






天命:只要没反爬,一切都简单
这次爬取的是绿盟的威胁情报的PDF
先看一下结构,很明显就是一个for循环渲染

burp抓包会发现第二次接口请求
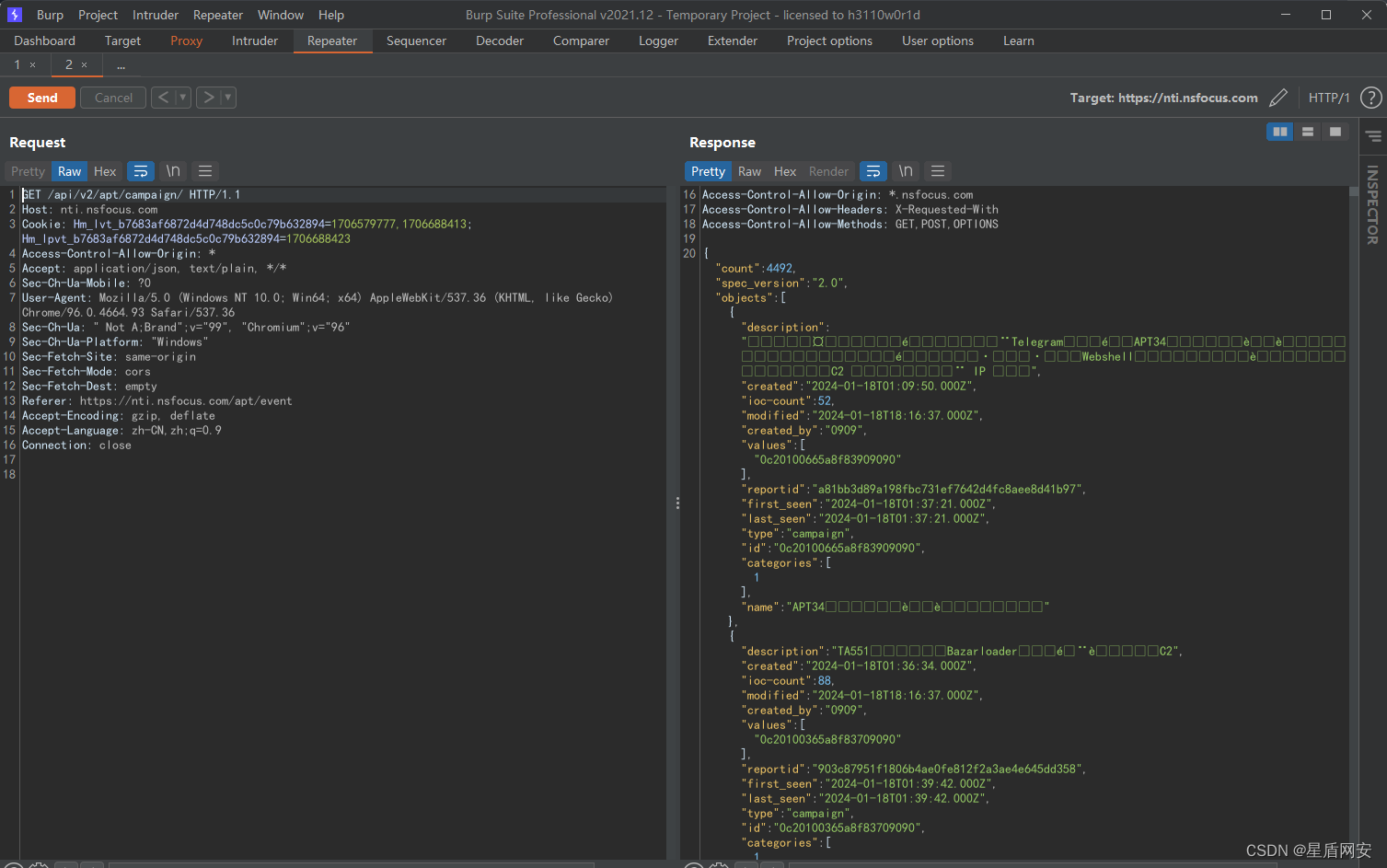
接口请求一次就能获取到了所有的数据
然后一个循环批量下载数据即可,其实没啥难度的
import requests,os
res = requests.get("https://nti.nsfocus.com/api/v2/report/notie/?page=1&size=200&order=reported")
data_dict = res.json() # 提取json格式
当前相对路径 = os.getcwd() # 获取绝对路径,每个人电脑不一样,所以预算是相对路径
os.mkdir("PDF") # 在当前文件夹下,创建一个PDF文件夹
# 提取data字段
data = data_dict['data']
for 数据 in data:
日期 = 数据['created']
日期 = 日期.split("T")[0]
标题 = 数据['title']
文件名 = 数据['children'][0]['file_name']
url = "https://nti.nsfocus.com/api/v2/report/pdf/?file="+ 文件名
最终文件名 = 日期+标题+文件名
response = requests.get(url, stream=True) # 开始下载文件
f = open(f"{当前相对路径}\\PDF\\{最终文件名}","wb")
for 文件流 in response.iter_content(chunk_size=1024): # 应该是提取每一页
f.write(文件流) # 把每一页写入PDF中
print("文件已下载")















 464
464











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











