读取一行的数据到Text中,因为在分割FileSplit时是基于size的,如果一行被分割到两个split中,比如s1和s2中,在读取s1中的最后一行数据时,会一直读取到s2中的第一个换行符,这是在next()方法中实现的,而在处理s2时,则要将已经读取的数据跳过以避免重复读取,这是在构造方法中实现的。
二、写入切片信息
再次回到writeNewSplits()方法,进入JobSplitWriter.createSplitFiles(jobSubmitDir, conf,
jobSubmitDir.getFileSystem(conf), array)方法:


进入writeNewSplits()方法,它将切片数据写入切片文件,并得到切片元数据信息SplitMetaInfo数组info:
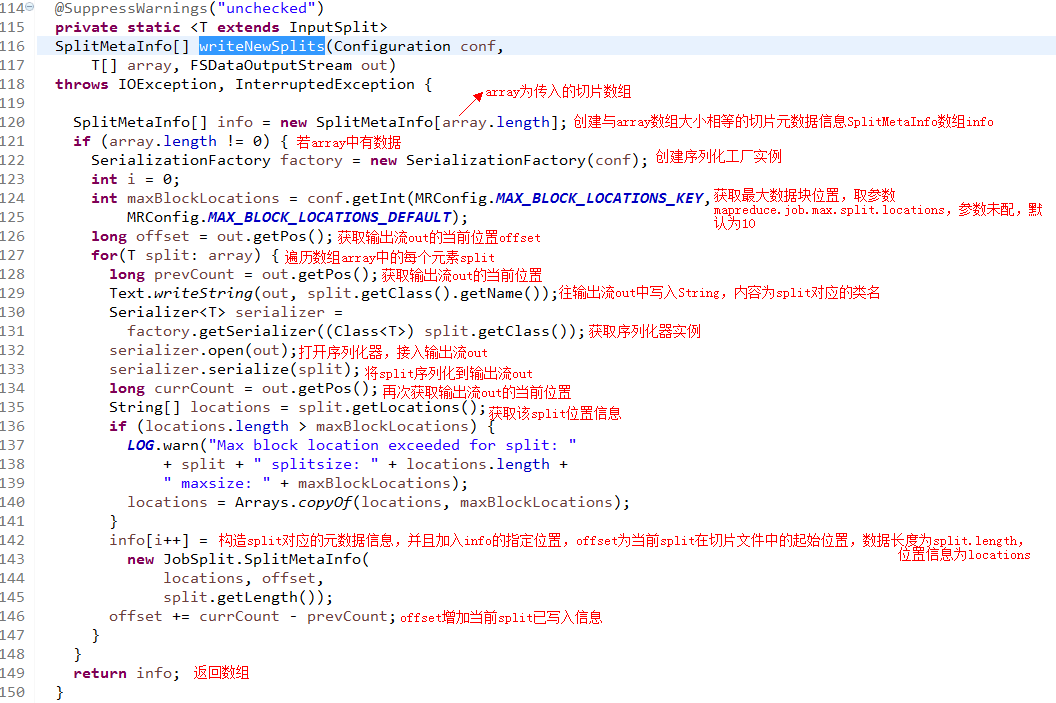
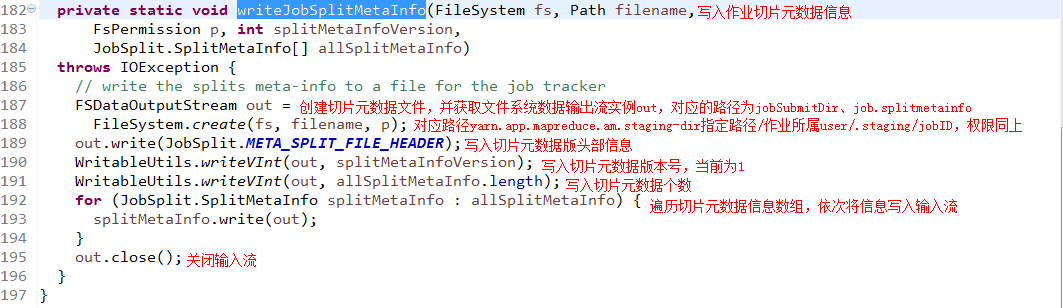
最后进入writeJobSplitMetaInfo()方法,查看分片的元数据信息文件是如何产生的:















 3204
3204











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









