







数据挖掘方面知识的简单汇总
本文章里的SVM例子是参考CSDN社区内一位大佬的文章,忘记是哪位了暂时不想找了,大家看到这位大佬帮我道一声谢!
一、数据挖掘基本内容及环境配置
此块内容包括数据挖掘的基本知识和python的环境配置
1、基本内容
知识发现(KDD:Knowledge Discovery in Database)是从数据集中识别出有效的、新颖的、潜在有用的,以及最终可理解的模式的非平凡过程。
知识发现将信息变为知识,从数据矿山中找到蕴藏的知识金块,将为知识创新和知识经济的发展作出贡献。该术语于1989年出现,Fayyad定义为"KDD"是从数据集中识别出有效的、新颖的、潜在有用的,以及最终可理解的模式的非平凡过程"。
数据挖掘属于知识发现(KDD)中的一个重要步骤。
数据挖掘指的是在大型的数据库中对有价值的信息知识进行获取, 属于一种先进的数据信息模式。更具体的说:数据挖掘就是人们常说的知识发现(KDD),通过对海量的、杂乱无章的、不清晰的并且随机性很大的数据进行挖掘,找到其中蕴含的有规律并且有价值和能够理解应用的知识,这一过程就是数据挖掘。
它主要是借助分析工具找到数据和模型之间的关心,之后进行预测,并将数据回归到真实变量。在网络异常检测技术中应用数据挖掘技术,能够从海量数据中找到需要的信息,并且根据数据信息建立模型,从而对入侵行为和正常操作进行分类了,数据挖掘的方法有两种:一种是分类分析,一种是聚类。分类分析需要找到数据之间的依赖关系,并且进行预判断输出离散类别。聚类分析是通过反复的分区从而找到解决办法,它的输出是各个不同类型的数据,也就是先对数据进行初始归类,之后去粗取精进行合并,最后使得对象之间能够彼此联系归于一类。
2、工具及环境配置(无图)
工欲善其事必先利其器
Anaconda Navigator是一个开源的Python发行版本,其包含了conda、Python等180多个科学包及其依赖项。在配置环境的过程中我遇到了不少的问题,在此也记录一下个人的安装过程,也算一个小的知识点。
第一步,在官网anaconda.com下载安装包,并进行安装操作
第二步,因为在安装过程中没有勾选自动配置环境变量,因此在安装完成后,首先做的一件事便是配置环境变量,具体如何打开该设置我就不赘述了。在将Anaconda3、Library、Scripts以及mingw-w64等添加到path后,此步骤算完成。
第三步,打开Anaconda,并且打开Anaconda powershell。由于我的powershell打开后PS前默认为(base),并且经过一顿折腾后虽然能够激活其他环境,但还是有许多warning,所以我改用CMD了。由于在配置环境变量后,cmd可以直接调用conda命令(这里如果用系统自带的power shell调用conda命令无效的话可能是因为系统的powershell与conda不兼容,需要安装个兼容包即可),所以这里我首先应用 指令
conda create -n your_env_name python=X.X(2.7、3.7等)
创建了一个新的环境(这里我将新环境命名为DataMining37),这样我就可以将用于数据挖掘的环境与默认的base(root)环境分开。但是这时便有了新的问题,DateMining37里面并没有安装很多的第三方包和依赖项。
第四步,在创建完新的环境后,我学到了几条新的conda指令:
1)conda list 查看安装了哪些包。
2)conda env list 或 conda info -e 查看当前存在哪些虚拟环境
3)conda update conda 检查更新当前conda
4)activate your_env_name(虚拟环境名称) 激活特定环境
5)deactivate退出当前环境
6)conda remove -n your_env_name(虚拟环境名称) --all 删除特定环境
7)conda remove --name your_env_name package_name 删除特定包
刚刚说到DataMining37中少了很多第三方包以及其依赖项,这里我用命令:
conda install -n your_env_name [package] 安装特定包到特定环境
将Jupyter notebook安装到DataMining37中,这样我自己创建的新虚拟环境中便安装上了jupyter,同理将matplotlib、numpy、scikit-learn、pandas、spark的包及其依赖项都安装上,到此软件安装及环境配置内容完成。
二、基础模型SVM(支持向量机)及决策树
由于支持向量机中需要构建并求解约束最优化问题,因此我们首先需要学习拉格朗日乘子法。
基本的拉格朗日乘子法(又称为拉格朗日乘数法),就是求函数f(x1,x2,…)在g(x1,x2,…)=0的约束条件下的极值的方法。其主要思想是引入一个新的参数λ(即拉格朗日乘子),将约束条件函数与原函数联系到一起,使能配成与变量数量相等的等式方程,从而求出得到原函数极值的各个变量的解。
1、拉格朗日乘子法(Lagrangemultiplier)
假设需要求极值的目标函数(objectivefunction)为f(x,y),限制条件为φ(x,y)=M
设g(x,y)=M-φ(x,y)
定义一个新函数
F(x,y,λ)=f(x,y)+λg(x,y)
则用偏导数方法列出方程:
∂F/∂x=0
∂F/∂y=0
∂F/∂λ=0
求出x,y,λ的值,代入即可得到目标函数的极值
扩展为多个变量的式子为:
F(x1,x2,λ)=f(x1,x2,)-λg(x1,x2)
则求极值点的方程为:
∂F/∂xi=0(xi即为x1、x2……等自变量)
∂F/∂λ=g(x1,x2)=0
以上就是拉格朗日乘子法的算法
2、支持向量机(Support Vector Machine)
这里再来说支持向量机,首先上定义:支持向量机(Support Vector Machine,SVM)是Corinna Cortes和Vapnik等于1995年首先提出的,它在解决小样本、非线性及高维模式识别中表现出许多特有的优势,并能够推广应用到函数拟合等其他机器学习问题中。
在机器学习中,支持向量机(SVM,还支持矢量网络)是与相关的学习算法有关的监督学习模型,可以分析数据,识别模式,用于分类和回归分析。
(1)、支持向量机具体示例
(一):线性SVM分类器
导入依赖包
%matplotlib inline
import numpy as np
import matplotlib.pyplot as plt
import seaborn;
from sklearn.linear_model import LinearRegression
from scipy import stats
import pylab as pl
seaborn.set()
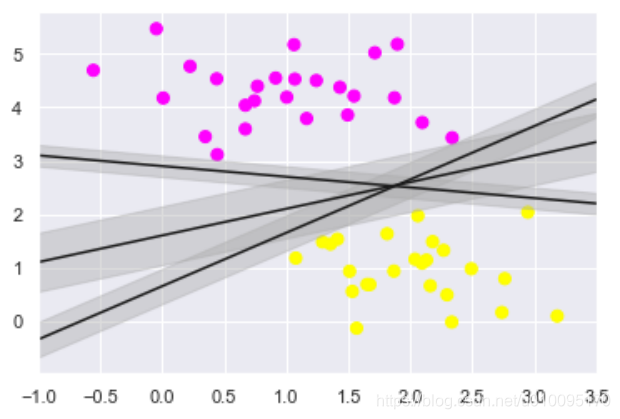
支持向量机是解决分类和回归问题非常强大的有监督学习算法。Linear的SVM做的事情就是在不同类别的“数据团”之间划上一条线,对线性可分集,总能找到使样本正确划分的分界面,而且有无穷多个,哪个是最优? 必须寻找一种最优的分界准则,SVM试图找到一条最健壮的线,什么叫做最健壮的线?其实就是离2类样本点最远的线。这条线就是所谓的超平面。
from sklearn.datasets.samples_generator import make_blobs
X, y = make_blobs(n_samples=50, centers=2,random_state=0, cluster_std=0.60)
xfit = np.linspace(-1, 3.5)
plt.scatter(X[:, 0], X[:, 1], c=y, s=50, cmap='spring')
# 其实随意给定3组参数,就可以画出3条不同的直线,但它们都可以把图上的2类样本点分隔开
for m, b, d in [(1, 0.65, 0.33), (0.5, 1.6, 0.55), (-0.2, 2.9, 0.2)]:
yfit = m * xfit + b
plt.plot(xfit, yfit, '-k')
plt.fill_between(xfit, yfit - d, yfit + d, edgecolor='none', color='#AAAAAA', alpha=0.4)
plt.xlim(-1, 3.5);
结果:
%matplotlib inline
import numpy as np
import matplotlib.pyplot as plt
import seaborn;
from sklearn.linear_model import LinearRegression
from scipy import stats
import pylab as pl
seaborn.set()
from sklearn.svm import SVC
clf = SVC(kernel='linear')
clf.fit(X, y)
def plot_svc_decision_function(clf, ax=None):
"""Plot the decision function for a 2D SVC"""
if ax is None:
ax = plt.gca()
x = np.linspace(plt.xlim()[0], plt.xlim()[1], 30)
y = np.linspace(plt.ylim()[0], plt.ylim()[1], 30)
Y, X = np.meshgrid(y, x)
P = np.zeros_like(X)
for i, xi in enumerate(x):
for j, yj in enumerate(y):
P[i, j] = clf.decision_function([xi, yj])
# plot the margins
ax.contour(X, Y, P, colors='k',levels=[-1, 0, 1], alpha=0.5,linestyles=['--', '-', '--'])
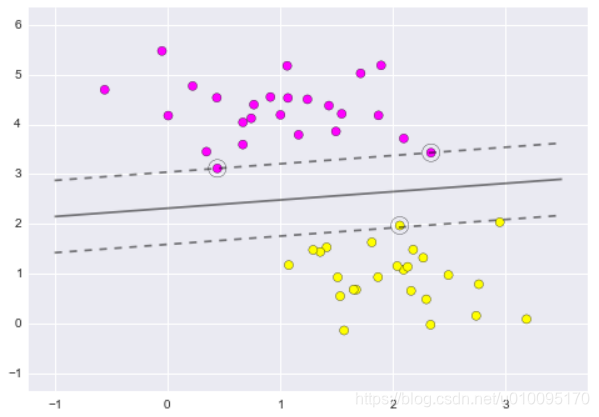
plt.scatter(X[:, 0], X[:, 1], c=y, s=50, cmap='spring')
plot_svc_decision_function(clf)
plt.scatter(clf.support_vectors_[:, 0], clf.support_vectors_[:, 1],s=200, facecolors='none');
利用sklearn中SVM的一个属性support_vectors_标示“支持向量”,并画出。
结果如图:
(二):SVM与核函数
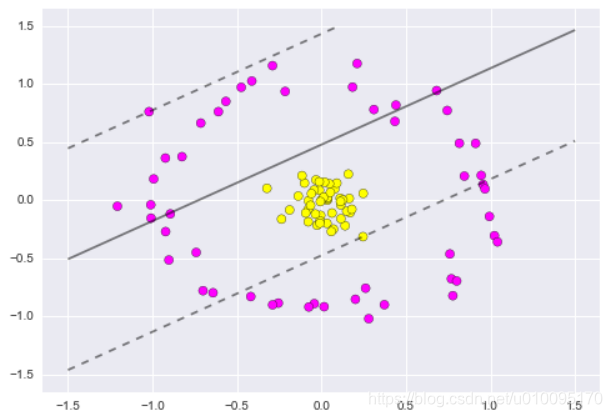
对于非线性可切分的数据集,要做分割,就要借助于核函数了简单一点说呢,核函数可以看做对原始特征的一个映射函数,
不过SVM不会傻乎乎对原始样本点做映射,它有更巧妙的方式来保证这个过程的高效性。
下面有一个例子,你可以看到,线性的kernel(线性的SVM)对于这种非线性可切分的数据集,是无能为力的。
%matplotlib inline
import numpy as np
import matplotlib.pyplot as plt
import seaborn;
from sklearn.linear_model import LinearRegression
from scipy import stats
import pylab as pl
seaborn.set()
from sklearn.datasets.samples_generator import make_circles
from sklearn.svm import SVC
clf = SVC(kernel='linear')
clf.fit(X, y)
def plot_svc_decision_function(clf, ax=None):
"""Plot the decision function for a 2D SVC"""
if ax is None:
ax = plt.gca()
x = np.linspace(plt.xlim()[0], plt.xlim()[1], 30)
y = np.linspace(plt.ylim()[0], plt.ylim()[1], 30)
Y, X = np.meshgrid(y, x)
P = np.zeros_like(X)
for i, xi in enumerate(x):
for j, yj in enumerate(y):
P[i, j] = clf.decision_function([xi, yj])
# plot the margins
ax.contour(X, Y, P, colors='k',
levels=[-1, 0, 1], alpha=0.5,
linestyles=['--', '-', '--'])
X, y = make_circles(100, factor=.1, noise=.1)
plt.scatter(X[:, 0], X[:, 1], c=y, s=50, cmap='spring')
plot_svc_decision_function(clf);
运用高斯核函数/radial basis function
r = np.exp(-(X[:, 0] ** 2 + X[:, 1] ** 2))
from mpl_toolkits import mplot3d
def plot_3D(elev=30, azim=30):
ax = plt.subplot(projection='3d')
ax.scatter3D(X[:, 0], X[:, 1], r, c=y, s=50, cmap='spring')
ax.view_init(elev=elev, azim=azim)
ax.set_xlabel('x')
ax.set_ylabel('y')
ax.set_zlabel('r')
interact(plot_3D, elev=[-90, 90], azip=(-180, 180));
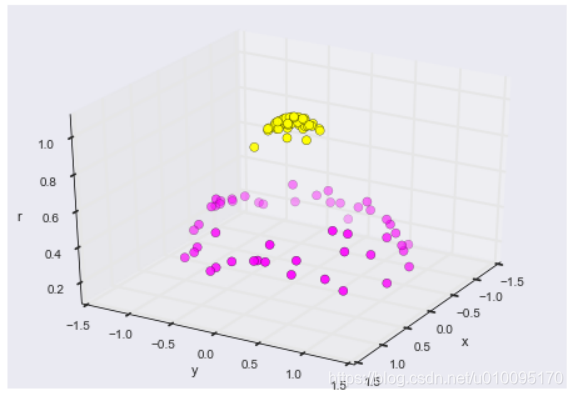
利用高斯核函数将2维空间无法分开的点映射到3维空间后,就可以有一个平面轻松分开。
而带rbf核的SVM就能做到这一点:
clf = SVC(kernel='rbf')
clf.fit(X, y)
plt.scatter(X[:, 0], X[:, 1], c=y, s=50, cmap='spring')
plot_svc_decision_function(clf)
plt.scatter(clf.support_vectors_[:, 0], clf.support_vectors_[:, 1],
s=200, facecolors='none');
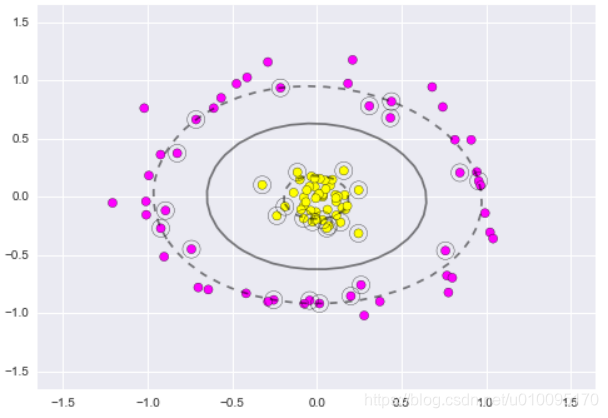
(2)、SVM总结
- 非线性映射是SVM方法的理论基础,SVM利用内积核函数代替向高维空间的非线性映射;
对特征空间划分的最优超平面是SVM的目标,最大化分类边际的思想是SVM方法的核心; - 支持向量是SVM的训练结果,在SVM分类决策中起决定作用的是支持向量。因此,模型需要存储空间小,算法鲁棒性强;
- 无任何前提假设,不涉及概率测度;
- SVM算法对大规模训练样本难以实施
- 用SVM解决多分类问题存在困难,经典的支持向量机算法只给出了二类分类的算法,而在数据挖掘的实际应用中,一般要解决多类的分类问题。可以通过多个二类支持向量机的组合来解决。主要有一对多组合模式、一对一组合模式和SVM决策树;再就是通过构造多个分类器的组合来解决。主要原理是克服SVM固有的缺点,结合其他算法的优势,解决多类问题的分类精度。如:与粗集理论结合,形成一种优势互补的多类问题的组合分类器。
- SVM是O(n^3)的时间复杂度。在sklearn里,LinearSVC是可扩展的(也就是对海量数据也可以支持得不错), 对特别大的数据集SVC就略微有点尴尬了。不过对于特别大的数据集,你倒是可以试试采样一些样本出来,然后用rbf核的SVC来做做分类。
3、决策树
(1)、决策树算法
决策树(Decision Tree)是在已知各种情况发生概率的基础上,通过构成决策树来求取净现值的期望值大于等于零的概率,评价项目风险,判断其可行性的决策分析方法,是直观运用概率分析的一种图解法。由于这种决策分支画成图形很像一棵树的枝干,故称决策树。在机器学习中,决策树是一个预测模型,他代表的是对象属性与对象值之间的一种映射关系。Entropy = 系统的凌乱程度,使用算法ID3, C4.5和C5.0生成树算法使用熵。这一度量是基于信息学理论中熵的概念。
决策树是一种树形结构,其中每个内部节点表示一个属性上的测试,每个分支代表一个测试输出,每个叶节点代表一种类别。
分类树(决策树)是一种十分常用的分类方法。
决策树在构造过程中不需要任何领域知识或参数设置,因此在实际应用中,对于探测式的知识发现,决策树更加适用。
1、ID3,C4.5,CART算法
2、C4.5Rule的泛化能力通常优于C4.5决策树
(2)、决策树的解释
1、决策树是基于树结构进行决策的
2、一般地,一棵决策树包含一个根结点、若干个内部结点和若干个叶结点。叶结点对应于决策结果,其他每个结点则对应于一个属性测试。
3、每个结点包含的样本集合根据属性测试的结果被划分到子结点中;根结点包含样本全集。
4、从根结点到每个叶结点的路径对应了一个判定测试序列。
(3)、决策树的构建
1、决策树学习的目的是为了产生一颗泛化能力强,即处理未见示例能力强的决策树。
2、决策树的生成是一个递归的过程。
在决策树基本算法中,有3种情形会导致递归返回:
(1)当前结点包含的样本全属于同一类别,无需划分;
(2)当前结点包含的样本集合为空,不能划分;
(3)当前属性集为空,或是所有样本在所有属性上取值相同,无法划分。
但是,这样往往会使得树的节点过多,导致过拟合问题。
可行的方法是增加停止条件:1)当前结点中的记录数低于一个最小的阈值,那么久停止分割。2)设置树的最大深度。
(4)、划分属性
贪心算法,使决策树的分支结点所包含的样本尽可能属于同一类别,即结点的“纯度”(purity)越来越高。
划分属性分为三种不同的情况:
1)属性是离散值且不要求生成二叉决策树。此时用属性的每一个划分作为一个分支。
2)属性是离散值且要求生成二叉决策树。此时用属性划分的一个子集进行测试,按照“属于此子集“和”不属于此子集“分成两个分支。
3)属性是连续值。此时确定一个值作为分裂点split_point,按照>split_point和<=split_point生成两个分支。
1、信息增益、信息熵
ID3决策树学习算法就是以“信息增益”(information gain)为准则来选择划分属性。
信息增益准则对可取值数目较多的属性有所偏好(因为相对来说,每个分支结点下样本越少,纯度越高)。
2、增益率
C4.5决策树算法使用“增益率”(gain ratio)来选择最优划分属性。
增益率准则对可取值数目较少的属性有所偏好,因此,C4.5算法不直接选择增益率最大的候选属性,而是使用了一个启发式:先从候选划分属性中找出信息增益高于平均水平的属性,再从中选择增益率最高的。
3、基尼指数
CART决策树使用“基尼指数”(Gini index)来选择划分属性。
Gini(D)反映了从数据集中随机抽取两个样本,其类别标记不一致的概率。因此Gini(D)越小,则数据集的纯度越高。
(5)、剪枝处理
在决策树学习中,为了尽可能正确分类训练样本,节点划分过程将不断重复,有时会造成决策树分支过多,这时就可能因训练样本学得“太好了”,以至于把训练集自身的一些特点当作所有数据都具有的一般性质而导致过拟合。
决策树剪枝的基本策略:“预剪枝”(prepruning)和“后剪枝”(postpruning)
(6)、连续值处理
1、C4.5决策树算法中采用二分法离散化连续属性。
需要注意的是,与离散属性不同,若当前结点划分属性为连续属性,该属性还可作为其后代结点的划分属性。
(7)、缺失值处理
C4.5算法有该处理。
基本思想是考虑非缺失样例的信息增益,然后乘上非缺失值的比例。但是这个比例的定义为非缺失值的权重之和除以全部数据的权重之和。
单变量决策树,在每个非叶结点仅考虑一个划分属性,产生“轴平行”分类面。即分类边界的每一段都是与坐标轴平行的。
多变量决策树(multivariate decision tree)能够实现“斜划分”甚至更复杂的决策树。
三、数据挖掘流程
从数据本身来考虑,通常数据挖掘需要有数据清理、数据变换、数据挖掘实施过程、模式评估和知识表示等8个步骤。
(1) 信息收集: 根据确定的数据分析对象抽象出在数据分析中所需要的特征信息,然后选择合适的信息收集方法,将收集到的信息存入数据库。对于海量数据,选择一个合适的数据存储和管理的数据仓库是至关重要的。
(2) 数据集成: 把不同来源、格式、特点性质的数据在逻辑上或物理上有机地集中,从而为企业提供全面的数据共享。
(3) 数据规约: 执行多数的数据挖掘算法即使在少量数据上也需要很长的时间,而做商业运营数据挖掘时往往数据量非常大。数据规约技术可以用来得到数据集的规约表示,它小得多,但仍然接近于保持原数据的完整性,并且规约后执行数据挖掘结果与规约前执行结果相同或几乎相同。
(4) 数据清理: 在数据库中的数据有一些是不完整的(有些感兴趣的属性缺少属性值),含噪声的(包含错误的属性值),并且是不一致的(同样的信息不同的表示方式),因此需要进行数据清理,将完整、正确、一致的数据信息存入数据仓库中。
(5) 数据变换: 通过平滑聚集,数据概化,规范化等方式将数据转换成适用于数据挖掘的形式。对于有些实数型数据,通过概念分层和数据的离散化来转换数据也是重要的一步。
(6) 数据挖掘过程: 根据数据仓库中的数据信息,选择合适的分析工具,应用统计方法、事例推理、决策树、规则推理、模糊集、甚至神经网络、遗传算法的方法处理信息,得出有用的分析信息。
(7) 模式评估: 从商业角度,由行业专家来验证数据挖掘结果的正确性。
(8) 知识表示: 将数据挖掘所得到的分析信息以可视化的方式呈现给用户,或作为新的知识存放在知识库中,供其他应用程序使用。
数据挖掘过程是一个反复循环的过程,每一个步骤如果没有达到预期目标,都需要回到前面的步骤,重新调整并执行。不是每件数据挖掘的工作都需要这里列出的每一步,例如在某个工作中不存在多个数据源的时候,步骤(2)数据集成的步骤便可以省略。
步骤(3)数据规约(4)数据清理(5)数据变换又合称数据预处理。在数据挖掘中,至少60%的费用可能要花在步骤(1)信息收集阶段,而至少60%以上的精力和时间是花在数据预处理。















 2411
2411











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









