






 介绍了一种使用Python脚本批量下载特定网站上PDF文件的方法,包括解析网页结构、筛选有效链接及实现自动化下载。
介绍了一种使用Python脚本批量下载特定网站上PDF文件的方法,包括解析网页结构、筛选有效链接及实现自动化下载。
某日要下载网页中所有的PDF文档,大约400个。作为计算机专业的学生,显然不能手工去下载啊!!!于是在网上找到了相关的批量下载文档脚本,众里寻他千百度,终于在一篇博客http://blog.csdn.net/waylife/article/details/41021641中找到最贴切的脚本代码。
然而,我略加修改,始终会出现问题,对于从未爬过虫的小白,慢慢的开始分析网页结构:
对于上述博客,可以发现其下载的PDF文档都在根链接http://ww0.java4.datastructures.net/handouts/目录下,输出根链接的html/xml【在代码中print soup即可查看】,会发现所有的PDF文档以<a href="pdfname.pdf">PDF handounts</a>格式存在:
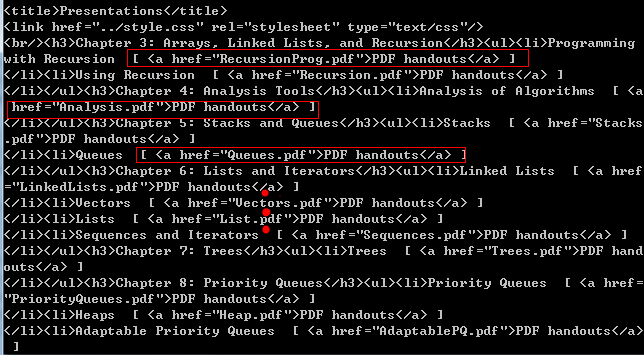
因此提取该html/xml中所有的pdfname.pdf,然后拼接根链接,如http://ww0.java4.datastructures.net/pdfname.pdf,即可得到该pdfname.pdf指定的网页,从而进行下载。
但是对于我要下载的网页http://www.screenplaydb.com/film/all/2/,其结构更为复杂。当点击“Download”按钮后,会跳转到另一个链接:http://www.screenplaydb.com/film/scripts/away_we_go.pdf:
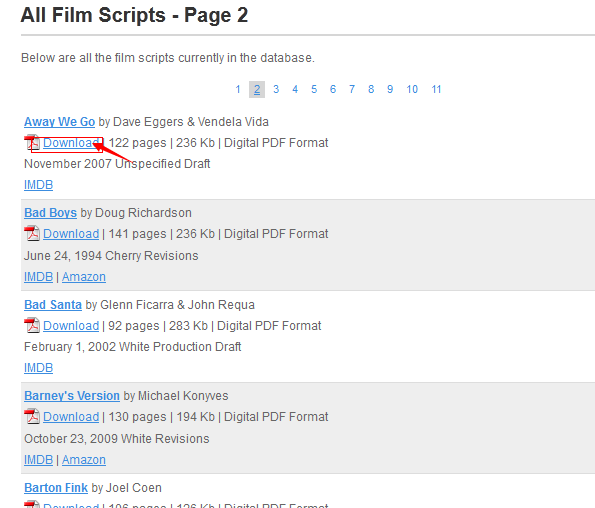
然而所有的PDF文档却又不在根链接http://www.screenplaydb.com/film/scripts/ 或http://www.screenplaydb.com/film/all/2/目录下,那所有的PDF存在哪里呢???
我将下载网页http://www.screenplaydb.com/film/all/2/ 的html/xml 输出研究:
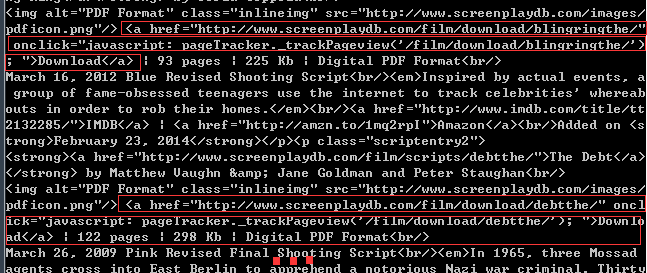
看到了吧,结构更复杂了!!!PDF文档所在的位置竟然在链接http://www.screenplaydb.com/film/download/目录下。当在浏览器中打开该链接时,发现又调转到其他链接中去了。不过这里不重要,我们以及找到PDF所在的位置,只需要从html/xml中提取即可。
问题有来了,如果直接通过本文开头所说的博客中的方法提取,会发现有很多无效链接!!为此我们需要筛选,将匹配字符串设为http://www.screenplaydb.com/film/download/进行筛选可获得PDF的URL,如http://www.screenplaydb.com/film/download/blingringthe/
根据提取到的URL,直接进行下载即可。
完整脚本如下:
import requests
import re
from bs4 import BeautifulSoup
from os.path import basename
from urlparse import urlsplit
import urllib2
#########global variable###############
savePath = "F:\\temp\downloadFile\ "
matchingUlr = r"http://www.screenplaydb.com/film/download"
#######################################
def url2name(url):
return basename(urlsplit(url)[2])
def download(url, localFileName = None):
localName = url2name(url)
req = urllib2.Request(url)
r = urllib2.urlopen(req)
if r.info().has_key('Content-Disposition'):
# If the response has Content-Disposition, we take file name from it
localName = r.info()['Content-Disposition'].split('filename=')[1]
if localName[0] == '"' or localName[0] == "'":
localName = localName[1:-1]
elif r.url != url:
# if we were redirected, the real file name we take from the final URL
localName = url2name(r.url)
if localFileName:
#force to save the file as specified name
localName = localFileName
saveLoc = savePath + localName
f = open(saveLoc, 'wb')
f.write(r.read())
f.close()
def getDownloadURL(root_link):
r=requests.get(root_link)
if r.status_code==200:
soup=BeautifulSoup(r.text,"lxml")
print 'soup=',soup
patten = re.compile(matchingUlr)
matchSum = 0
for link in soup.find_all('a'):
new_link=link.get('href')
#print 'new_link=',new_link
if patten.match(new_link) :
matchSum = matchSum + 1
download(new_link)
if matchSum > 1:
break;
return matchSum
if __name__ == "__main__":
root_url0 = 'http://www.screenplaydb.com/film/'
for x in range(2,12):
root_url = root_url0+str(x)+"/"
print "root_url=",root_url
downloadSum = getDownloadURL(root_url)
print 'film ', x , 'download successfully:',downloadSum
print '-----------------------------------'
















 2553
2553

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









