









Spark连接HBase进行读写相关操作【CDH5.7.X】
文章内容:
1. 通过Spark读取HBase的表并通过转换RDD
2.Spark连接HBase进行表写入操作
版本:
CDH集群版本:CDH5.7.1
| Spark版本:spark-1.6.0+cdh5.7.1+193 HBase版本:hbase-1.2.0+cdh5.7.1+142 |
准备工作:
1.集群环境准备
已经安装CDH5.7.X集群
集群安装Spark和HBase相关组件
2.开发环境准备
Maven工程需要添加Spark Core和HBase依赖
a.HBase的Maven依赖
注意其中必须去除掉servlet-api的依赖否则在SparkContext初始化的时候会出现servlet-api版本冲突异常
<dependency> <groupId>org.apache.hbase</groupId> <artifactId>hbase-annotations</artifactId> <version>${hbase.version}</version> </dependency> <dependency> <groupId>org.apache.hbase</groupId> <artifactId>hbase-common</artifactId> <version>${hbase.version}</version> <exclusions> <exclusion> <groupId>javax.servlet</groupId> <artifactId>servlet-api</artifactId> </exclusion> <exclusion> <groupId>org.mortbay.jetty</groupId> <artifactId>servlet-api</artifactId> </exclusion> <exclusion> <groupId>javax.servlet.jsp</groupId> <artifactId>jsp-api</artifactId> </exclusion> <exclusion> <groupId>org.mortbay.jetty</groupId> <artifactId>servlet-api-2.5</artifactId> </exclusion> </exclusions> </dependency> <dependency> <groupId>org.apache.hbase</groupId> <artifactId>hbase-client</artifactId> <version>${hbase.version}</version> </dependency> <dependency> <groupId>org.apache.hbase</groupId> <artifactId>hbase-server</artifactId> <version>${hbase.version}</version> <exclusions> <exclusion> <groupId>org.mortbay.jetty</groupId> <artifactId>servlet-api</artifactId> </exclusion> <exclusion> <groupId>org.mortbay.jetty</groupId> <artifactId>jsp-api-2.1</artifactId> </exclusion> <exclusion> <groupId>org.mortbay.jetty</groupId> <artifactId>servlet-api-2.5</artifactId> </exclusion> </exclusions> </dependency> <dependency> <groupId>org.apache.hbase</groupId> <artifactId>hbase-hadoop-compat</artifactId> <version>${hbase.version}</version> </dependency> <dependency> <groupId>org.apache.hbase</groupId> <artifactId>hbase-prefix-tree</artifactId> <version>${hbase.version}</version> </dependency> <dependency> <groupId>org.apache.hbase</groupId> <artifactId>hbase-protocol</artifactId> <version>${hbase.version}</version> </dependency> <dependency> <groupId>org.apache.hbase</groupId> <artifactId>hbase-rest</artifactId> <version>${hbase.version}</version> <exclusions> <exclusion> <groupId>javax.servlet</groupId> <artifactId>*</artifactId> </exclusion> <exclusion> <groupId>org.mortbay.jetty</groupId> <artifactId>servlet-api</artifactId> </exclusion> <exclusion> <groupId>org.mortbay.jetty</groupId> <artifactId>servlet-api-2.5</artifactId> </exclusion> </exclusions> </dependency> <dependency> <groupId>org.apache.hbase</groupId> <artifactId>hbase-thrift</artifactId> <version>${hbase.version}</version> <exclusions> <exclusion> <groupId>javax.servlet</groupId> <artifactId>*</artifactId> </exclusion> <exclusion> <groupId>org.mortbay.jetty</groupId> <artifactId>servlet-api</artifactId> </exclusion> <exclusion> <groupId>org.mortbay.jetty</groupId> <artifactId>servlet-api-2.5</artifactId> </exclusion> </exclusions> </dependency>
b.Spark Core的Maven依赖
<!-- spark core --> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-core_2.10</artifactId> <version>${spark.version}</version> <exclusions> <exclusion> <groupId>javax.servlet</groupId> <artifactId>*</artifactId> </exclusion> <exclusion> <groupId>org.slf4j</groupId> <artifactId>slf4j-api</artifactId> </exclusion> </exclusions> </dependency>
3. 数据准备
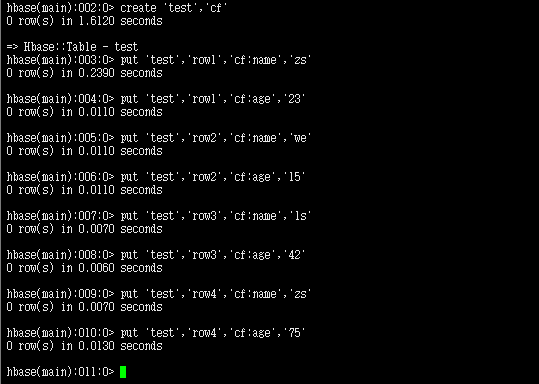
4. Spark读取HBase表
import org.apache.hadoop.hbase.TableNotFoundException
import org.apache.hadoop.hbase.client.{Put, Result}
import org.apache.hadoop.hbase.io.ImmutableBytesWritable
import org.apache.hadoop.hbase.mapreduce.{TableInputFormat, TableOutputFormat}
import org.apache.hadoop.hbase.util.Bytes
import org.apache.hadoop.mapreduce.Job
import org.apache.spark.rdd.RDD
import org.apache.spark.SparkContext
第三步:创建SparkContext
//注意本地设置为Spark本地运行,如果集群模式运行把setMaster("local")去掉
val sparkConf = new SparkConf().setAppName("my app").setMaster("local")
//创建SparkContext
val sc = new SparkContext(sparkConf)
第四步:读取HBaseConf转换RDD
//通过newAPIHadoopRDD方法读取hbase表转换为RDD
val hbaseRDD = sc.newAPIHadoopRDD(conf, classOf[TableInputFormat],
classOf[ImmutableBytesWritable],
classOf[Result])
第五步:对hbaseRDD进行操作
//HBase 对test表进行统计
val testCount = hbaseRDD.count()
println("count :" + testCount) //4
//循环每一行HBase的数据
hBaseRDD.foreach{case (_,result) =>
//获取行键
val key = Bytes.toString(result.getRow)
//通过列族和列名获取列
val name = Bytes.toString(result.getValue("cf".getBytes,"name".getBytes))
val age = Bytes.toInt(result.getValue("cf".getBytes,"age".getBytes))
println("Row key:" + key + " ,name:" + name + ",age :" + age)
}
//Row key: row1,name:zs,age:23
//....
5. Spark对HBase表进行写入
import org.apache.hadoop.hbase.TableNotFoundException
import org.apache.hadoop.hbase.client.{Put, Result}
import org.apache.hadoop.hbase.io.ImmutableBytesWritable
import org.apache.hadoop.hbase.mapreduce.{TableInputFormat, TableOutputFormat}
import org.apache.hadoop.hbase.util.Bytes
import org.apache.hadoop.mapreduce.Job
import org.apache.spark.rdd.RDD
import org.apache.spark.SparkContext
第三步:创建SparkContext
//注意本地设置为Spark本地运行,如果集群模式运行把setMaster("local")去掉
val sparkConf = new SparkConf().setAppName("my app").setMaster("local")
//创建SparkContext
val sc = new SparkContext(conf)
job.setOutputValueClass(classOf[Result])
job.setOutputFormatClass(classOf[TableOutputFormat[ImmutableBytesWritable]])
val hbaseWriterRdd = inDataRDD.map(_.split(',')).map{arr=>{
val put = new Put(Bytes.toBytes(arr(0)))
put.addColumn(Bytes.toBytes("cf"),Bytes.toBytes("name"),Bytes.toBytes(arr(1)))
put.addColumn(Bytes.toBytes("cf"),Bytes.toBytes("age"),Bytes.toBytes(arr(2).toInt))
(new ImmutableBytesWritable, put)
}}
7. HBase写入数据检查
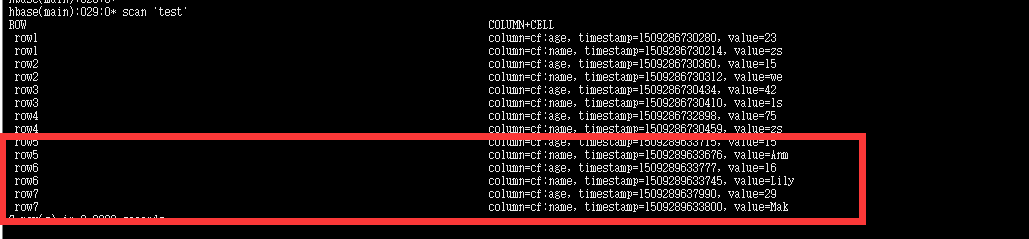















 703
703

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









