







搭建Hadoop3.3.1伪分布式环境
搭建前提
# 关闭防火墙,方面后面浏览器访问测试
[root@node ~]# systemctl stop firewalld
[root@node ~]# systemctl disable firewalld
# 添加IP地址映射,方便后面地址配置
[root@node ~]# vim /etc/hosts
192.168.197.129 node
# 配置SSH免密登录,方便后面服务启动
[root@node ~]# ssh-keygen
[root@node ~]# ssh-copy-id node
安装JDK和Hadoop
# 解压 JDK 和 Hadoop
[root@node src]# tar -zxf jdk-8u111-linux-x64.tar.gz
[root@node src]# tar -zxf hadoop-3.2.2.tar.gz
# 重命名 JDK 和 Hadoop 方便环境配置
[root@node src]# mv jdk1.8.0_111/ jdk
[root@node src]# mv hadoop-3.2.2 hadoop
# 配置环境变量,方便命令运行
[root@node src]# vim ~/.bash_profile
export JAVA_HOME=/usr/local/src/jdk
export HADOOP_HOME=/usr/local/src/hadoop
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
# 重新加载配置文件,使上述配置生效
[root@node src]# source ~/.bash_profile
# 验证JDK和Hadoop配置是否正确
[root@node src]# java -version
java version "1.8.0_111"
[root@node src]# hadoop version
Hadoop 3.2.2
配置Hadoop
# 进入Hadoop配置文件所在目录
[root@node hadoop]# pwd
/usr/local/src/hadoop/etc/hadoop
# 配置Hadoop运行环境
[root@node hadoop]# vim hadoop-env.sh
export JAVA_HOME=/usr/local/src/jdk
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
修改
core-site.xml文件,添加如下代码
[root@node hadoop]# vim core-site.xml
<configuration>
<!--默认文件系统的地址-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://node:9000</value>
</property>
<!--临时数据目录,用来存放数据,格式化时会自动生成-->
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/src/hadoop/data</value>
</property>
<!--在WebUI操作HDFS的用户,否则没有权限-->
<property>
<name>hadoop.http.staticuser.user</name>
<value>node</value>
</property>
</configuration>
修改
hdfs-site.xml文件,添加如下代码:
[root@node hadoop]# vim hdfs-site.xml
<configuration>
<!--Block的副本数,伪分布式要改为1-->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<!--配置有secondarynamenode的主机-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>node:9868</value>
</property>
</configuration>
修改
yarn-site.xml文件,添加如下代码:
[root@node hadoop]# vim yarn-site.xml
<configuration>
<!---YARN 的节点辅助服务配置 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!---指定ResouceManager启动服务名称 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>node</value>
</property>
</configuration>
修改
mapred-site.xml文件,添加如下代码:
[root@node hadoop]# vim mapred-site.xml
<configuration>
<!---计算框架的运行平台配置 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!---指定MapReduce任务运行所需依赖jar -->
<property>
<name>mapreduce.application.classpath</name>
<value>$HADOOP_HOME/share/hadoop/mapreduce/*:$HADOOP_HOME/share/hadoop/mapreduce/lib/*</value>
</property>
</configuration>
修改
workers文件,替换localhost为当前主机节点名称,指定DataNode和NodeManager的数据节点
[root@node hadoop]# vim workers
node
格式化及服务启动
[root@node hadoop]# hdfs namenode -format
2022-06-05 17:31:41,699 INFO common.Storage: Storage directory /usr/local/src/hadoop/data/dfs/name has been successfully formatted.
2022-06-05 17:31:41,717 INFO namenode.FSImageFormatProtobuf: Saving image file /usr/local/src/hadoop/data/dfs/name/current/fsimage.ckpt_0000000000000000000 using no compression
2022-06-05 17:31:41,795 INFO namenode.FSImageFormatProtobuf: Image file /usr/local/src/hadoop/data/dfs/name/current/fsimage.ckpt_0000000000000000000 of size 396 bytes saved in 0 seconds .
[root@node hadoop]# start-all.sh
Starting namenodes on [node]
Starting datanodes
Starting secondary namenodes [node]
Starting resourcemanager
Starting nodemanagers
[root@node hadoop]# jps
64759 SecondaryNameNode
65176 NodeManager
64362 NameNode
65563 Jps
65019 ResourceManager
64542 DataNode
Hadoop环境测试
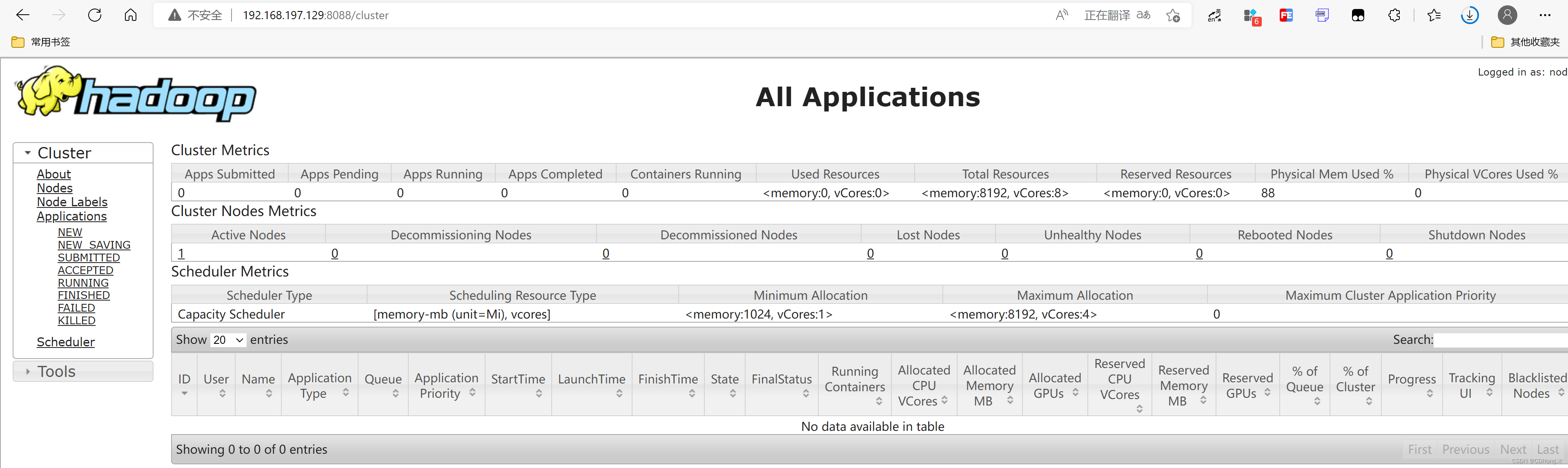
通过浏览器访问HDFS Web UI 界面
9870端口和 YARN Web UI界面8080端口
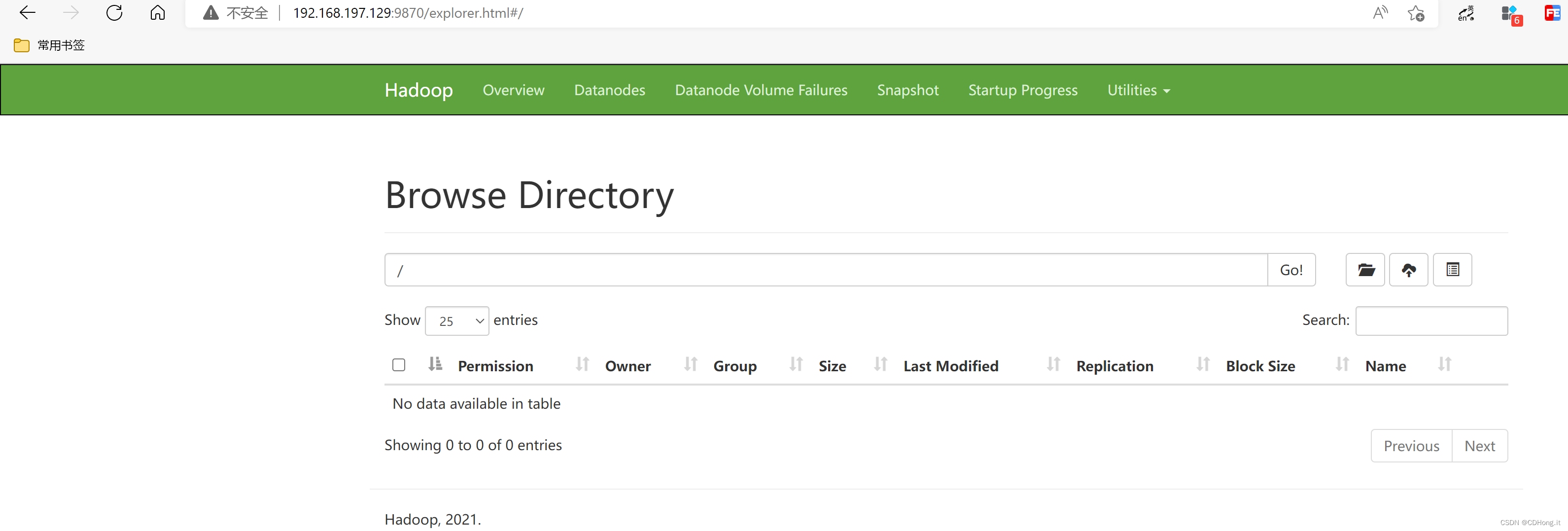
通过HDFS命令创建一个文件夹做测试
[root@node hadoop]# hdfs dfs -mkdir /test
[root@node hadoop]# hdfs dfs -ls -R /
drwxr-xr-x - root supergroup 0 2022-06-05 17:38 /test
运行 MapReduce提供的测试案例 PI
[root@node mapreduce]# yarn jar hadoop-mapreduce-examples-3.2.2.jar pi 2 2
Estimated value of Pi is 4.00000000000000000000
搭建HBase2.2.6伪分布式环境
安装HBase
[root@node src]# pwd
/usr/local/src
[root@node src]# tar -zxf hbase-2.2.6-bin.tar.gz
[root@node src]# mv hbase-2.2.6 hbase
export HBASE_HOME=/usr/local/src/hbase
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$HBASE_HOME/bin
[root@node src]# hbase version
HBase 2.2.6
配置HBase
修改
hbase-env.sh文件,指定HBase运行环境
[root@node conf]# pwd
/usr/local/src/hbase/conf
[root@node conf]# vim hbase-env.sh
export JAVA_HOME=/usr/local/src/jdk
修改
hbase-site.xml文件,添加如下代码:
[root@node conf]# vim hbase-site.xml
<configuration>
<property>
<name>hbase.unsafe.stream.capability.enforce</name>
<value>false</value>
</property>
<!--HBase 的数据保存到 HDFS 对应的目录下-->
<property>
<name>hbase.rootdir</name>
<value>hdfs://node:9000/hbase</value>
</property>
<!--是否是分布式环境-->
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<!--ZK快照存储目录 -->
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/usr/local/src/hbase/data/zookeeper</value>
</property>
<!--配置ZK的地址,就是当前机器的IP,或机器名 -->
<property>
<name>hbase.zookeeper.quorum</name>
<value>node</value>
</property>
<!--本地文件系统上的临时目录-->
<property>
<name>hbase.tmp.dir</name>
<value>/usr/local/src/hbase/data/tmp</value>
</property>
</configuration>
修改
regionservers,指定服务名
[root@node conf]# vim regionservers
node
启动服务
[root@node conf]# start-hbase.sh
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/usr/local/src/hadoop/share/hadoop/common/lib/slf4j-log4j12-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/usr/local/src/hbase/lib/client-facing-thirdparty/slf4j-log4j12-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class]
node: running zookeeper, logging to /usr/local/src/hbase/bin/../logs/hbase-root-zookeeper-node.out
running master, logging to /usr/local/src/hbase/logs/hbase-root-master-node.out
node: running regionserver, logging to /usr/local/src/hbase/bin/../logs/hbase-root-regionserver-node.out
[root@node conf]# jps
87779 HRegionServer
87618 HMaster
64759 SecondaryNameNode
65176 NodeManager
87560 HQuorumPeer
64362 NameNode
65019 ResourceManager
88316 Jps
64542 DataNode
HBase环境测试
浏览器访问 HBase Web UI 界面
16010端口,测试
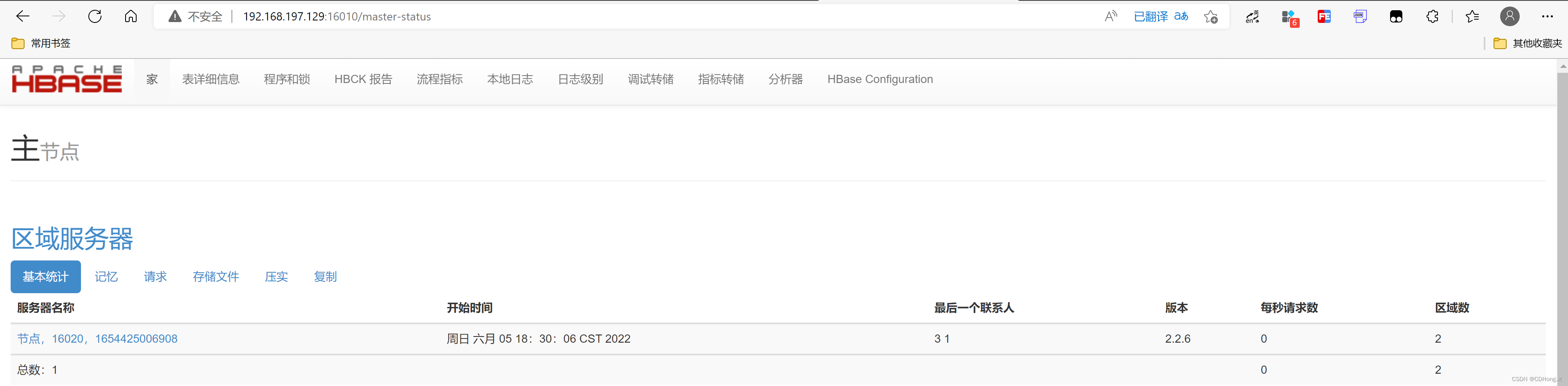
HBase Shell 名称创建数据库测试
[root@node conf]# hbase shell
HBase Shell
Use "help" to get list of supported commands.
Use "exit" to quit this interactive shell.
For Reference, please visit: http://hbase.apache.org/2.0/book.html#shell
Version 2.2.6, r88c9a386176e2c2b5fd9915d0e9d3ce17d0e456e, Tue Sep 15 17:36:14 CST 2020
Took 0.0099 seconds
hbase(main):001:0> create_namespace 'wise_db'
Took 0.9655 seconds
hbase(main):002:0> list_namespace
NAMESPACE
default
hbase
wise_db
3 row(s)
Took 0.1884 seconds
















 1444
1444











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











