









 https://blog.csdn.net/u010180372/article/details/123267951
https://blog.csdn.net/u010180372/article/details/123267951专栏内的所有笔记本身是和他们自洽的(也许漏了一篇讲如何理解协程和函数式编程中的 call/cc 的笔记,博客中也上传了,当然实际这系列笔记不是一个能够快速上手的,而是一个系列的学习,主要目的是供我自己复习或者有对 C++ 协程与 Proactor 网络框架编写感兴趣的读者。
接下来是对接 io_uring。首先梳理一下层次结构,我们第一次明白这个一层一层的缓冲区和处理没写完、没读完的这个应该会在 CSAPP 里面学到,当然 CSAPP 本身也是对 UNP 的精粹而已,所以实际学 UNP 的时候可能印象会比较深刻那个时候封装了一套接口给上层用。所以这里只是权当复习一下。
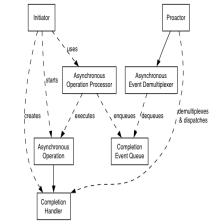
考虑我们作为网络框架,对最终用户来说肯定是不要他考虑写没写完读没读完的情况的。所以我们需要提供一个足够大的缓冲区放用户给的东西,然后我们保证我们最终能写完就行了。当然,这些都是基本功了,不过游双的那本 Linux 高性能服务器书虽然分析了 libevent 的一些源码,但是好像没有讲到 buffer 的部分,陈硕的 muduo 那本书倒是很具体讲了缓冲区的编写,包括环形以及扩容。这次我们以 Proactor 的写为例整个层次和运行是这样的(使用画图绘制):

io_uring by example: Part 1 - Introduction - Unixism
上面这个链接文章这里对比了 readv 的 cat 和 io_uring 的 cat,可以发现使用 readv 的时候,他是通过一个循环来进行如果 bytes_remaining 的 io_vec 的构建的,io_uring 也是这样他一次会提交一个 sqe 为 readv 请求,然后多个 iovec 指定了,从而直接一次 submit 把整个文件给读完。
For example, with readv(), you can fill in many members of a structure without either resorting to copying around buffers or making multiple calls to read(), both of which are relative inefficient. The same advantages applies to writev(). Also, these calls are atomic while multiple calls to read() and write() are not, should you happen to care about that for some reason.
这里为什么 cat 要用 separately allocated 的 buffer 来放呢?我的唯一猜想是因为一次分配大块的内存会减少利用率,而分散分配的可以利用上碎片?所以之后讲到涉及大块文件编程时候可能都会用上这个向量化读写。

当然,对于 socket 的应用的话就不是这样的,因为你不知道能读写多少(不过 muduo 的 readFd 也用了,当然本身循环的buffer我们也可以用这个来实现一次 syscall 的读入写出什么的)。cat 例子中,iovec 的分块是通过每次调用 posix_memalign 分配对齐的大小为 BLOCKSZ = 4KB 的内存来做的,因为磁盘保证了一次能够读写 4KB,对齐的内存是因为可能dma 或者硬件复制的逻辑上没有处理不对齐的情况(比如可能地址直接节约了低位?存疑)。
然后再谈论一下真异步的 buffered Io 是否真的有什么效率提升?问题回到 disk 上来,对于 disk 的异步 IO,io_uring 到底异步了个啥?我们都知道文件的读取是耗时的操作,首先提到 buffer 的存在(io_uring 比 linux aio 支持多了 buffered io,2006 以前早期的 posix aio 是通过 glibc 用 pthread 做的假异步):
for each file page to be read
get the page into the page cache
copy the contents to the user buffer
来自 <Asynchronous buffered file I/O [LWN.net]> (lwn 2007 一个文章表示 buffered io 也可能可以实现 async,后面的补丁不知道有没有采用,反正我自己没有用过 linux aio)
我现在来描述(乱说的)一下这个完全异步的怎么实现吧,直接下潜到驱动层,请求一个 page 的时候或者写,都是对硬件发请求,等待应答的,而且一般是存在类似 DMA 的东西,所以像 Windows IOCP 的 there is no thread (There Is No Thread (stephencleary.com))的实现是可能的,因为本来你提交了请求之后,到读写完成的应答得到,就是要花一段时间的,而这些时间可能是花在了硬件上,而不是走 CPU,所以 there is no thread 是存在的。那么如果他不占用 CPU 原来的你调用 read 的时间花销是什么呢?难道是等待这个硬件的读写完成数据包发送到 OS 中?(比如 pcie 就是走类似tcp那种数据包模式的)这个我就存疑了,为什么呢,因为我确实不懂。考虑写 8086 读取的代码我们学到了什么,为了判断是否读写完成从而返回或者进行下一个快(say 4kb 一个快)的传输,我们实际是通过 loop 汇编来检查寄存器的,如果这个为真,那么说明浪费的开销在于轮询寄存器?但是新的硬件不是都不会说通过读寄存器来确认的吧,所以现在实际是怎么的我就不明白了。(当然这样你能直接理解 aio 本身的性能就不差了,尽管他支支持了 direct io)。这里网上偷一个图(表示 O_DIRECT 的 Linux aio 的性能提升在哪里):

然后对于 io_uring 的 buffered io,上面的lwn文章链接里面描述了一种可能的做法(2007)。实际 io_uring 怎么做的,看邮件列表、commit log 和源码吧。
当然,有必要顺便说一下 Reactor 是怎么实现的。

然后Reactor里面,一种要点是像这种 tcp_connection 类,他本身肯定要支持析构、shutdown 取消挂在 Poller 的。Poller、Channel 的概念是 Netty 的,其实就是 epoll 的封装和 descriptor 在 epoll 上的存在形式,到 io_uring 中,poller 因为是 reactor 的概念,所以不关我们的事,channel 在 epoll 里面其实就是 epoll_event, 对 io_uring 同样的由于我们一次用一个新的 sqe(注意他的 sqe 不是直接在 lockfree queue里面的,还有一层中转,这个看之前他的笔记就知道的,当然io_uring 本身也支持固定一部分从而可以反复提交)所以也没用了。
本来这一篇笔记应该还有一个 io_uring 的 API 使用的,但是这里就没有时间了,就这样吧。其实前面分析 io_uring 备注过一部分了,不过还是要做,目前最好的 io_uring 、liburing 资料还是 unixism.net 的。















 2468
2468

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









