








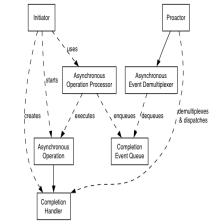

 https://blog.csdn.net/u010180372/article/details/123267951
https://blog.csdn.net/u010180372/article/details/123267951好了,目前整个系列文章已经开始往乱的行文结构去走了,准备烂尾,这个 proactor 以及封装什么的其实都讲完了。而且是代码怎么写都说了。然而,还有一些点没有讲清楚。
专栏内的所有笔记本身是和他们自洽的(也许漏了一篇讲如何理解协程和函数式编程中的 call/cc 的笔记,博客中也上传了,当然实际这系列笔记不是一个能够快速上手的,而是一个系列的学习,主要目的是供我自己复习或者有对 C++ 协程与 Proactor 网络框架编写感兴趣的读者。
我们从实际即 io_service/io_context 的部分开始,也是实际 event loop 的部分。
由于线程池我打算以用C++20 的 jthread 和 coroutine 结合的实现。开始讲解之前首先要熟悉一下 C++20 引入的 stop_xxx 即 <stop_token> 头文件提供的 Thread cancellation 的支持。为了方便,马克一篇笔记记录这个知识点。
C++20 Thread Cancellation | jthread | std::stop_token_我说我谁呢 --CSDN博客
说到 C++20,其实 C++20 还有一些动人的新特性比如 auto 参数简写函数模板等,实际可能总结一下比较好。我就不总结了,放点别人总结的吧。
10分钟速览 C++20 新增特性 - 知乎 (zhihu.com)
(2 封私信) Modern C++有哪些能真正提升开发效率的语法糖? - 知乎 (zhihu.com)
至于和协程、异步对对碰的新功能,或者像本文主题的 executor , facebook 的 libunifex 给出了一种实现, 标准委员会成员 Eric Niebler 在21 的 cppcon 做了主题演讲。不过 C++23 已经投票无了。其实下一个烂大街的项目魔改是不是就该基于 c++20 coroutine 和 libunifex 的服务器了.... (还是 Java 吧)。发现了一个 cpp 社区 purecpp,虽然页面不是很时髦,但是内容不错,里面有一些协程的讲解文章很详细明了。然后顺藤摸瓜发现 alibaba 十几天之前开源了一个 aync_simple 的 C++20 协程(同时还支持 uthread 有栈协程)的异步网络框架,然后他主要是提供 executor 和 协程的封装,比如 Lazy(饿,感受感觉这个就是 cppcoro 的 task 然后升级一下从而支持 他的 yield 和 executor),本身不是 IO 框架。(他还通过引入 asio 的 io 封装来用也是可以。。)
首先明白一下 executor 是什么,其实就是一个通用的接口,从而可以用它来实现 spawn 一个协程/函数的功能。那么他本身必须提供足够够用好用的接口。
具体可以通过这个提案来了解 executor 到底是什么。
A Unified Executors Proposal for C++ | P0443R14 (open-std.org)
这里针对 executor 的 motivation 翻译一下,其实就是 thread 太麻烦了(或者说太生了),然后 std::async (封装了 std::future)、future 这些又太抽象了,ref 说 potentially in a separate thread which may be part of a thread pool,但是你不知道题目是怎么调度的,也用不了。所以说 exectutor 本身就是要解决以往 std::async 他们的问题:
C++ must provide flexible facilities to control where and when work happens.
当然提案他给了很详细的设计文档了,具体可以参考 facebook 的 libunifex(unified execution)。当然我们完全可以直接用他的,不过这里还是实际了解一下如果要做一个简易版,我们需要做些什么。
下面先介绍一下 C++20 的一个新特性先。我们已经 auto 和 decltype(auto) 两种 placehodler type specifier 了。
复习一下 decltype 和没有的区别是,auto 等价模板推断(即优先去掉 cv 和引用,指定&才推导引用和 cv)、decltype(auto) 是用 decltype 推导,即原本的类型,具体还得看 reference。
然后 C++20 对 auto 引入了 type-constraint 的语法糖,就是可以让 auto 支持 concept 的 constraint 了(和模板里面的 concept 一样,concept、requires 这些新特性就不回顾了,忘记了的话就看别人的文章吧):

首先是执行的时间,支持的接口分别为 execute 和 schedule。execute 的话就是直接 spawn 了,可能会马上被运行。而 schedule 即创建一个 sender 计划,sender 可以通过 then 实现链式依赖的功能(当然这个是基本需求来的,io_uring 也支持依赖提交)。然后 receiver 则是一个 callback 的封装。scheduler 是具备 schedule 接口的类(比如 execution 类支持 schedule 接口),然后还有 submit 真正提交。普通的算法则包括 then、retry 等,语法糖有类似管道的 | 语法。
// make P0443 APIs in namespace std::execution available
using namespace std::execution;
// get an executor from somewhere, e.g. a thread pool
std::static_thread_pool pool(16);
executor auto ex = pool.executor();
// use the executor to describe where some high-level library should execute its work
perform_business_logic(ex);
// alternatively, use primitive P0443 APIs directly
// immediately submit work to the pool
execute(ex, []{ std::cout << "Hello world from the thread pool!"; });
// immediately submit work to the pool and require this thread to block until completion
execute(std::require(ex, blocking.always), foo);
// describe a chain of dependent work to submit later
sender auto begin = schedule(ex);
sender auto hi_again = then(begin, []{ std::cout << "Hi again! Have an int."; return 13; });
sender auto work = then(hi_again, [](int arg) { return arg + 42; });
// prints the final result
receiver auto print_result = as_receiver([](int arg) { std::cout << "Received " << arg << std::endl; });
// submit the work for execution on the pool by combining with the receiver
submit(work, print_result);
// Blue: proposed by P0443. Teal: possible extensions.
// 然后是一个 streamline 语法糖演示:
sender auto s = just(3) | // produce '3' immediately
on(scheduler1) | // transition context
transform([](int a){return a+1;}) | // chain continuation
transform([](int a){return a*2;}) | // chain another continuation
on(scheduler2) | // transition context
let_error([](auto e){return just(3);}); // with default value on errors
int r = sync_wait(s); // wait for the result他的具体解释可以看这里:
Towards C++23 executors: A proposal for an initial set of algorithms
不过其实就是一个前者的输出是后者的输入的语法糖而已。
好了,赶紧回到我们怎么实现上来,对于我们的需求,其实就是要求封装 coroutine 的 executor 而已,因为我们不需要做 unified。然后当然,实际主要 executor 无非是对 thread 的一个封装而已。thread_pool 可以有 executor,单个 thread 也可以有 executor,不同的是 thread_pool 的 executor 可以是不知道在哪个 thread 运行的(就如同上面说的,exec 等于 submit)。
io_context (event loop) 本身就可以是一个单线程的 executor。
回答一下 proactor 篇里面讲到的一个问题, task 协程需要能够获取自己所在的 executor,还是以 boost asio 的实现为例,我们知道这个 executor 实际就是 io_context 的循环线程的一个视图。
// 这段代码已经出现太多次了....
// 注意来自 asio 官方示例
awaitable<void> echo(tcp::socket socket) {
try {
char data[1024];
for (;;) {
std::size_t n = co_await socket.async_read_some(boost::asio::buffer(data),
use_awaitable);
co_await async_write(socket, boost::asio::buffer(data, n), use_awaitable);
}
} catch (std::exception& e) {
std::printf("echo Exception: %s\n", e.what());
}
}
awaitable<int> listener() {
auto executor = co_await this_coro::executor;
tcp::acceptor acceptor(executor, {tcp::v4(), 55555});
for (;;) {
tcp::socket socket = co_await acceptor.async_accept(use_awaitable);
co_spawn(executor, echo(std::move(socket)), detached);
}
}
int main() {
try {
boost::asio::io_context io_context(1);
boost::asio::signal_set signals(io_context, SIGINT, SIGTERM);
signals.async_wait([&](auto, auto) { io_context.stop(); });
co_spawn(io_context, listener(), detached);
io_context.run();
} catch (std::exception& e) {
std::printf("Exception: %s\n", e.what());
}(asio 的这部分实现是十分迂回丑陋的,无法学习了) 我们当然可以有一个简单实现思路,那就是在 co_spawn 上做手脚,这样第一次 co_await 一个 task(协程)的时候,让 task 获取到 executor,然后存起来。但是你很容易发现,我们在一个线程里能通过 C++ 多线程库获取到的信息只有什么?只有 thread(通过 std::this_thread::get_id()),如果你想把 thread 和 executor 绑定起来,势必要编写一套并发的线程管理器(如果是 thread_pool 的 executor 的话,就会有多个 thread 的 executor 是同一个),其中还要用 map 来进行 id 到 executor 的映射查询。
其实我们真的需要获取到本线程的 executor 才能 co_spawn 吗?回到 cppcoro 的实现里面,有一个 acync_scope 来实现我们系列笔记讲的 async void (实际为 one way task),所以一个解决方案就是(然而并不能解决本身如 tcp_acceptor 他自己就要绑定一个 executor 从而能投递到正确的 io_uring fd 上,这个前面讲 asynchronous operation 那篇讲过了), listener 根本不需要获取自己所在 thread 的 executor 再 co_spawn,他只需要直接 one way task 运行即可。至于如果要往线程池去走,那势必要走全局共享变量的(即我们编写的线程池)。所以目前这个问题也是有一个很好的思路的了,不用走 asio 那种迂回路线。(只能说是 asio 本身对支持的的协程种类太少了?还是我读的文档太少了,基本没找到除了 awaitable 和 experimental::coro 两种以外的)。当然,其实对于抽象来说,如果我们就用线程池的思路,那么获取当前 executor 其实也算是一个抽象的需求吧,当然实现一个也不是很麻烦。
一种简化版的协程异步网络库实现其实可以基于 cppcoro 和 libunifex 把协程和 executor 的语言特用框架代码给魔改一下,然后主要工作重心放回 socket 编程和 io 的封装上。不过实际上,libunifex 他本身其实已经写好了 linux::io_uring_context 这个模块了。
然后另外补充一个点,就是如果你要写异步库,对于 file 的封装也是必要的,从而能够支持直接 co_await file.recv_some 这种操作进行异步,而不是 socket 完全依赖于对 socket_t 封装 liburing 的接口(这样写的话必须走 detail namespace 了,还有可以同时支持 Windows 的IOCP)而不支持普通的文件等。
线程池本身的话我也不赘述了,因为通过协程状态机和 jthread 实现线程池是一个很简单的。比如 co_await 一个 awaitable,然后捕获了 continuation 到另一个线程里面 resume 就行了。
但是他的调度却有一个问题。此时我们是不是等于写用户态的 CPU 调度了(此时我们拥有的不是CPU,而是虚拟的 CPU,即线程)? 这个涉及到你的线程池的逻辑了,这个可能回想对于之前学习 asio 是怎么通过 epoll 模拟异步的思路有参考价值,但是 asio 明显是一个异步请求就开一个线程去模拟,本质和 reactor 没什么区别,即用户写 proactor 向代码,asio 按 reactor 执行。当然线程池本身可以动态扩容收缩,但是最多也不可能做几千几万个线程(一个进程几百个线程可能就已经很卡了,虽然本身 OS 上整体可能运行十万个线程)的啊。这里就晕了,对于耗时的任务,还有个皮皮虾的高并发啊....
所以回到 Reactor 模式的思路,也就明白本身也是基于线程多线程每个线程单线程复用的思路的,即运行 event loop,不断地运行 callback。当这个 connection read 或者 write 的过程也是不断地向 epoll 投递的,你就明白了。即我们抽象一个 TcpConection 出来的时候,他本身就是不断地响应读关注然后唤醒后把 callback (只读写一部分)送给 worker 去执行。
好了,回来 Proactor 了,我们明白一个道理才行,即线程池只能用来执行 compute bound 的 task,而不能执行协程本身。了解了这一点,一切就恍然大悟了。因此确实就和 java 的线程池那样,不需要什么公平调度,因为百万并发本身是由循环实现的,而不是线程。















 790
790

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









