







在计算机系统中,数据类型是所有数据的基本表示方法。计算机的基本功能是对数据、文字、声音、图形、图像和视频等信息进行加工处理,其中数据有两大类:一类是数值数据,如+314、-3.14、53等,有“量”的概念;另一类是非数值数据,如各种字母和符号。无论是数值数据还是非数值数据,在计算机中都是用二进制数码表示的,而文字、声音、图形、图像和视频等信息要在计算机中处理,都要事先数字化,即把文字、声音、图形、图像和视频等信息转换为二进制数码。
因此,在大数据中,数据表示是我们在数据挖掘中必须做的第一件事之一。我们可以挖掘到什么,可以说在很大程度上取决于数据表示的方法。但是,并不是所有数据挖掘任务都有一个最好的表示方法。在不考虑分类算法的前提下,不合适的表示方法会导致分类准确率的降低。因此,在正常的分类任务中,使用一系列的特征来表示数据点。
在机器学习和统计学中,特征选择 也被称为变量选择、属性选择 或变量子集选择 。它是指:为了构建模型而选择相关特征(即属性、指标)子集的过程。使用特征选择技术有三个原因:
简化模型,使之更易于被研究人员或用户理解(James, et al.,2013).
缩短训练时间 (Bermingham, etal., 2015)
改善通用性、降低过拟合(即降低方差 )
要使用特征选择技术的关键假设是:训练数据包含许多冗余 或无关 的特征,因而移除这些特征并不会导致丢失信息(Bermingham, etal., 2015)。 冗余 或无关 特征是两个不同的概念。如果一个特征本身有用,但如果这个特征与另一个有用特征强相关,且那个特征也出现在数据中,那么这个特征可能就变得多余(Guyon & Elisseeff, 2003)(Wiki)。
综上,特征是用来表示数据点的属性,也是数据挖掘的核心。它允许我们抽象数据点并学习可用于预测未知/未来数据点的规则。在数据挖掘的深度学习领域,则是专注于寻找良好的特征。
例如特征颜色可以用于表示花的特征,特征颜色的值为红色。如果学习以下规则:
if colour== red then flower= rose
则可以预测该花可能为玫瑰花,我们可以用类似的规则分类训练集中的花,也可以用来分类训练集中所没有的花。
为了易于表示,分类数据通常由一小组有限的类别组成,因此在学习数据分类规则时易于工作。但类别数量不一定很小,例如, 人们用来标记图像的标签(例如人物,位置,事件或#tags的名称)是开放集。
在这些小分类集中,如果代数未进行规则定义
rose(colour=red) orchid(colour=yellow)
比如黄色和琥珀色是相近的颜色,但是没有琥珀色相关的概念,当探测到琥珀色的时候,我们没有办法通过查看数据值来推测。因此,我们可以把黄色值定义为4,琥珀色值定义为2,当所有值都大于0时,为兰花。值小于0时,为玫瑰花。
如果在数据挖掘中必须表示分类数据,则可以将每个类别表示为向量的单独维度。如图所示:
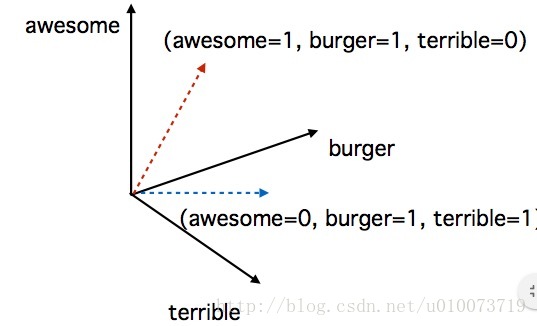
Figure.1 数据表示例子
该图就是一个二分变量的使用实例。当awesome=1 terrible=0时,汉堡为awesome;反之,汉堡terrible。
除了特征数据之外,还有数值型数据的处理也值得注意,例如,作为健身教练,编写计算BMI指数的程序时,就需要注意尽管体重和身高在数值型数据的表示上是一样的,但是由于单位的不同,实际上属于不同的维度,因此我们要考虑不同数据维度范围的差异,这样才可以根据不同的身高,不同的体重计算出可以适用于大多数人的BMI指数。
因此对于该类数据,应该使用数值归一化的方法。
方法一:[0,1]缩放法
该方法实际上是计算数据点上特征的最小值和最大值。
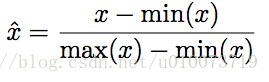
方法二:高斯归化
计算特征的平均值(μ)和标准偏差(σ),并应用以下变换:
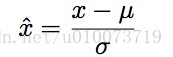
在该变换之后,每个特征将具有零均值和单位方差。
因此,比较两个特征是“更容易”的,忽略它们的绝对尺度。
Reference:
James, G.,W. Witten, T. Hastie, and R. Tibshirani. (2013). An introduction to statistical learning.
Bermingham, M. L., Pong-Wong, R., Spiliopoulou, A., Hayward, C., Rudan, I., Campbell, H., … & Haley, C. S. (2015). Application of high-dimensional feature selection: evaluation for genomic prediction in man. Scientific reports, 5.
Guyon, I., & Elisseeff, A. (2003). An introduction to variable and feature selection. Journal of machine learning research, 3(Mar), 1157-1182.
Further reading about 分类变量:
Yates, D., Moore, D. S., & Starnes, D. S. (2002). The practice of statistics: TI-83/89 graphing calculator enhanced. Macmillan.
Categorical variable
https://en.wikipedia.org/wiki/Categorical_variable#cite_note-yates-1















 2576
2576

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









