







 感知器算法是1950年代末由Frank Rosenblatt提出的,用于二进制分类的监督学习算法。它是一种简单的线性分类器,尤其在处理线性可分问题时有效。在神经网络中,感知机作为单层网络,尝试通过线性分离器对两类数据进行划分。算法的核心是通过调整权重以找到最佳分类边界。如果激活值(权重与输入向量的内积)大于阈值,则输出1,否则输出0。此概念可以扩展,通过引入偏置项,使得模型更加灵活。
感知器算法是1950年代末由Frank Rosenblatt提出的,用于二进制分类的监督学习算法。它是一种简单的线性分类器,尤其在处理线性可分问题时有效。在神经网络中,感知机作为单层网络,尝试通过线性分离器对两类数据进行划分。算法的核心是通过调整权重以找到最佳分类边界。如果激活值(权重与输入向量的内积)大于阈值,则输出1,否则输出0。此概念可以扩展,通过引入偏置项,使得模型更加灵活。
感知器算法是一种用于二进制分类的监督学习算法,可以预测数字向量所表示的输入是否属于特定的类。
在机器学习的术语中,分类被认为是监督学习的实例,即,其中可观测得到正确识别的训练集,可将之用于训练学习。 相应的无监督过程被称为聚类或聚类分析,并且涉及基于固有相似性(例如,被视为多维向量空间中的向量的实例之间的距离)的某种度量将数据分组到类别中。 (维基百科)
在人工神经网络领域中,感知机也被指为单层的人工神经网络,以区别于较复杂的多层感知机(Multilayer Perceptron)。作为一种线性分类器,(单层)感知机可说是最简单的前向人工神经网络形式。尽管结构简单,感知机能够学习并解决相当复杂的问题。感知机主要的本质缺陷是它不能处理线性不可分问题。(ibid)
感知器学习算法是在1950年代后期由Frank Rosenblatt提出的。感知器算法是一种用于二进制分类的监督学习算法,可以预测数字向量所表示的输入是否属于特定的类(其将种类假定为标记+1和-1),分类器(classfier)试图通过线性分离器(sepereator)来划分这两个类。
在感知器模型中,Figure.1有三个输入,X1,X2,X3,X4,X5可以使用这些变量,并对应于二进制分类。 例如,如果匹配训练集中的正集,则否则,在这种情况下,权重允许您使用感知器来设置用于决策的数学模型,并且其指示相应输入对于输出的重要性。 例如,如果你去旅行,但是你讨厌恶劣的天气,这个时候假设决定是X1,权重分配给6,如果阈值是5,那么X1天气是最重要的因素。 其他因素对决策没有影响。 所以可以假设好天气输出1,恶劣天气输出0(Nielsen, M. A. 2015)。
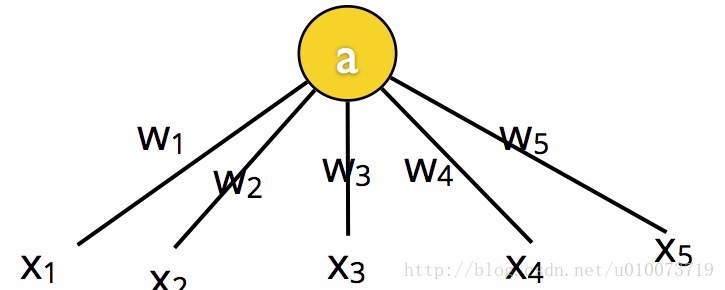
Figure. 1 model of perceptron(Bollegala, D,2017)
在该神经网络模型中a是该神经网络模型中a是activation,a = w1x1+w2x2+w3x3+w4x4+w5x5。如果a大于预定阈值θ,则神经元激发。产生输出为1或0。可得如下:
if a > θ then
output = 1
else
output = 0
其中w和x对应于权重和输入向量。 第二个变化是将阈值移动到不等式的另一侧,并将其替换为感知器的偏差b≡-threshold。 使用偏差而不是阈值,感知器的规则可以重写为以下公式:
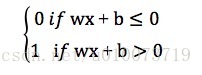
通过引入始终为ON的特征(即,x0 = 1对于所有实例),我们可以挤压偏差通过设置w0 = b将项b代入权重向量
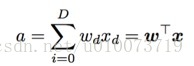
在这里我们可以将激活写为权重向量和特征向量之间的内积。 然而,我们应该记住,偏差项仍然出现在模型中。
以下是该算法的伪代码:

以下是python的实现代码:
import time
import random
import numpy
def process(userChoice):
bias = 0
train_errors = []
test_errors = [ 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 569
569

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









