







关于hadoop在电脑上安装的过程,请参考我的上一篇博文:
Hadoop-利用java API操作HDFS文件
我的安装和配置环境是Windows下伪分布模式hadoop下使用eclipse进行开发。
上面的文中有关于安装和配置hadoop的视频和安装软件所需的全部资料。
下面是我们本文重点。统计文件中单词的个数。我们再看Hadoop的一般书籍中,基本都会把这个程序作为hadoop的MapReduce的入门程序。确实比较简单。
先说一些代码中使用到的东西:
StringTokenizer:字符串分隔解析类型
*之前没有发现竟然有这么好用的工具类
java.util.StringTokenizerStringTokenizer(String str) :
构造一个用来解析str的StringTokenizer对象。
java默认的分隔符是“空格”、“制表符(‘\t’)”、“换行符(‘\n’)”、“回车符(‘\r’)”。StringTokenizer(String str, String delim) :
构造一个用来解析str的StringTokenizer对象,并提供一个指定的分隔符。StringTokenizer(String str, String delim, boolean returnDelims) :
构造一个用来解析str的StringTokenizer对象,并提供一个指定的分隔符,同时,指定是否返回分隔符。
以前竟然没有发现有这么好用的工具类StringTokenizer。
准备工作:
mapreduce程序需要对文件中的单词进行统计,我们需要有输入文件,在HDFS系统中设置输入文件,我们利用终端在linux系统中准备输入文件的数据工作。
我在linux下/usr/local目录下存放新建需要的数据文件words.txt文件:

文件内容如图所示,有了这个文件之后,需要把这个文件上传到HDFS文件系统中,使用下面的命令:

hadoop fs -put 本地文件路径 hdfs文件路径
该命令把本地系统中的文件上传到HDFS文件系统中
hadoop fs -ls /
该命令把HDFS根目录中的文件遍历输出
上传了文件之后,需要把文件的路径设置到代码中,代码中读取文件内容,经过mapreduce运算,将结果输出到对应所设置的输出文件中进行保存。
代码:
下面给出MapReduce类的代码如下:
package org.conan.myhadoop.mr;
import java.io.IOException;
import java.util.Iterator;
import java.util.StringTokenizer;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapred.FileInputFormat;
import org.apache.hadoop.mapred.FileOutputFormat;
import org.apache.hadoop.mapred.JobClient;
import org.apache.hadoop.mapred.JobConf;
import org.apache.hadoop.mapred.MapReduceBase;
import org.apache.hadoop.mapred.Mapper;
import org.apache.hadoop.mapred.OutputCollector;
import org.apache.hadoop.mapred.Reducer;
import org.apache.hadoop.mapred.Reporter;
import org.apache.hadoop.mapred.TextInputFormat;
import org.apache.hadoop.mapred.TextOutputFormat;
/**
* 单词统计MapReduce
*/
public class WordCount {
/**
* Mapper类
*/
public static class WordCountMapper extends MapReduceBase implements Mapper<Object, Text, Text, IntWritable> {
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
/**
* map方法完成工作就是读取文件
* 将文件中每个单词作为key键,值设置为1,
* 然后将此键值对设置为map的输出,即reduce的输入
*/
@Override
public void map(Object key, Text value, OutputCollector<Text, IntWritable> output, Reporter reporter) throws IOException {
/**
* StringTokenizer:字符串分隔解析类型
* 之前没有发现竟然有这么好用的工具类
* java.util.StringTokenizer
* 1. StringTokenizer(String str) :
* 构造一个用来解析str的StringTokenizer对象。
* java默认的分隔符是“空格”、“制表符(‘\t’)”、“换行符(‘\n’)”、“回车符(‘\r’)”。
* 2. StringTokenizer(String str, String delim) :
* 构造一个用来解析str的StringTokenizer对象,并提供一个指定的分隔符。
* 3. StringTokenizer(String str, String delim, boolean returnDelims) :
* 构造一个用来解析str的StringTokenizer对象,并提供一个指定的分隔符,同时,指定是否返回分隔符。
*
* 默认情况下,java默认的分隔符是“空格”、“制表符(‘\t’)”、“换行符(‘\n’)”、“回车符(‘\r’)”。
*/
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
output.collect(word, one);
}
}
}
/**
* reduce的输入即是map的输出,将相同键的单词的值进行统计累加
* 即可得出单词的统计个数,最后把单词作为键,单词的个数作为值,
* 输出到设置的输出文件中保存
*/
public static class WordCountReducer extends MapReduceBase implements Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable result = new IntWritable();
@Override
public void reduce(Text key, Iterator<IntWritable> values, OutputCollector<Text, IntWritable> output, Reporter reporter) throws IOException {
int sum = 0;
while (values.hasNext()) {
sum += values.next().get();
}
result.set(sum);
output.collect(key, result);
}
}
public static void main(String[] args) throws Exception {
//数据输入路径 这里的路径需要换成自己的hadoop所在地址
String input = "hdfs://centos:9000/words.txt";
/**
* 输出路径设置为HDFS的根目录下的out文件夹下
* 注意:该文件夹不应该存在,否则出错
*/
String output = "hdfs://centos:9000/out";
JobConf conf = new JobConf(WordCount.class);
conf.setJobName("WordCount");
// conf.addResource("classpath:/hadoop/core-site.xml");
// conf.addResource("classpath:/hadoop/hdfs-site.xml");
// conf.addResource("classpath:/hadoop/mapred-site.xml");
//对应单词字符串
conf.setOutputKeyClass(Text.class);
//对应单词的统计个数 int类型
conf.setOutputValueClass(IntWritable.class);
//设置mapper类
conf.setMapperClass(WordCountMapper.class);
/**
* 设置合并函数,合并函数的输出作为Reducer的输入,
* 提高性能,能有效的降低map和reduce之间数据传输量。
* 但是合并函数不能滥用。需要结合具体的业务。
* 由于本次应用是统计单词个数,所以使用合并函数不会对结果或者说
* 业务逻辑结果产生影响。
* 当对于结果产生影响的时候,是不能使用合并函数的。
* 例如:我们统计单词出现的平均值的业务逻辑时,就不能使用合并
* 函数。此时如果使用,会影响最终的结果。
*/
conf.setCombinerClass(WordCountReducer.class);
//设置reduce类
conf.setReducerClass(WordCountReducer.class);
/**
* 设置输入格式,TextInputFormat是默认的输入格式
* 这里可以不写这句代码。
* 它产生的键类型是LongWritable类型(代表文件中每行中开始的偏移量值)
* 它的值类型是Text类型(文本类型)
*/
conf.setInputFormat(TextInputFormat.class);
/**
* 设置输出格式,TextOutpuTFormat是默认的输出格式
* 每条记录写为文本行,它的键和值可以是任意类型,输出回调用toString()
* 输出字符串写入文本中。默认键和值使用制表符进行分割。
*/
conf.setOutputFormat(TextOutputFormat.class);
//设置输入数据文件路径
FileInputFormat.setInputPaths(conf, new Path(input));
//设置输出数据文件路径(该路径不能存在,否则异常)
FileOutputFormat.setOutputPath(conf, new Path(output));
//启动mapreduce
JobClient.runJob(conf);
System.exit(0);
}
}
代码中已经把详细的功能和必要的注释已经给出了。下面看看结果:
代码运行结束之后,控制台打印日志如下:
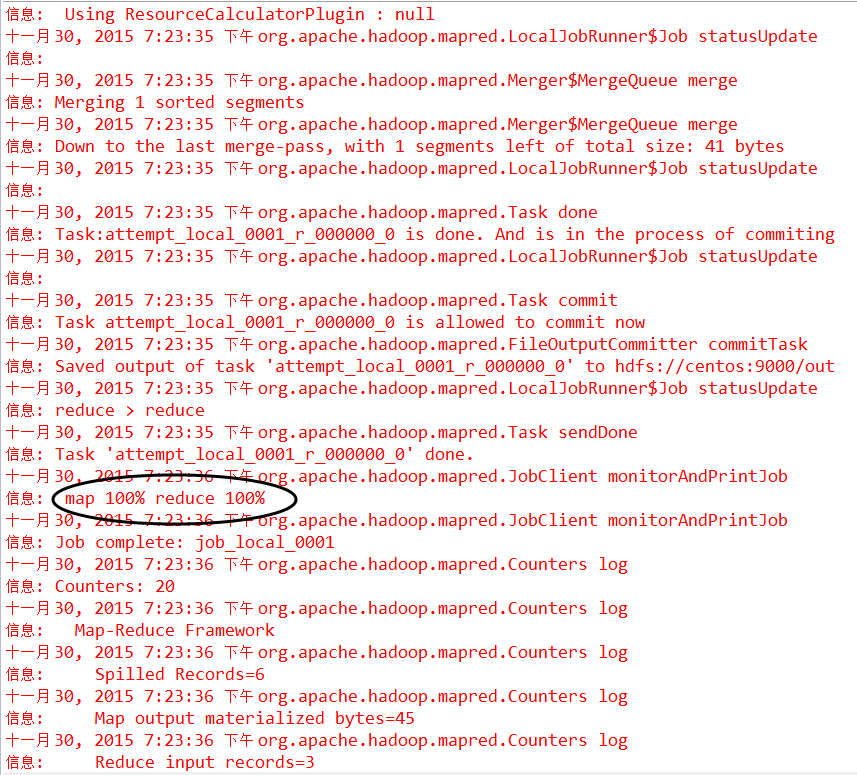
上面的日志没有出现错误和异常,代码正常结束。map任务和reduce任务100%完成。
运行结束之后,使用命令hadoop fs -ls / 遍历根目录下的文件
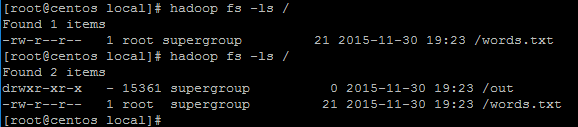
代码运行结束,输出文件out被创建。
下面使用命令:hadoop fs -lsr / 循环遍历根目录下的文件,发现out文件夹下的文件目录

运行结束之后,out文件夹下,有_SUCCESS文件和part-00000文件,我们使用命令:
hadoop fs -cat /out/_SUCCESS
hadoop fs -cat /out/part-00000
查看这两个文件的内容:
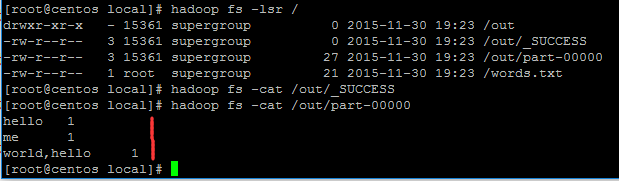
运行命令发现,_SUCCESS文件啥也没有,part-00000文件保存了输出的结果。
hello 单词出现一次
me单词出现一次
world,hello单词出现一次
由于我们使用的StringTokenizer默认的分隔符是“空格”、“制表符(‘\t’)”、“换行符(‘\n’)”、“回车符(‘\r’)”。所以逗号没有作为分隔符。
至此我们的mapreduce程序运行完成,可以说完美运行。
最后,我在提一点跟程序中没有多大关系的一行命令:

hadoop fs -rmr hdfs://centos:9000/*
这句命令的意思是删除HDFS根目录下的所有文件!!!
当我们在测试开发阶段,特别是我所使用的是伪分布模式,所有的文件都是保存在我的本机的,如果测试所用文件很多,我们使用这个命令可以有效清除一些测试中间生成的文件,为我们本次测试清除文件。当我们熟练了以后,在进行有效的HDFS文件管理操作。在测试阶段,我建议在测试mapreduce代码之前,使用该命令清除一下文件。保证思路清晰,没有其他的干扰。
注意该命令后的*号不能少。
最后,说明,代码不是我的原创,原创作者在这里:https://github.com/bsspirit/maven_hadoop_template
原创作者使用eclipse结合Maven使用。我没有使用Maven,直接使用eclipse,把他的项目使用eclipse环境进行开发。特此声明。
本项目的代码地址:请猛戳这里(欢迎关注我的GITHUB)
项目使用eclipse构建。方便易用,代码注释详细。















 712
712

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









