







1、 数字系统
计算机数据表示是指处理机硬件能够辨认并进行存储、传送和处理的数据表示方法。
1.1 表示方法
数制:数制即是进位计数制,它包含3个基本要素:数码、基数、位权。数码是用来表示某一种进位计算制的一组符号,如十进制数中的0、1、2、3、4、5、6、7、8、9;
1.1.1 二进制数(Binary)
与十进制数类似,二进制数的数码是用0、1两个数字符号来表示,基数为2,进位规律是“逢二进一”。
1101010=1x2^6 + 1x2^5 + 0x2^4 + 1x2^3 + 0x2^2 + 1x2^1 + 0x2^0(二进制)
= 64 + 32 + 0x16 + 8 + 0x4 + 2 + 0x1
= 106(十进制)
1.1.2 八进制数(Octonary)
在八进制数中,它的数码是用0、1、2、3、4、5、6、7八个数字符号来表示,基数是8,进位规律是“逢八进一”。(8=2^3)
3456 = 3x8^3 + 4x8^2 + 5x8^1 + 6x8^0(八进制)
=3x512 + 4x64 + 5x8 + 6x1
=1838(十进制)
1.1.3 十进制数(Decimal)
十进制数是人们十分熟悉的计数体制,它的数码是用0、1、2、3、4、5、6、7、8、9十个数字符号来表示,基数是10,进位规律是“逢十进一”。
3456 = 3x10^3 + 4x10^2 + 5x10^1 + 6x10^0
1.1.4 十六进制数(Hexadecimal)
在十六进制数中,它的数码是用0、1、2、3、4、5、6、7、8、9、A、B、C、D、E、F十六个数字和字母符号来表示,基数是16,进位规律是逢十六进一。(16=2^4)
F3E2 = Fx16^3 + 3x16^2 + Ex16^1 + 2x16^0(十六进制)
=15x4096 + 3x256 + 14x16 + 2x1(F取15,E取值14,)
=62434(十进制)
1.1.5 进制数对应关系

1.2 进制转换
1.2.1 二进制与十进制
1.2.1.1 二进制转十进制(位权相加法)
方法为:把二进制数按权展开、相加即得十进制数。

1.2.1.2 十进制转二进制(短除法)
方法为:十进制数除2取余法,即十进制数除2,余数为权位上的数,得到的商值继续除2,依此步骤继续向下运算直到商为0为止。

补充:小数的转化

1.2.2 二进制与八进制
1.2.2.1 二进制转八进制
方法为:3位二进制数按权展开相加得到1位八进制数。(注意事项,3位二进制转成八进制是从右到左开始转换,不足时补0)。

1.2.2.2 八进制转二进制(拆位拼接法)
方法为:八进制数通过除2取余法,得到二进制数,对每个八进制为3个二进制,不足时在最左边补零。

1.2.3 二进制与十六进制
1.2.3.1 二进制转十六进制
方法为:与二进制转八进制方法近似,八进制是取三合一,十六进制是取四合一。(注意事项,4位二进制转成十六进制是从右到左开始转换,不足时补0)。

1.2.3.1 十六进制转二进制(拆位拼接法)
方法为:十六进制数通过除2取余法,得到二进制数,对每个十六进制为4个二进制,不足时在最左边补零。

1.2.4 十进制与八进制与十六进制之间的转换
1.2.4.1 十进制转八进制或者十六进制
方法一:间接法—把十进制转成二进制,然后再由二进制转成八进制或者十六进制。
方法二:直接法—把十进制转八进制或者十六进制按照除8或者16取余,直到商为0为止。

1.2.4.2 八进制或者十六进制转成十进制
方法为:把八进制、十六进制数按权展开、相加即得十进制数。

1.2.5 十六进制与八进制之间的转换(借桥法)
方法一:他们之间的转换可以先转成二进制然后再相互转换。
方法二:他们之间的转换可以先转成十进制然后再相互转换。
1.3 扩展资料
1.3.1 数据的存储单位
在计算机中,描述数据的存储单位有位(bit)、字节(Byte)等。位是计算机中数据的最小存储单位,能表示一位二进制数,只能存储一个0或1。字节是计算机中数据的基本存储单位,一个字节是由八位二进制数组成,即1Byte=8bit。
1.3.2 机器数与真值
在计算机中,为了表示正数和负数,用数的最高位代表符号位,0表示正数,1表示负数。
1.3.3 原码
最高位是符号位,用0表示正数,用1表示负数,其余数值部分用二进制数的绝对值表示整数的方法称为原码表示法,简称原码。通常用[X]原表示X的原码。
1.3.4 反码
正数的反码与正数的原码相同,负数的反码是在负数原码的基础上,除符号位是1之外,其他位按位取反(即是0的改为1,是1的改为0)。
1.3.5 补码
正数的补码与正数的原码相同,负数的补码是先对负数求出反码,再在反码的基础上最低位加1。
2、 文字编码系统
在计算机眼里读到的所有文字都是由0和1组成的字符串,为了能让汉字正常显示在屏幕上,我们需要做以下两件事情:
1、给所有的汉字一个独一无二的数字编号,做一个数字编号到汉字的mapping关系(即字符集)
2、把这个数字编号能用0和1表示出来
这里需要说明的是,第2件事情并不是直接把数字编号用二进制表示出来那么简单,还要处理多个字连在一起的时候如何做分隔的问题。
电脑记录0/1文件的内容要被取出来查阅时,必须要经过一个编码系统的处理才行。 所谓的“编码系统”可以想成是一个“字码对照表”,他的概念有点像下面的图示:

2.1 ASCII系列编码
常用的英文编码表为ASCII系统,ASCII码(American Standard Code for Information Interchange,美国标准信息交换码),这个编码的时代就久远了,是由美国国家标准局(ANSI)制定,这个编码系统中, 每个符号(英文、数字或符号等)都会占用1Bytes的记录, 因此总共会有2^8=256种变化。


2.2 GB2312、GBK、GB18030编码
GB全称国标,GBK全称国标扩展。GB18030编码兼容GBK,GBK兼容GB2312。
2.2.1 GB2312
最早一版的中文编码,每个字占据2bytes。由于要和ASCII兼容,那这2bytes最高位不可以为0了(否则和ASCII会有冲突)。在GB2312中收录了6763个汉字以及682个特殊符号,已经囊括了生活中最常用的所有汉字。GB2312编码表有个值得注意的点,这个表中也有一些数字和字母,与ASCII里面的字母非常像。例如A3B2对应的是数字2(如下图),但是ASCII里面50(十进制)对应的也是数字2。他们的区别就是输入法中所说的“半角”和“全角”。全角的数字2占两个字节。
GB2312编码全表.
2.2.2 GBK
每个字占据2bytes的方式,汉字达到了20902个,另有984个汉语标点符号、部首等。20902个汉字中还包含了繁体字,但是该繁体字与台湾Big5编码不兼容,因为同一个繁体字很可能在GBK和Big5中数字编码是不一样的。
GBK编码全表.
2.2.3 GB18030
GB18030多出来的汉字使用4bytes编码。当然,为了兼容GBK,这个四字节的前两位显然不能与GBK冲突(实操中发现后两位也并没有和GBK冲突)。我国在2000年和2005年分别颁布的两次GB18030编码,其中2005年的是在2000年基础上进一步补充。至此,GB18030编码的中文文件已经有七万多个汉字了,甚至包含了少数民族文字。有兴趣的可以到国家标准委官网了解详情, 链接.
GB2312,GBK,GB18030都是采取了固定长度的办法来解决字符分隔(即前文所提的第2件事情)问题。GBK和GB2312比ASCII多出来的字都是2bytes,GB18030比GBK多出来的字都是4bytes。
2.3 Unicode编码系统
Unicode(统一码、万国码、单一码、标准万国码)是业界的一种标准,它可以使电脑得以体现世界上数十种文字的系统。Unicode 是基于通用字符集(Universal Character Set)的标准来发展。Unicode 的诞生就是为了统一世界上所有编码的,它包含了世界上近乎所有的字符,总共收录将近 110 多万个字符集合,编号范围从 0x000000 到 0x10FFFF。但大多数字符在范围:0x0000 到 0xFFFF 之间(即小于 65536),每个字符都有一个 Unicode 编号并且一般用十六进制表示,前置 U+ 如: U+0041表示英语的大写字母A,U+4E25表示汉字严。
Unicode是一种编码标准,它只是为世界上的所有字符进行了编号,并没有指定每个字符每个编号该如何映射为某个二进制串, Unicode 的主要实现方式有: UTF-8、UTF-16和UTF-32。
Unicode中的码点(Code Point)范围是U+0000~U+10FFFF,把每65536个码点作为一个平面(Plane),总共17个平面,编号从0开始,第一个平面称为Plane 0。

第一个平面即是BMP(Basic Multilingual Plane 基本多语言平面),也叫Plane 0,它的码点范围是U+0000~U+FFFF。这也是我们最常用的平面,日常用到的字符绝大多数都落在这个平面内。UTF-16只需要用两字节编码此平面内的字符。
后续的16个平面称为SP(Supplementary Planes、增补平面)。显然,这些码点已经是超过U+FFFF的了,所以已经超过了16位空间的理论上限,对于这些平面内的字符,UTF-16采用了四字节编码。
注:其中很多平面还是空的,还没有分配任何字符,只是先规划了这么多。
2.3.1 UTF-8(8-bit Unicode Transformation Format)
Unicode赋予了全世界所有文字和符号一个独一无二的数字编号,UTF8所做的事情就是把这个数字编号表示出来(即解决前文提到的第2件事情)。UTF8解决字符间分隔的方式是数二进制中最高位连续1的个数来决定这个字是几字节编码。0开头的属于单字节,和ASCII码重合,做到了兼容。
下表总结了编码规则,字母x表示可用编码的位。
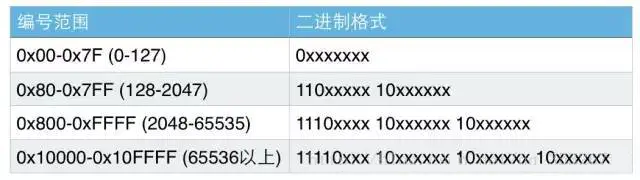
对于中文汉字来说,所有常用汉字的Unicode值都可以用3字节的UTF8表示出来,而GBK编码的汉字基本是2字节(GB18030虽4字节但是日常没人会写那些字)。这也就导致了,如果把GBK编码的中文文本另存为UTF8编码,体积会大50%左右。这也是UTF8的一点小瑕疵,存储同样的汉字,体积比GBK要大50%。
UTF-8 最大的一个特点,就是它是一种变长的编码方式。它可以使用1~4个字节表示一个符号,根据不同的符号而变化字节长度。
UTF-8 的编码规则:
1)对于单字节的符号,字节的第一位设为0,后面7位为这个符号的 Unicode 码。因此对于英语字母,UTF-8 编码和 ASCII 码是相同的。
2)对于n字节的符号(n > 1),第一个字节的前n位都设为1,第n + 1位设为0,后面字节的前两位一律设为10。剩下的没有提及的二进制位,全部为这个符号的 Unicode 码。
举例说明:
中文“鹅”字,Unicode十进制值为40517(16进制为9E45,2进制为1001 1110 0100 0101)。
这个2进制值长度为16位,查询上面表格发现,二字节不够表示,四字节太长,三字节刚好,
因此可以表示为 11101001 10111001 10000101,换算为16进制即E9B985,这就是“鹅”字的UTF8编码,占3字节。
另外,经查询,“鹅”的GBK编码为B6EC,和UTF8的值完全不相干。

举例说明:汉字 [杨] 的 Unicode 编号是:0x6768 ,十进制:26472,二进制是:0110 0111 0110 1000
显然,该汉字的 UTF-8 标准编码格式为:1110xxxx 10xxxxxx 10xxxxxx
0x6768 的二进制是:0110 0111 0110 1000
从这个二进制的最后一位开始,依次从后向前替换编码格式中的 x 即可。

2.3.2 UTF-16
UTF-16只使用2或4个字节编码。UTF-16也是Unicode一种具体的编码实现。
UTf-16编码规则如下:
① 若Unicode码点在第一平面(BMP)中,则使用2个字节进行编码。
② 若Unicode码点在其他平面(辅助平面),则使用4个字节进行编码。
关于辅助平面的码点编码更详细解析如下:辅助平面码点被编码为一对16比特(四个字节)长的码元, 称之为代理对(surrogate pair), 第一部分称为高位代理(high surrogate)或前导代理(lead surrogates),码位范围为:D800-DBFF. 第二部分称为低位代理(low surrogate)或后尾代理(trail surrogates), 码位范围为:DC00-DFFF。注意,高位代理的码位从D800到DBFF,而低位代理的码位从DC00到DFFF,总共恰好为D800-DFFF,这部分码点在第一平面内是保留的,不映射到任何字符,所以UTF-16编码巧妙的利用了这点来进行码点在辅助平面内的4字节编码。
字符”A”的Unicode码点为65(十进制),十六进制表示为41,在第一平面。根据规则,UTF-16采用2个字节进行编码。那么问题又来了,知道了采用两个字节编码,并且我们也知道计算机是以字节为单位进行存储,这两个字节应该表示为00 41(十六进制)?或者是41 00(十六进制)呢?这就引出了一个问题,需要用到之前提及的BOM机制来解决。
表示为00 41意味着采用了大端序(Big endian),而表示为41 00意味着采用了小端序。那么计算机如何知道存储的字符信息采用了大端序还是小端虚呢?这就需要加入一些控制信息,具体是采用大端序,则在文件前加入FE FF,采用小端序,则在文件前加入FF FE。这样,当计算开始读取时发现前两个字节为FE FF,就表示之后的信息采用的是小端序。
Unicode转UTF-16规则流程图如下:

2.3.3 UTF-32
UTF-32 是固定长度的编码,始终占用 4 个字节,足以容纳所有的 Unicode 字符,所以直接存储 Unicode 编号即可,不需要任何编码转换。浪费了空间,提高了效率。
Unicode编码一个具体的示意图:

从上图可以初步得出一些结论:
UTF-8与UTF-16都是变长编码,UTF-32则是定长编码。
码点到UTF-32的转换最简单,就是在前面垫0垫够4字节就行了。
码点到UTF-8的转换,除了最小那个在数值上一样外,其它两个完全看不出两者的关系。
码点到UTF-16的转换则是最微妙的,可以看出前两个字符UTF-16与码点是完全一致的,但那个大码点(准确地说是超过了U+FFFF的码点)则有了很大的变化,长度变成了四字节,值也变得很不一样了。
字符编码在线查询.
2.4 常见编码兼容性

备注:内容收集来源于网络,如有侵权或错误,请联系我整改,谢谢!
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









