









 HBase是一种建立在HDFS之上的非关系型数据库系统,支持高可靠性、高性能、列存储、可伸缩及实时读写。它适用于存储非结构化和半结构化的松散数据,通过主键(rowkey)检索数据,支持单行事务。本文详细介绍了HBase的基本概念、逻辑与物理结构、优缺点及其与Hadoop、Zookeeper的关系。
HBase是一种建立在HDFS之上的非关系型数据库系统,支持高可靠性、高性能、列存储、可伸缩及实时读写。它适用于存储非结构化和半结构化的松散数据,通过主键(rowkey)检索数据,支持单行事务。本文详细介绍了HBase的基本概念、逻辑与物理结构、优缺点及其与Hadoop、Zookeeper的关系。
之前我们一直在介绍hadoop,学习了两个核心内容HDFS和MapReduce。虽然HDFS可以存储数据,但是我们无法快速的查看所需的数据,这就需要引入另一个非关系型数据库HBase。
一、基本介绍
1、概念
hbase是bigtable的开源山寨版本。是建立的hdfs之上,提供高可靠性、高性能、列存储、可伸缩、实时读写的数据库系统。
它介于nosql和RDBMS之间,仅能通过主键(row key)和主键的range(排序)来检索数据,仅支持单行事务(可通过hive支持来实现多表join等复杂操作)。主要用来存储非结构化和半结构化的松散数据。
与hadoop一样,Hbase目标主要依靠横向扩展,通过不断增加廉价的商用服务器,来增加计算和存储能力。
2、逻辑结构
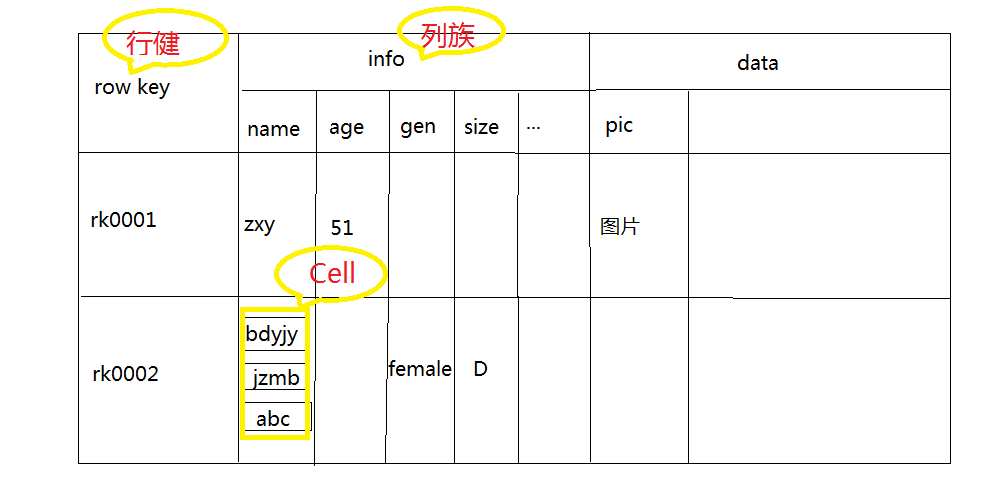
- Row Key
主键是用来检索记录的主键,Row key行键 (Row key)可以是任意字符串(最大长度是 64KB,实际应用中长度一般为 10-100bytes),在hbase内部,row key保存为字节数组。
存储时,数据按照Row key的字典序(byte order)排序存储。设计key时,要充分排序存储这个特性,将经常一起读取的行存储放到一起。(位置相关性)
访问hbase table中的行,只有三种方式
通过单个row key访问
通过row key的range
全表扫描- 列族
列族在创建表的时候声明,一个列族可以包含多个列,列中的数据都是以二进制形式存在,没有数据类型。
Cell
HBase中通过row和columns等
({row key, column( =<family> + <label>), version} )确定的为一个存贮单元称为cell。cell中的数据是没有类型的,全部是字节码形式存贮。时间戳
每个 cell都保存着同一份数据的多个版本。版本通过时间戳来索引。时间戳的类型是 64位整型。时间戳可以由hbase(在数据写入时自动 )赋值,此时时间戳是精确到毫秒的当前系统时间。时间戳也可以由客户显式赋值。
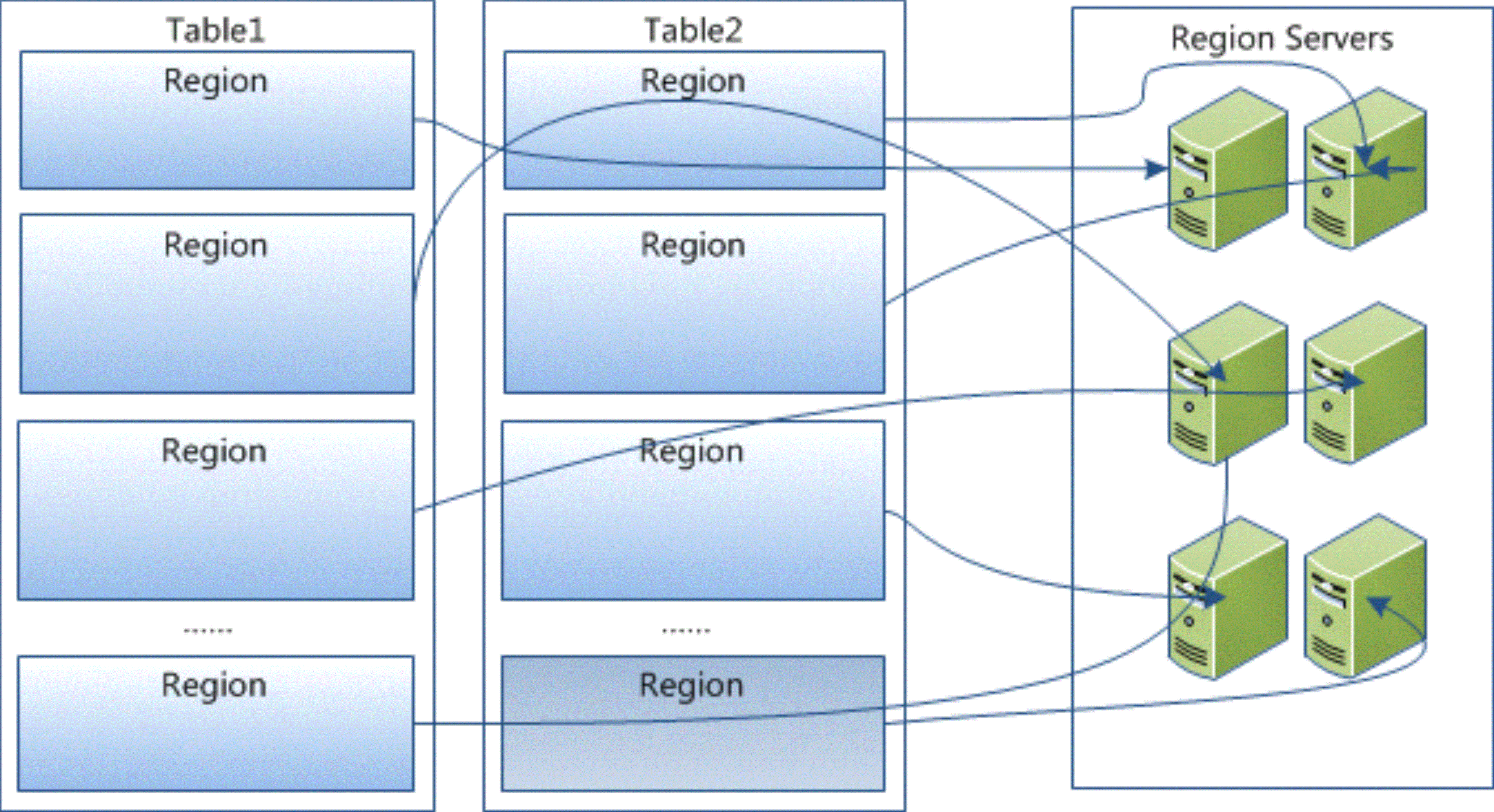
3、物理结构
Table 在行的方向上分割为多个HRegion,一个region由[startkey,endkey)表示,每个HRegion分散在不同的RegionServer中
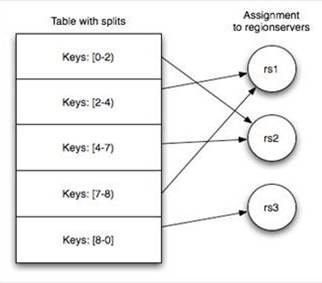
如下图所示,左侧为HRegion,右侧为RegionServer。当RowKey为233时,按照下图的分配方案,应存在rs1中。而RowKey为438的数据存储在rs2中。这样可以将数据分散开,从而提高性能。
4、优缺点
- 优点
列的可以动态增加,并且列为空就不存储数据,节省存储空间. Hbase自动切分数据,使得数据存储自动具有水平scalability.Hbase可以提供高并发读写操作的支持- 缺点
不能支持条件查询,只支持按照Row key来查询.因为hbase必须使用很大的内存,因此ygc和fgc的问题很麻烦。
fgc可能长达数秒钟,也就是说用hbase的系统可能会有数秒钟不可用。二、综合解析
1、三角关系
- Hadoop与HBase
经过Map、Reduce运算后产生的结果看上去是被写入到HBase了,但是其实HBase中HLog和StoreFile中的文件在进行flush to disk操作时,这两个文件存储到了HDFS的DataNode中,HDFS才是永久存储。
- ZooKeeper跟HadoopCore、HBase
ZooKeeper都提供了哪些服务呢?主要有:管理Hadoop集群中的NameNode,HBase中HBaseMaster的选举,Servers之间状态同步等。具体一点,细一点说,单只HBase中ZooKeeper实例负责的工作就有:存储HBase的Schema,实时监控HRegionServer,存储所有Region的寻址入口,当然还有最常见的功能就是保证HBase集群中只有一个Master。
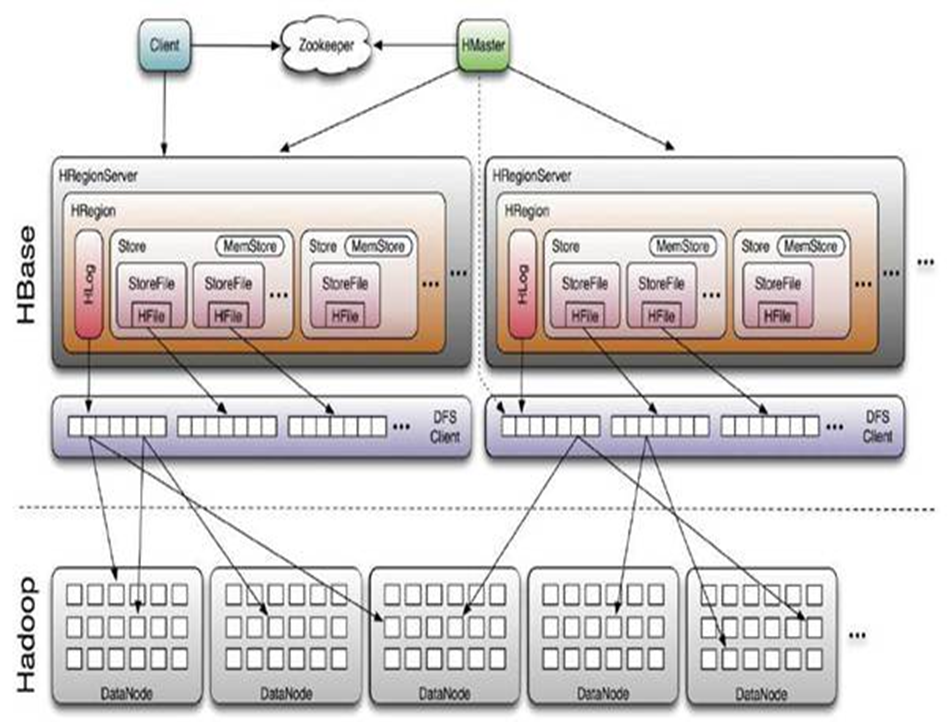
2、架构解析
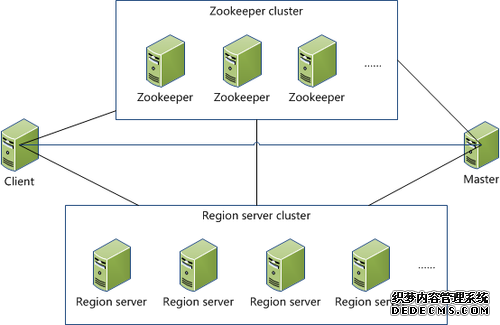
- Client
包含访问hbase的接口,client维护着一些cache来加快对hbase的访问,比如regione的位置信息。
- Zookeeper
1 保证任何时候,集群中只有一个master
2 存贮所有Region的寻址入口。
3 实时监控Region Server的状态,将Region server的上线和下线信息实时通知给Master
4 存储Hbase的schema,包括有哪些table,每个table有哪些column family
Master
1 为Region server分配region
2 负责region server的负载均衡
3 发现失效的region server并重新分配其上的region
4 GFS上的垃圾文件回收
5 处理schema更新请求Region Server
1 Region server维护Master分配给它的region,处理对这些region的IO请求
2 Region server负责切分在运行过程中变得过大的region
可以看到,client访问hbase上数据的过程并不需要master参与(寻址访问zookeeper和region server,数据读写访问regione server),master仅仅维护者table和region的元数据信息,负载很低。
3、根据目录的查找
HBase中有两张特殊的Table,-ROOT-和.META.
- -ROOT-
记录了.META.表的Region信息,-ROOT-只有一个region
- .META.
记录了用户创建的表的Region信息,.META.可以有多个regoin

HBase客户端的 HTable类访问用户数据之前需要首先找相应的RegionServers来处理行。他是先访问zookeeper,得到相应的“-ROOT-”的存放信息,然后根据这些信息找到“-ROOT-”表,得到 “.META. ”表的信息,然后找到“.META. ”表才能确定region的位置。定位到所需要的区域后,客户端会直接 去访问相应的region(不经过master),发起读写请求。这些信息会缓存在客户端,这样就不用每发起一个请求就去查一下。
总结:
由Hadoop的学习,我们引出了HBase的学习,知道了它是一种列式存储,在实际应用中需要结合zookeeper和hadoop一起使用。但是本文并没有介绍它的shell命令以及API接口等等,这些需要我们感兴趣的自己练练,实际操作操作,这样才能更加深刻得了理解。















 1349
1349

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









