





一、高可用性HA介绍
高可用(High Availability,简称HA)是系统架构设计中必须考虑的因素之一,它通常是指,通过设计减少系统不能提供服务的时间。通常以百分比表示,高可用性不是绝对的,只有相对更高的可用性。100%可用性是不可能达到的。可用性的“9”规则是表示可用性目标最普遍的方法。
SLA:服务等级协议(简称:SLA,全称:service level agreement)。是在一定开销下为保障服务的性能和可用性,服务提供商与用户间定义的一种双方认可的协定。
高可用性实际上意味着“更少的宕机时间”。导致宕机的原因可能有CPU过载/内存耗尽、磁盘问题导致无法读写、网络异常终端等。
二、GaussDB逻辑架构介绍
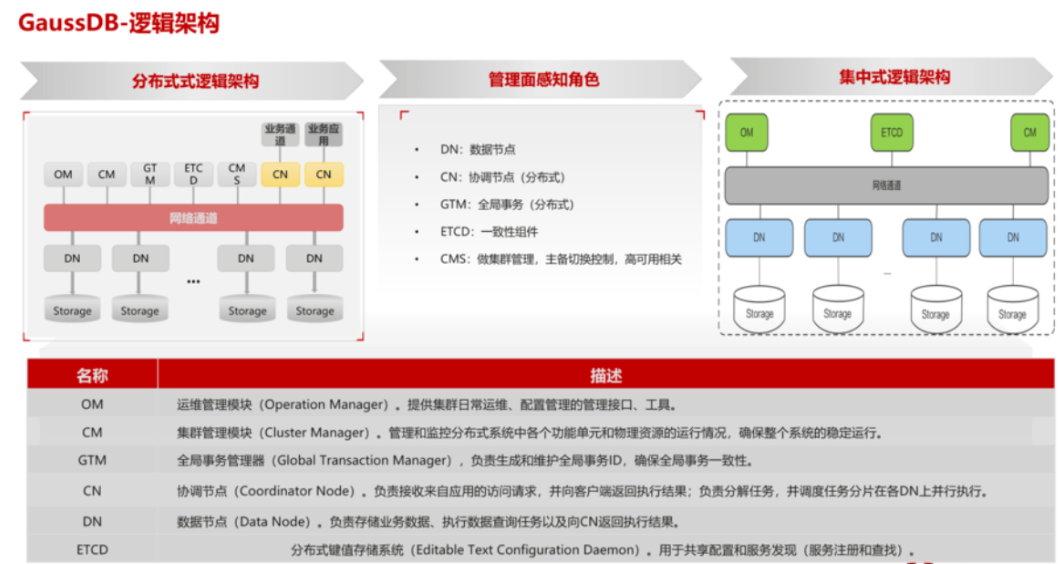
2.1业务流程
业务应用下发SQL给CN,SQL可以包含对数据的增(insert)、删(delete/drop)、改(update)、查(select)。CN接收解析后发送给所有DN执行,DN按照执行计划的要求去对数据进行处理返回结果给CN,由CN统一返回给客户端,这样完成一次SOL的交互。因为数据是通过一致性Hash技术均匀分布在每个节点,因此DN在处理数据的过程中,可能需要从其他DN获取数据,GaussDB 提供了三种stream流(广播流、聚合流和重分布流)来降低数据在节点间的流动。DN将结果集返回给CN进行汇总。CN将汇总后的结果返回给业务应用。CN个数越多,则处理的客户端并发请求数越多。DN个数越多,则存储规模和并行能力越强。
2.2各组件功能
(1)OM:运维管理模块Operation Manager)。提供集群日常运维、配置管理的管理接口、工具。它集成了很多分布式管理工具。
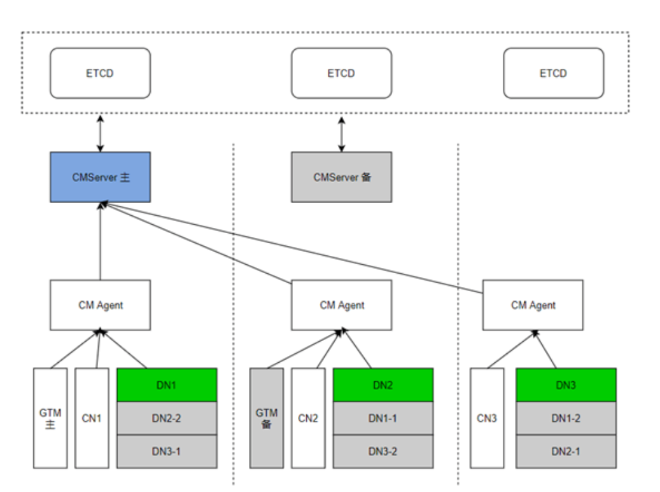
(2)CM:集群管理模块(cluster Manager),管理和监控分布式系统中各个功能单元和物理资源的运行情况,确保整个系统的稳定运行。主要关注系统中各个功能单元的启动停止状态。它包含了2个角色:CM Agent和CM Server。CM Agent存在各个服务器上,主要用于采集各个服务器上进程的心跳数据,采集回来后将数据上报给CM Server,CM Server根据进程的状态会对数据库节点进行仲裁。如果遇到节点硬盘故障等问题,CM Server会做出仲裁,将这些节点进行主备倒换、重启等操作。CM组件主要分为四个子模块:
· cm_server:集群管理的大脑,整个管理系统的仲裁者,系统中只有一个,主备架构,系统中常驻的服务进程,多线程架构。主要收集cm_agent返回的各个实例(GTM主备、CN、DN主备从)状态信息,从而通过分析给出谁是主谁是备,什么时候需要failover切换,什么时候需要重建DN。集群的拓扑信息保存在ETCD中。
· cm_agent:集群管理的实际执行者,负责监控实例和节点各组件的运行状态,并将状态上报给CM Server;执行CM Server下发的仲裁指令接收cm_server的命令后,操作本地的各个实例,顾名思义,cm_agent的分布与集群物理机数量相关,每台物理机一个cm_agent,常驻进程,多线程架构。负责各个实例的启动、停止、主备switchover、备机failover、仲裁主备等命令的下发。任何一个实例(包括cm_server进程)因异常停止后,cm_agent检测到即会重新拉起。
· om_monitor:看护CM Agent的定时任务,启动集群后如果cm_agent异常停止后,它会拉起cm_agent。由于任何一个实例终止后由cm_angent拉起,cm_agent终止后,由om_monitor拉起,om_monitor挂掉后,由操作系统的crontab,定时检测om_monitor,如果不存在便拉起。这样便完成了一个完全自动化的管理。om_monitor是系统中常驻进程。
(3)GTM:全局事务管理器(Global Transaction Manager),负责生成和维护全局事务id、事务快照、时间戳等全局唯一的信息。因为DN是并行计算的,分布式架构下为了保证事务的ACID特性,需要生成全局唯一的事务ID,GTM就可以用来生成全局性的事务ID。
(4)ETCD:分布式键值储存系统((Editable Text Confguration Daemon)用于共享配置和服务发现(服务注册和查找)。CMAgent采集的状态信息,或注册表临时信息,会存放在ETCD。CM Server会从ETCD获取状态信息,然后对集群进行运维管理。用于集群监控以及服务注册发现。提供原子的CAS(Compare-and-Swap)和CAD(Compare-and-Delete)支持。用于分布式锁以及leader选举。
(5)CN:CN名为协调节点(Coordinator Node),是所有客户端(gsql,jdbc,odbc等)的入口,客户端连接CN,发送SQL,CN接收解析后发送给所有DN执行,执行完后返回结果给CN,由CN统一返回给客户端,这样完成一次SQL的交互。系统中常驻的服务进程,多线程架构。CN在系统中可以有1个或多个,每个相互独立,通常每个物理机器布置一个,由于其主要记录表中元信息,每次的DDL所有CN都需要参与,因此它不需要做备份,所有CN互为备份,坏了一个可以采用另外一个CN恢复。
(6)DN:DN名为数据节点(Data Node),主要受CN控制,系统中DN可以有多个,数据采用hash等方式分布在各个DN中,相互独立。在CN上主要执行的有解析器、优化器、分布式事务等。其它大部分任务由DN上执行,比如有行引擎、行存储、向量化引擎、列存储、HA等。
(7)Storage:服务器的存储资源,持久化存储数据。
三、GaussDB高可用架构
通过守护进程、硬件冗余、实例冗余、数据冗余,实现整个系统无单点故障
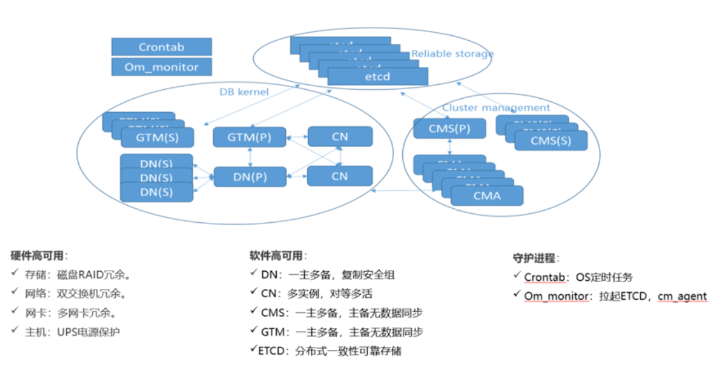
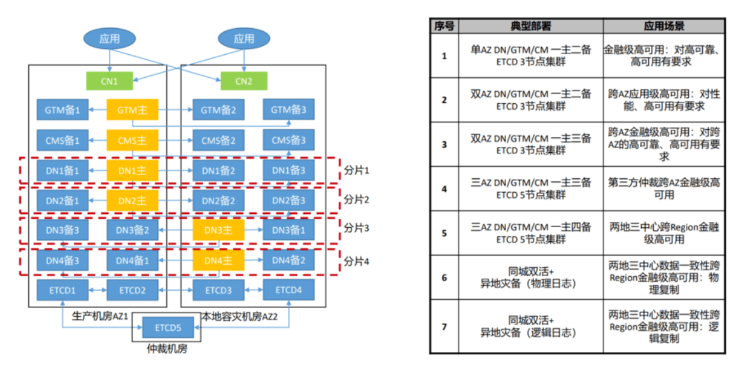
3.1GaussDB典型高可用部署方式
四、集群管理架构
4.1集群组件介绍
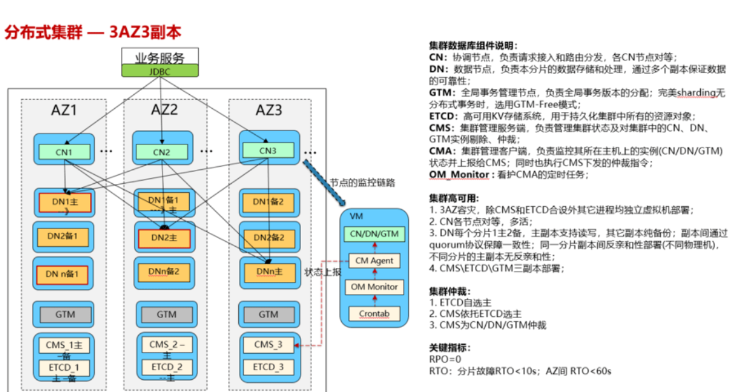
集中式实例包括的组件有:DN、CM(由CMServer、CM Agent、OM Monitor组成)ETCD、
分布式实例包括的组件有:DN、CM(由CMServer、CM Agent、OM Monitor组成)ETCD、CN、GTM
4.2CM模块
CM模块中又分为CMS和CMA。
4.2.1CMS/CMA模块设计
4.2.2CMS模块
CMS是整个集群的大脑,其主要作用为:根据Agent上报的各实例节点状态信息来仲裁实例是否需要状态变更,以及需要哪种变更。正常场景下,集群需要有且只有一个CMS主进行相关仲裁动作,CMS会定期向ETCD写心跳数据,如果集群中CMS主发生故障,需要通过ETCD仲裁选主(后面会具体介绍ETCD组件)。
CMS负责集群中各GTM、CN、DN实例状态的监控,以及每一对GTM,DN主备HA角色的仲裁,集群能否稳定运行以及在发生单点故障后,备实例能否正常切换为主来保证集群的可用性,都与CMServer是否稳定相关。
4.2.3CMA模块
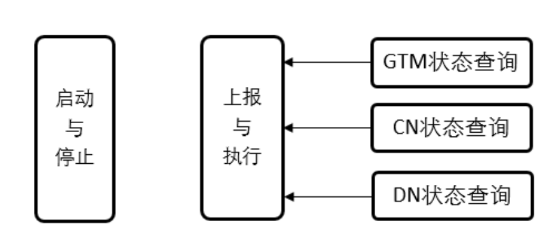
CMAgent的主要功能包括启动本节点所有实例,停止本节点所有实例,监控上报本节点所有实例状态,执行CMServer下发的命令。
CMAgent是多线程监控组件,线程包括:
1).主线程负责上报节点实例状态,以及执行CMServer下发的命令。
2).启停线程负责启动和停止节点实例。
3).与GTM/DN/CN连接线程负责查询实例状态。
4.2.4集群管理主要功能
实现集群、AZ、节点、实例的启动和停止,
提供集群状态查询、主备切换、备机重建等基本功能
实现对集群内进程、磁盘、网络、日志的监控和处置
实现对CN、DN、GTM节点故障检测与仲裁
实现自动升降数据库副本
多AZ网络故障检测与仲裁
少数派强起与加回
五、集群启停流程
5.1集群启动
集群启动时先拉起CMA和ETCD cluster,正常启动后,由CMA顺序拉起CMS、GTM、CN实例,并发拉起本节点所有DN实例,CMA成功拉起进程后,先进行CMS主备仲裁并执行升主降备操作,CMS有主后,仲裁GTM/DN主备并执行升主降备操作。同时启动检测线程,通过新增轻量化集群状态查询接口方式,仅获取cluster status,提升检测线程效率及性能,降低耗时,如下图所示。
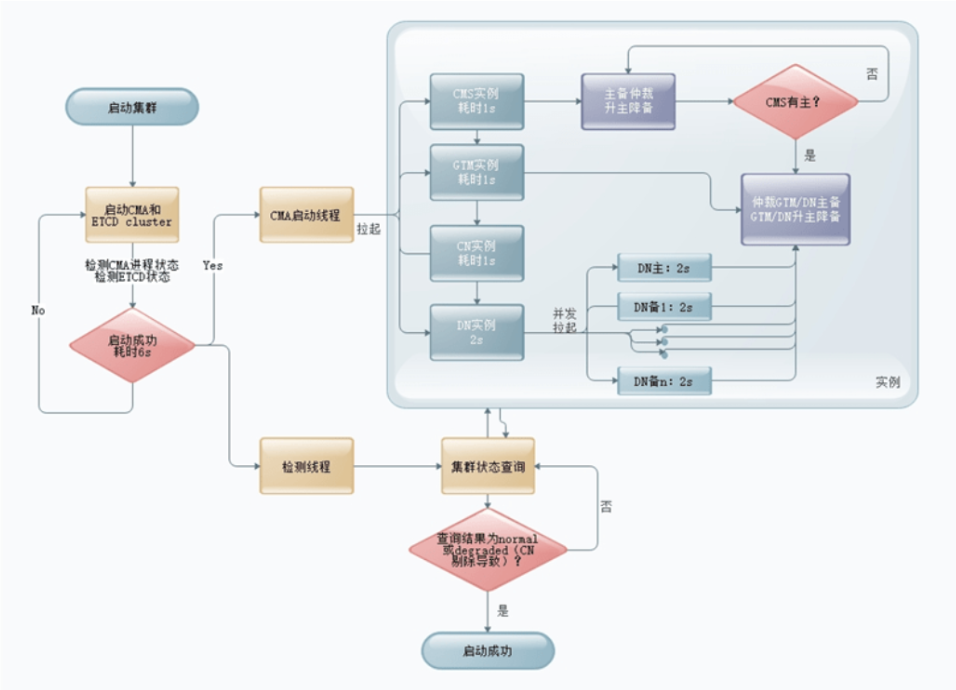
启动集群:
1.启动CMA和ETCD cluster,其中包括CMA进程拉起(1s)ETCD进程拉起、状态检测、ETCD选主(6s),共耗时6秒。
2.ETCD cluster正常启动后,CMA依次拉起CMS(1s)、GTM(1s)、CN(1s)、DN(2s)实例,其中DN实例由串行拉起优化为并发拉起。
3.实例拉起后,CMS启动自仲裁及升主降备操作(5s),选出CMS主后,启动GTM、DN主3.
备仲裁及升主降备操作,以及CN为normal过程。
4.步骤1中ETCD cluster正常启动后,启动检测线程,通过新增轻量化集群状态查询接口方式,仅获取clusterstatus,并返回给CMS。
5.CMS收到集群状态为normal或degraded(因CN剔除导致),视为集群启动成功。
5.2集群停止
集群停止时,CMS收到停止命令后下发给所有CMA,CMA启动实例停止线程,依次停止CN、DN、GTM、CMS和fenced,并检查实例是否存在,若存在则继续停止;不存在则退出自身进程。同时,采用节点级并发,检测CMA进程状态。CMA进程退出后,开始停止ETCD cluster,同时并发检测ETCD进程状态,所有进程退出后,视为集群停止成功,如下图所示。
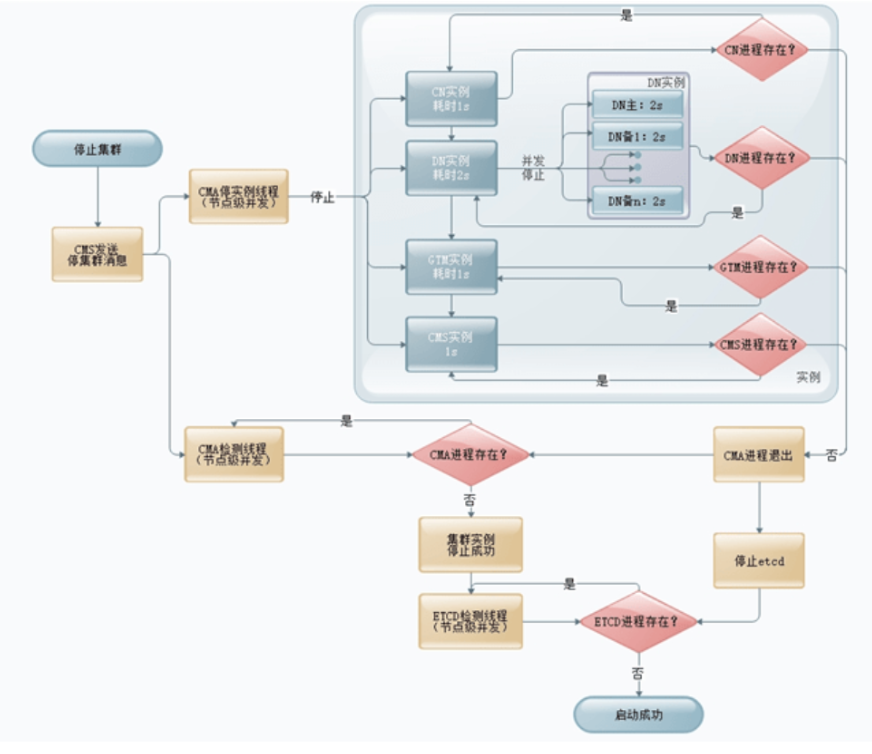
停止集群:
1.CMA启动实例停止线程,依次停止CN(1s)、DN(2s)、GTM(1s)和CMS(1s)、fenced(1s),同时检测实例状态,若某个进程仍存在,则再次停止该进程。
2.所有实例进程退出后,CMA退出自身进程,优化CMA进程退出时,与CMS的连接线程仍2需等待超时的逻辑。
3.步骤1、2进行的同时,启动检测进程,节点及并发检测CMA进程状态。每次查询记录CMA进程仍存在的节点至stoppinglist,每次增量检测stopping node list中节点的CMA进程状态。
4.对断网节点、已卸载节点视为已停止节点,并适配。
5.所有节点CMA进程退出后,开始停止ETCDcluster,同时并发查询ETCD进程状态,优化方案同步骤3。
6.检测到所有ETCD进程退出后,视为集群停止成功。
5.3集群组件依赖路径
5.3.1集群启动依赖路径
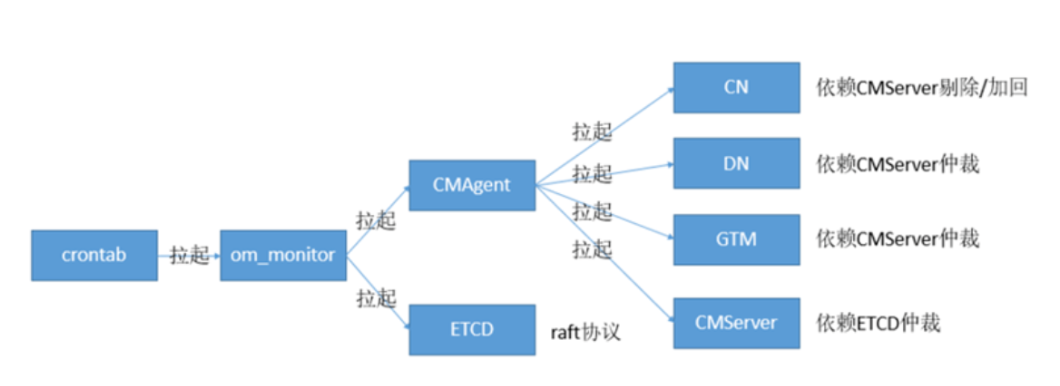
Monitor:进程故障由crontab系统定时任务拉起。
CMAgent:进程故障由Monitor拉起。
CN:进程故障由CMA自动拉起,拉不起的话会剔除(25s)否则会阻塞数据库执行DDL。通过CN节点加回,可以恢复故障CN。
DN:进程故障由CMA自动拉起,拉不起的话会主备切换。CMS仲裁从半数以上DN中选择日志量最全的节点升主。采用1主3备或1主5备方式部署,日志在多数派DN上落盘之后事务才提交。备机故障(少数派)不影响主机业务。
GTM:进程故障由CMA自动拉起,拉不起的话会主备切换(优先选择高优先级AZ的GTM备机升主)。备机故障不影响主机业务。只要有一个GTM主就不影响业务。
CMServer:进程故障由CMA自动拉起,拉不起的话会主备切换(CM备发现CM主心跳超时CM备仲裁新主,优先选择节点号较小的CMS)。只要有一个CMS主就不影响业务。
ETCD:进程故障由CMA自动拉起。ETCD采用raft分布式一致性算法,如果主节点(leader)故障,备节点(follower)发起投票,获得多数投票的(candidate)升主。故障节点恢复之后成为(follower)。在2AZ部署时(每个AZ部署同样个数ETCD),需要额外一个仲裁AZ(部署奇数个ETCD),确保有一个AZ故障时,ETCD可以多数派选主。ETCD主要作用有两个:
(1)利用共识算法来存储集群状态信息
(2)用于CMServer主备状态判断(故障时先写入ETCD的升主)。PS:DN主备仲裁主体由CMServer完成,会依赖ETCD中保存的数据(如term值)。
5.3.2故障恢复依赖路径
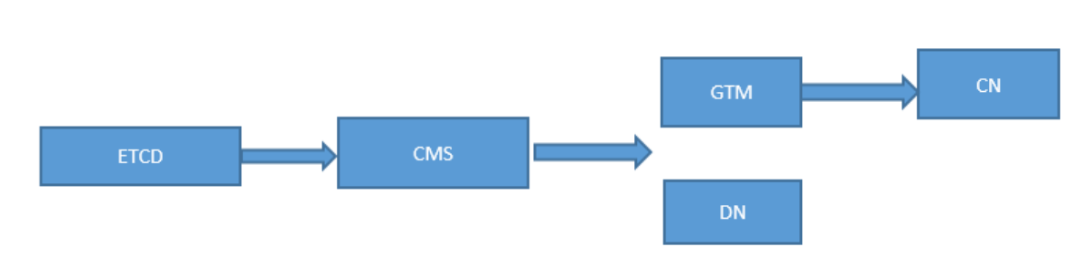
CMA,第一优先级修复,此组件每个物理节点都会部署,无主备属性,有om_monitor负责监控,一旦发现进程退出就会定时拉起。
CMS,第二优先级修复,此组件有主备属性,依赖ETCD组件的分布式一致性特性进行自选主
DN,GTM,CN,第三优先级修复,依赖CMS仲裁判断dn/gtm的lsn备机落盘日志量,来决定哪个备进行升主。cn无主备属性,依赖CMA组件进行拉起,但是一旦cn故障拉起失败,则由CMS负责仲裁进行故障隔离。
5.3.3各组件故障处理的优先级
5.4集群状态的检测(cm_ctl query -Cv查询原理)
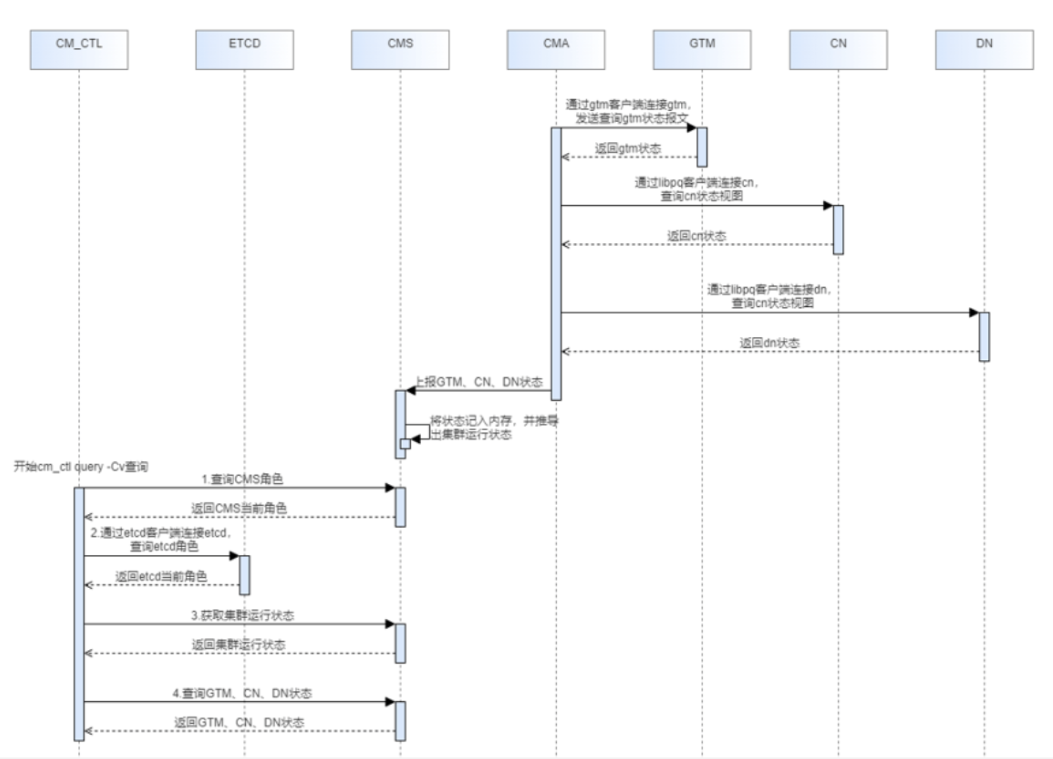
1.CMServer State
cm_ctl直接连接所有cm_server,cm_server返回自身角色。
2.ETCD State
cm_ctl通过etcd客户端,连接所有etcd,调用etcd客户端角色查询接口,获取etcd角色.
3.Coordinator State
每个包含cn节点的cm_agent定时查询本节点的cn状态(通过客户端连接cn,查询状态视图)
上报给cm_server主,cm_server存在内存中。cm_ctl连接cm_server主,获取cm_server内存值,
得到所有cn的状态。
4.Central Coordinator State
cm_ctl连接cm_server主,获取cm_server内存值中,包含ccn的信息,cm_ctl单独再将ccn的信息打印。
5.GTM State
每个包含gtm节点的cm_agent定时查询本节点的gtm状态(通过客户端连接gtm,获取含有gtm状态的报文)
上报给cm_server主,cm_server存在内存中。cm_ctl连接cm_server主,获取cm_server内存值,
得到所有gtm的状态。
6.Datanode State
每个包含dn节点的cm_agent定时查询本节点的dn状态(通过客户端连接dn,查询状态视图)
上报给cm_server主,cm_server存在内存中。cm_ctl连接cm_server主,获取cm_server内存值,得到所有dn的状态。
cm_ctl发送cm_ctl query-Cv给CMServer,CMS主线程接收到cm_ctl发送的查询消息,从CMS的上报状态结构体中拿取状态,返回给cm_ctl,cm_ct接收到消息并打印得到的集群状态信息。
CMA的主线程会循环查询各个实例的状态信息,每隔1s钟向CMS上报一次,发送上报消息CMS状态监测线程获取到CMA上报的消息,将集群状态存入上报状态结构体中。
如下图所示:
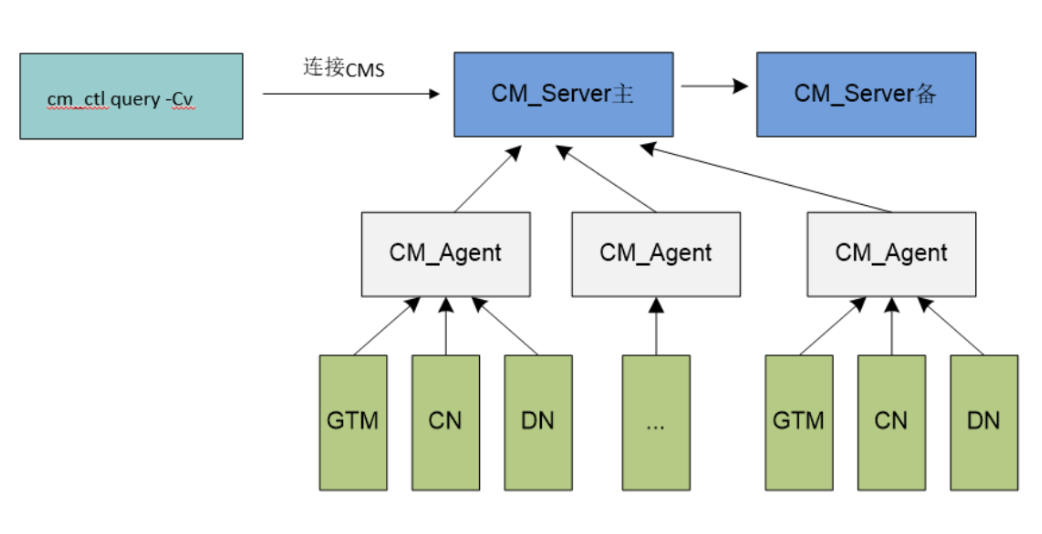
CM Agent为每个集群实例创建单独的线程,负责实例的状态监测和执行相应的实例操作;
CM Agent每隔1秒执行一次实例的状态监测操作,该时间间隔可以通过CM Agent的配置文件进行调整;
由于实例状态监测以及其他的实例操作需要耗费一定的时间,所以实际的实例状态更新时间间隔大于1秒;
六、集群高可用和故障恢复
6.1集群故障处理原理
实例故障
Monitor宕掉:借助操作系统定时任务进行检测
CMA宕掉、ETCD宕掉:由Monitor进行检测
CN/DN/GTM/CMS进程宕掉:CMA检测
IP冲突:CMA执行检测命令
磁盘故障检测:CMA定期往数据目录写文件
磁盘满检测:CMA定期往数据目录写文件
网卡故障检测:CMA查询网卡状态
Hang检测:CMA尝试多次连接实例
节点故障(下电、停止节点)
CMA定时心跳上报
AZ故障
AZ网络检测:CMS根据连接其他AZ的CMS节点判断是否AZ网络故障
AZ故障检测:CMS根据CMA上报的AZ内的各实例状态判断是否AZ实例故障
实例组件发生故障的处理方式
无状态的实例故障
Monitor故障,借助操作系统定时任务进行检测恢复。
Agent故障,由Monitor进行检测和拉起。
CN故障,由Agent拉起,如果拉不起来,进入自动剔除和加回逻辑。
有状态的备实例故障
DN备故障,由Agent拉起,如果拉不起来,非同步备不影响DN主业务。
GTM备故障,由Agent拉起,如果拉不起来,不影响GTM主业务。GTM主备之间不存在数据备份,只定时通信
GTM保存的全局id等信息全部备份在ETCD中。
CMS备故障,由Agent拉起,如果拉不起来,不影响CMS主业务。
ETCD备故障,由Monitor拉起,如果拉不起来,但不造成少数派,不影响ETCD主业务。
有状态的主实例故障
DN主故障,由Agent拉起,如果拉不起来,CMS仲裁DN备升主。
GTM主故障,由Agent拉起,如果拉不起来,CM仲裁GTM备升主。
CMS主故障,CM备发现CM主心跳超时,CMS备仲裁新主。
ETCD主故障,ETCD集群自仲裁选主,完成倒换。
·节点故障恢复,参见实例故障恢复
AZ故障恢复
3AZ容忍一个AZ故障,自动切换到另一个AZ
AZ1和AZ2网络断开,但AZ3连接AZ1和AZ2正常,stopAZ2
6.2CN节点故障和处理原理
6.2.1CN剔除和恢复流程
CMA创建实例检测线程,获取CN实例的状态信息;
如果CN实例信息获取失败,会检测CN实例的异常原因,并设置相应的HA异常状态:
CN实例的状态异常原因是由实例启停线程轮询监测并提供的;
CN监测流程如下图所示:
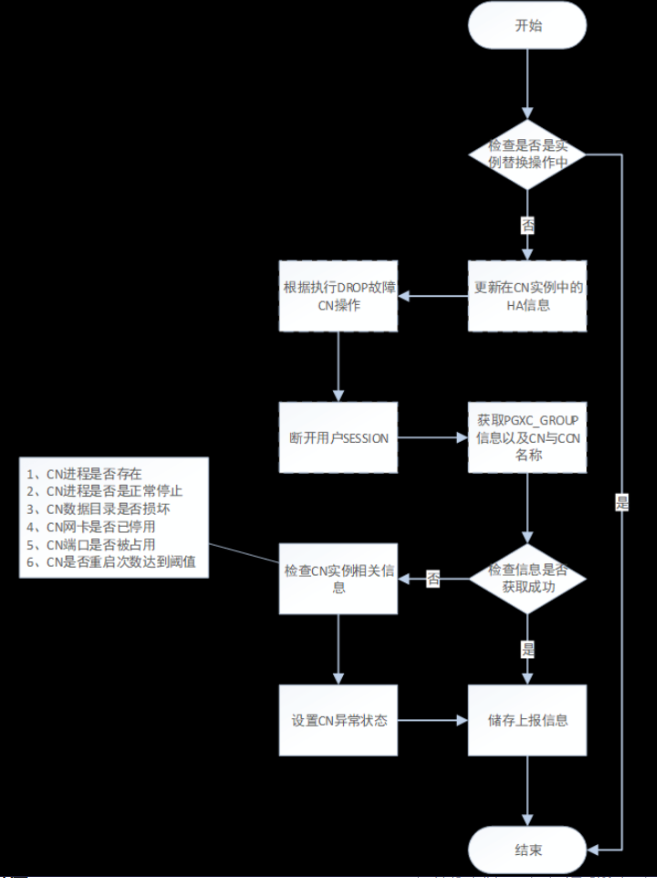
6.2.2CN剔除和恢复流程
GaussDB 集群中多个CN之间是并列关系,非主备关系,当某个CN故障后,CN不会主备切换,而是需要把故障的CN从集群中隔离掉,由剩余CN继续完成任务处理。
在 GaussDB 集群中,DDL 操作会强同步到所有 CN 实例。如果 CN 实例故障,DDL 操作将因为与故障 CN 实例之间的强同步受到阻塞而失败。此时,需要CM(集群管理)把故障的CN实例从集群中剔除掉,避免强同步的阻塞,从而使得 DDL操作能够成功被执行。如果CN 实例的故障被解除,还需要把它恢复进集群,避免正常 CN 减少后的性能损失。
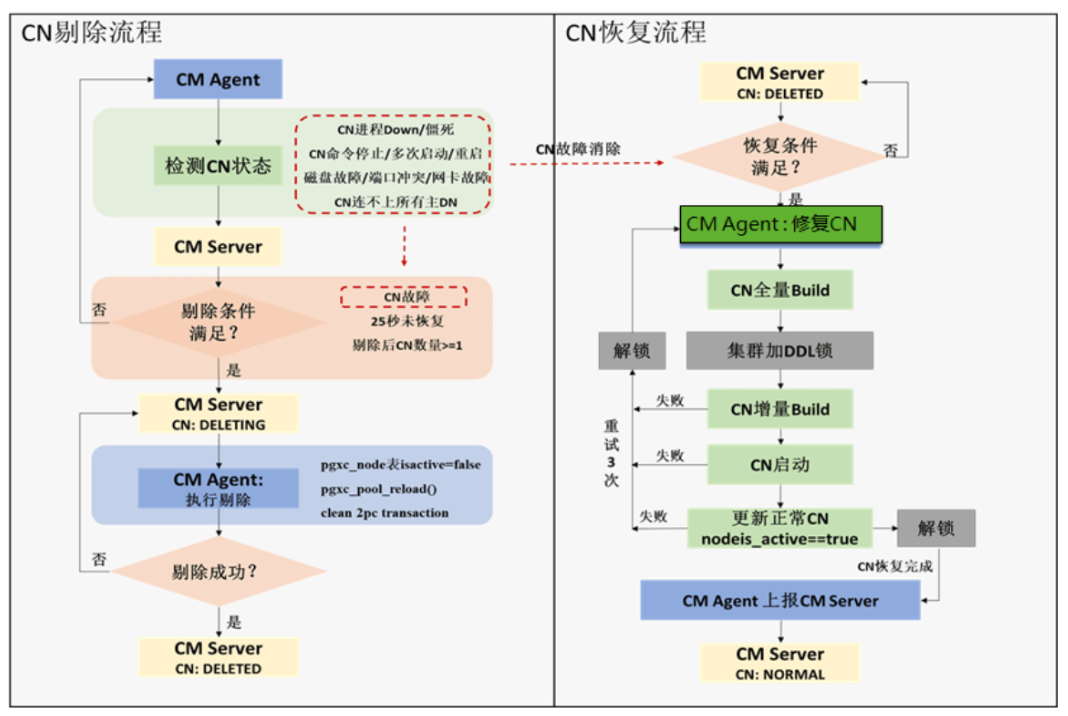
1.CN没有主备之分,当CN故障时,会立即拉起来,业务迁移到正常的CN节点上,异常CN超过25s一直没有恢复的话,则此CN无法提供服务,会进入CN的剔除流程。
2.CN自动剔除的过程,
故障CN状态持续被CM Agent上报给CM Server主实例,CN故障时间已经超过CN剔除时间:
CM Server主下发故障CN剔除命令给CCN所在的CM Agent,CM Agent执行故障CN剔除操作(CCN节点是负责集群内的资源全局负载控制,以实现自适应的动态负载管理。CM在第一次集群启动时,通过集群部署形式,选择编号最小的Coordinator作为CCN。若CCN故障之后由CM选择新的CCN进行替换)。
CCN节点介绍
Control Coordinator Node,GaussDB动态负载管理中心控制点。负责进行各CN中复杂作业是否可以执行的中心判断、排队和调度,以实现动态负载管理。CCN所在节点的CM Agent实例上报CCN状态时,附带故障CN剔除的操作结果;
CM Server主将CN剔除结果写入动态配置文件
3.CN恢复流程
恢复流程是反向的,满足条件就去修复,CN会去全量重建,CN是轻量级的数据,存储元数据信息,加DDL锁,可以读数据,没法写,轻量化的锁,不感知,可以写,做增量build,恢复完成后去解锁,CMA告诉CMS已经正常,把CN值置为normal。
注意:CN置为DELETED之后,若开启了自动恢复参数(enable_cn_auto_repair=on,自动加回也是调用的gs_replace工具)则会自动加回(自动加回这个可能会影响业务,加回的过程中,业务DDL可能有一段时间是阻塞的)。手动加回可采用gs_replace命令
6.2.3CN实例仲裁和故障切换
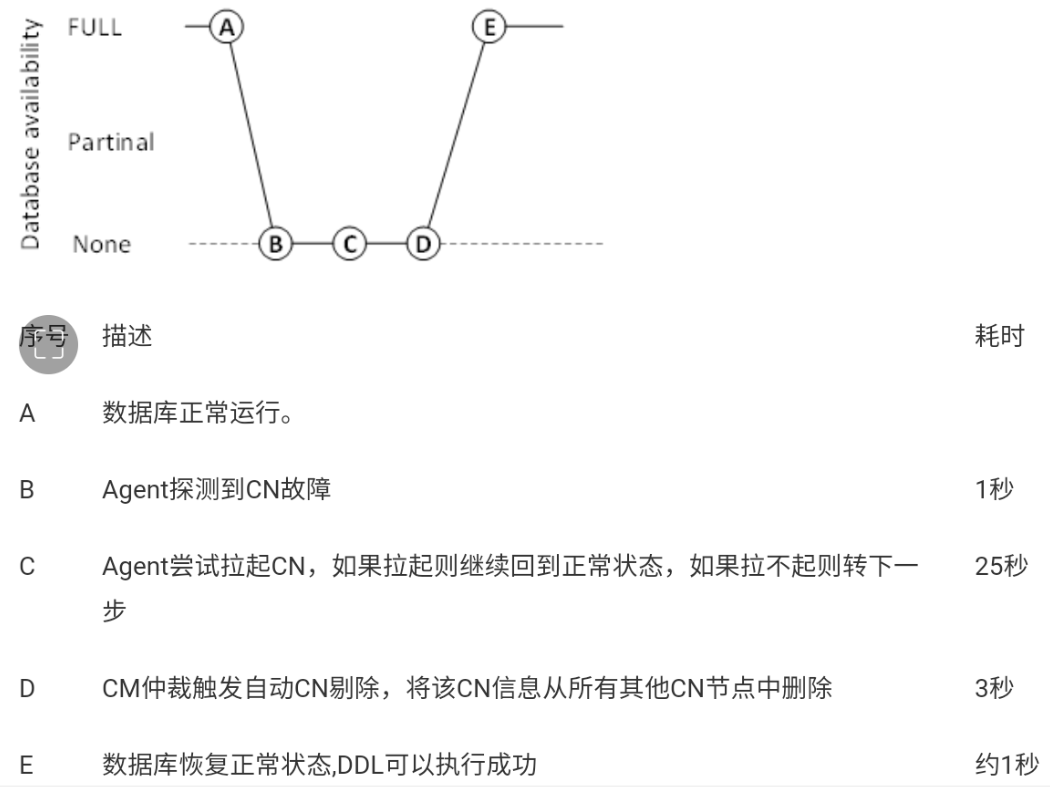
CN剔除步骤:
1、CM检测到CN连续故障时长超过25S,CMS会发起CN剔除的操作,CN处于 Deleting过程中;
2、CM更新其它CN节点的pgxc_node系统表;
3、将CN隔离状态保存到分布式存储组件(ETCD);
4、数据库状态恢复,CN可以执行DDL成功。
6.2.4 CN故障处理
CN组件异常,根据不同的状态,处理方式不同。
首先,需要登录故障CN节点查询集群状态,根据不同的状态分别处理
1.CN组件状态normal:
6.3DN节点故障和处理原理
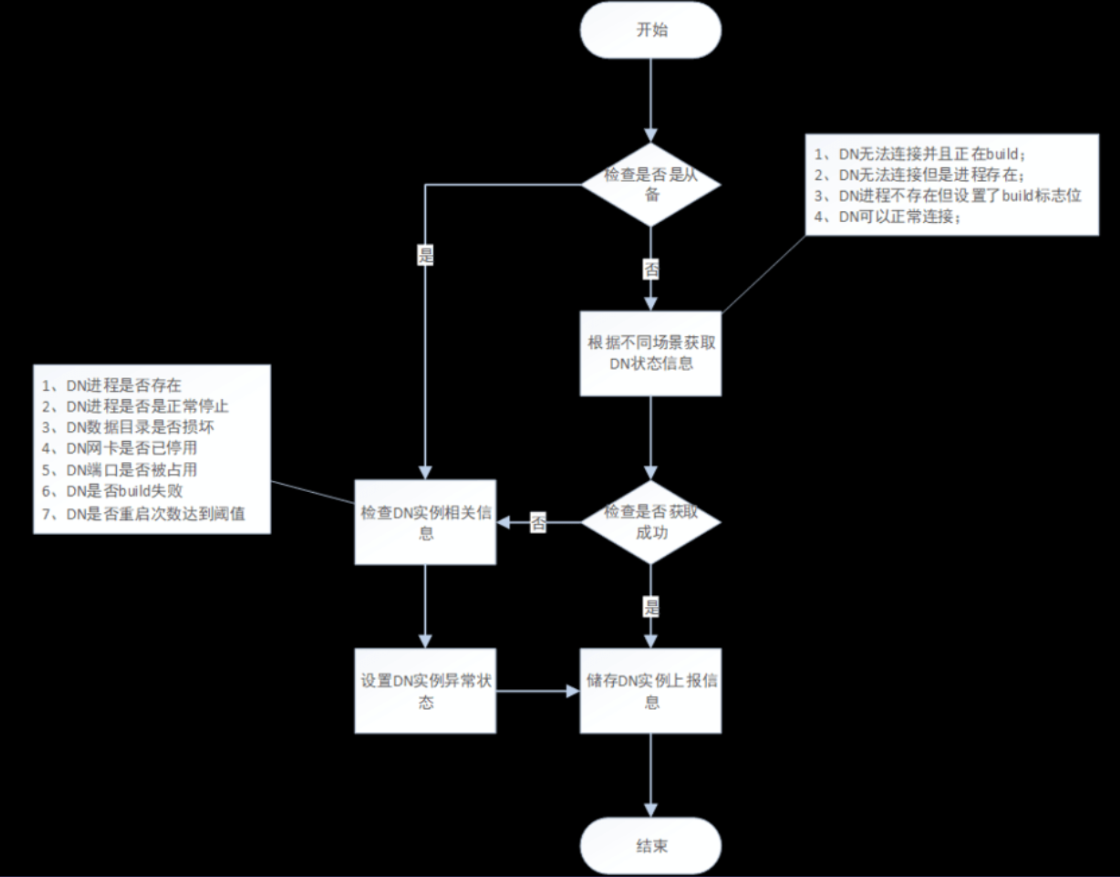
6.3.1DN实例状态监测
DN实例状态监测只关注主备实例的详细状态,从备实例只检查基础的运行状态;
从备实例连续三次运行正常,第四次将不再检测其他状态,除非发现从备实例已停止运行;
DN实例的状态异常原因是由实例启停线程轮询监测并提供的;
DN监测流程如下图所示:
6.3.2DN故障处理
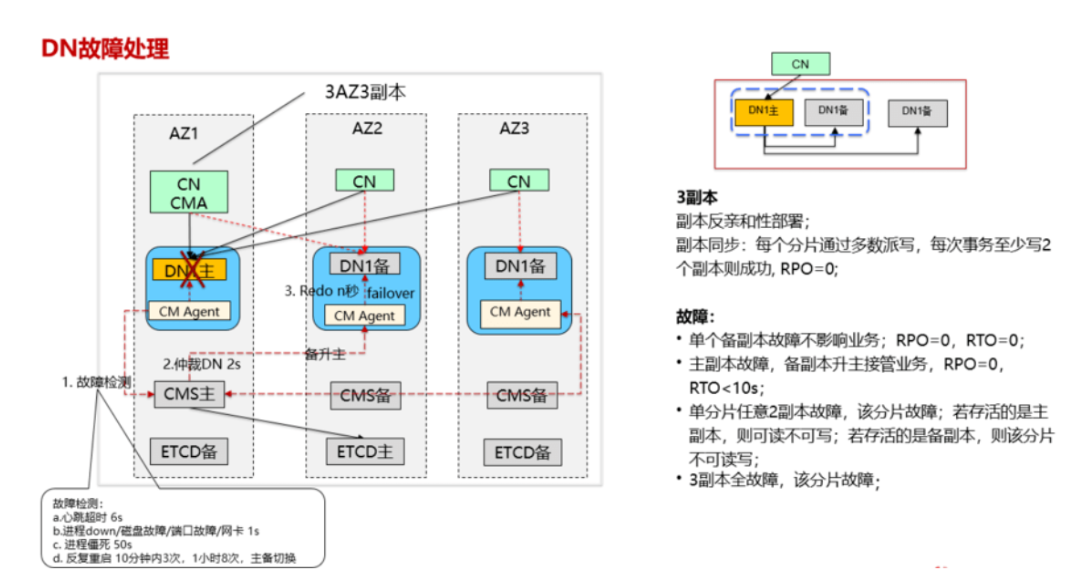
DN故障,若为一主多备场景:
1)主DN故障:主DN故障,则立即拉起来为pending,然后由CMS仲裁为主机;如果主DN一直拉不起来,则CMServe仲裁让DN备机failover为主机(业务中断,failover后业务可以正常运行)
2)备DN故障:备DN故障,则立即拉起来为pending,然后有CMS仲裁为备机;如果备DN一直拉不起来,不影响主机业务(单数派故障,备故障不影响业务)故障检测,CMS去仲裁,2s之内,仲裁出现问题,DN1剔除,把所有wal日志redo,DN1备追到一个最新的状态,做failover,
以后所有请求往新主去写。
6.3.3DN主实例故障仲裁和切换

CM Agent对每个DN启动线程,定期监测DN进程的运行状态、磁盘状态、端口使用状态,并从DN获取当前主备角色、日志信息、同步状态等,上报给CM Server。
在DN 故障时,CM Server根据收到的DN状态信息,仲裁DN备升主,并将升主指令下发给CMAgent,由Agent通知DN备执行升主动作,主备切换动作完成,Agent定时任务会上报新的状态给CM Server。
DN仲裁选主过程:
1、DN主实例故障;
2、CMS检测到无主,即开始给正常节点发送lock1命令尝试锁住备机。
3、6s内原主启动完毕则将原主failover,原主状态没有恢复,CMS开启发起选择新DN主:
4、从锁住的多数派副本中,选择最大的term/Lsn副本(select term,Isn frompg_last_xlog_replay_location();)),并通知升主;
5、CMS发起lock2命令给备机,让备机连接到新主
6、CMS发起unlock解锁。
term是一个连续递增的整数,它代表了领导者选举的一个特定实例。每当开始新的选举过程时,term就会递增。
Term值的更新:在DN仲裁流程中,使用内存中的term值(CMS升主时从etcd中获取)加1,当累加到10的倍数时,设置内存中的term值到etcd中。在CMS升主时,从etcd中获取一次term值保存到内存,然后加10后(加10是为了防止CMS主备切换,etcd中的term值不是最新的),重新设置到etcd中。
6.3.4多AZ场景下,DN故障的处理原则
DN多副本主要采用Quorum协议跨AZ复制日志进行数据同步。
DN故障处理的原则是:
DN主故障,依次优先选择用户初始指定、数据最新、原主同AZ备、AZ优先级最大的DN备升主。主恢复,不自动回切,可以人工回切;其角色降备。如果原主的日志能够追上新主,则进行日志追赶,如果追不上,则在原主上进行数据全量重建。
DN备故障,不切换。备恢复,恢复原先主备模式。
基于上述原则,能够处理DN单点故障和多点故障。DN故障包括自身故障和DN HA间的故障具体有进程挂掉、网络隔离或时延、所在磁盘空间满、网络丢包;网络轻微抖动,不会进行主备切换,例如不少于3秒的正常网络传输后有少于1秒的网络中断。
6.3.5DN故障处理
参考运维宝典
6.4CMS故障原理和处理
6.4.1CMS故障处理
cm_server负责整个集群中实例的仲裁及命令的下发,相当于集群的大脑。当实例出现故障时,cm_server会仲裁实例以试图使得集群恢复可用状态,但当cm_server自身面临故障时,并没有一个更上层的组件来进行仲裁处理,cm_server依靠的是自身的自仲裁机制尽力保证集群的可用性。
CMS主故障:通过ETCD进行仲裁选主;正常选主期间不影响集群提供读写业务;(CMS选主时间10s,包括6s的心跳超时,ETCD仲裁,CMA去下发命令,以及同步的时间)
cms备机故障:cma会尝试拉起cms进程,集群Noraml,不影响业务。
还有一点,CMS虽然是大脑,但是也受CMA的监控,CMA每秒会去检测CMS有没有正常的回应,当CMA发现CMS超过6s没有回应,会报超时,这个时候会告诉ETCD,ETCD这边会代替CMS去进行仲裁,升CMS主(优先选择节点号较小的CMS),升主以后,这一段时间内,整个集群都在正常跑业务。
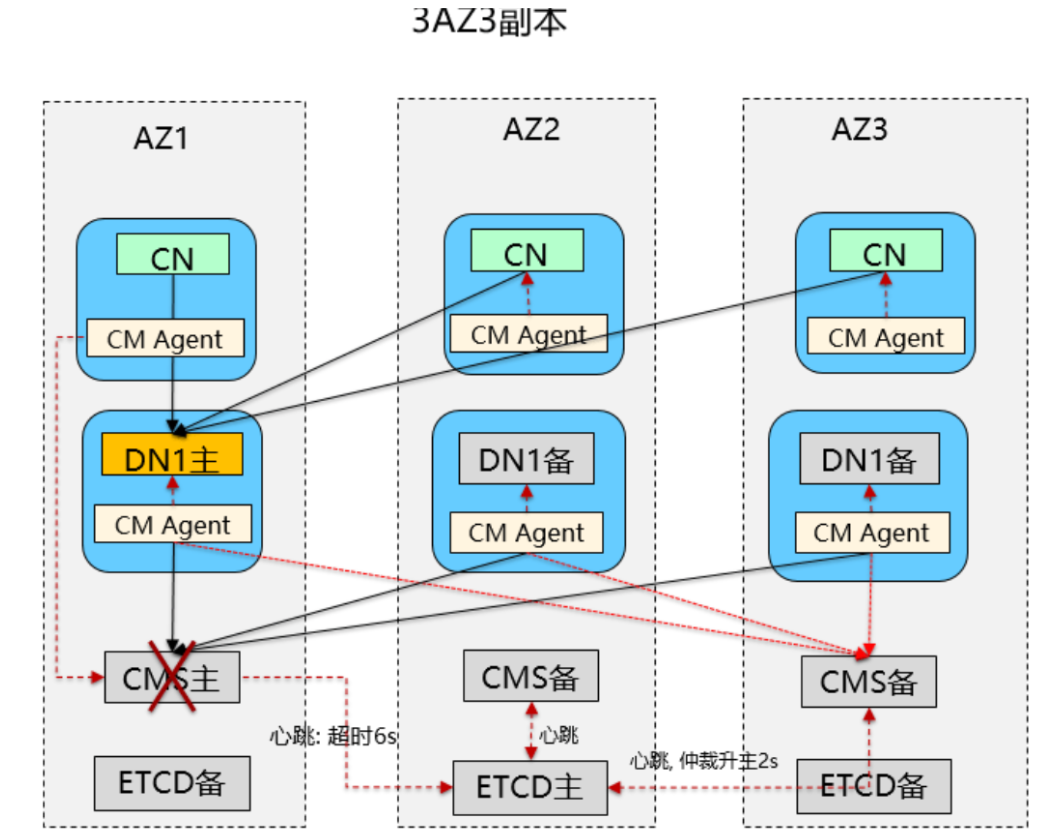
CMS主故障,通过ETCD仲裁选主;正常选主期间不影响集群提供读写业务;(CMS选主时间 10s)
CMS备故障,不影响CMS服务,不影响数据库集群提供读写服务:
CMS全故障,集群节点的监控进程CMA无法正常连接CMS主,有两种可选处理方式2.
(1)CMA杀掉本节点上的实例,不再提供读写服务。
(2)CMA不对本节点实例进行干预,当前集群可提供读写服务;默认处理方式是(2)。
6.4.2CMS仲裁和故障切换

CMS仲裁选主过程:
1、CMS主节点异常:
2、尝试拉起CMS进程,并触发选主过程;
3、CMS依赖的组件选主成功,etcd模式下,etcd先选主,CMS执行选主流程;dcc模式下,dcc先选主,CMS跟随选主;
4、CMS选主成功。
6.4.3CMS自仲裁流程
在主备从集群中有两个CMS,一个为主、一个为备,两个CMS之间会维持心跳。CMS的自仲裁逻辑可以概括为给对端CMS发送信息和处理对端CMS发送过来的信息。CMS的自仲裁由个常驻线程(HA线程)完成,根据节点号大小的不同,两个CMS的运行逻辑存在不同。下面分别进行介绍。
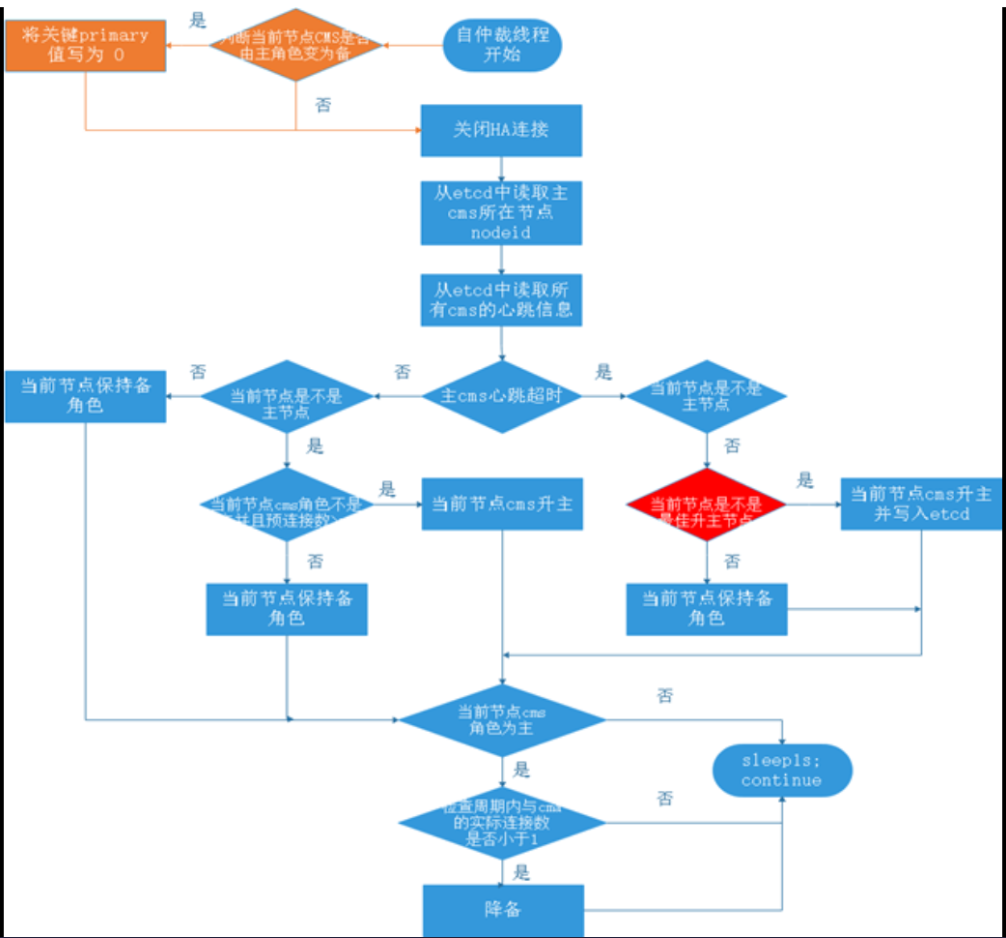
1、自仲裁线程开始,判断集群已部署etcd,并且etcd健康。关闭CMS之间的HA连接,依赖etcd中存储的信息进行自仲裁;
2、从etcd中获取主cms所在节点的nodeid;
3、从etcd中获取集群中所有cms的心跳信息:
4、判断原主cms是否心跳超时,如果心跳超时
a)判断当前节点是不是主cms所在节点,如果是,原主cms降备;
b)如果当前节点不是主cms所在节点,判断当前节点是不是最佳升主节点,如果是,本节点的cms升主,并写入etcd。
5、如果主cms心跳并未超时,并且当前节点是主cms所在节点
a)判断当前节点cms和cma的预连接数,如果当前节点cms和cma的预连接数大于等于1,保持主角色。
上述选主过程完成后,如果本节点cms成功选主。检查周期内,cms和cma的实际连接数如果大于等于1,保持主角色,否则,降备。sleep1s,继续下一轮循环。
心跳超时处理流程
CMS会维持一个心跳计数,每秒钟增加,而当CMS接收到对端CMS的消息时,会将心跳次数重置为0,因此如果长时间没有接收到对端CMS的心跳,表明两个CMS连接出现异常,当心跳超时(即心跳计数超过阈值)时会进入附加的心跳超时处理环节。
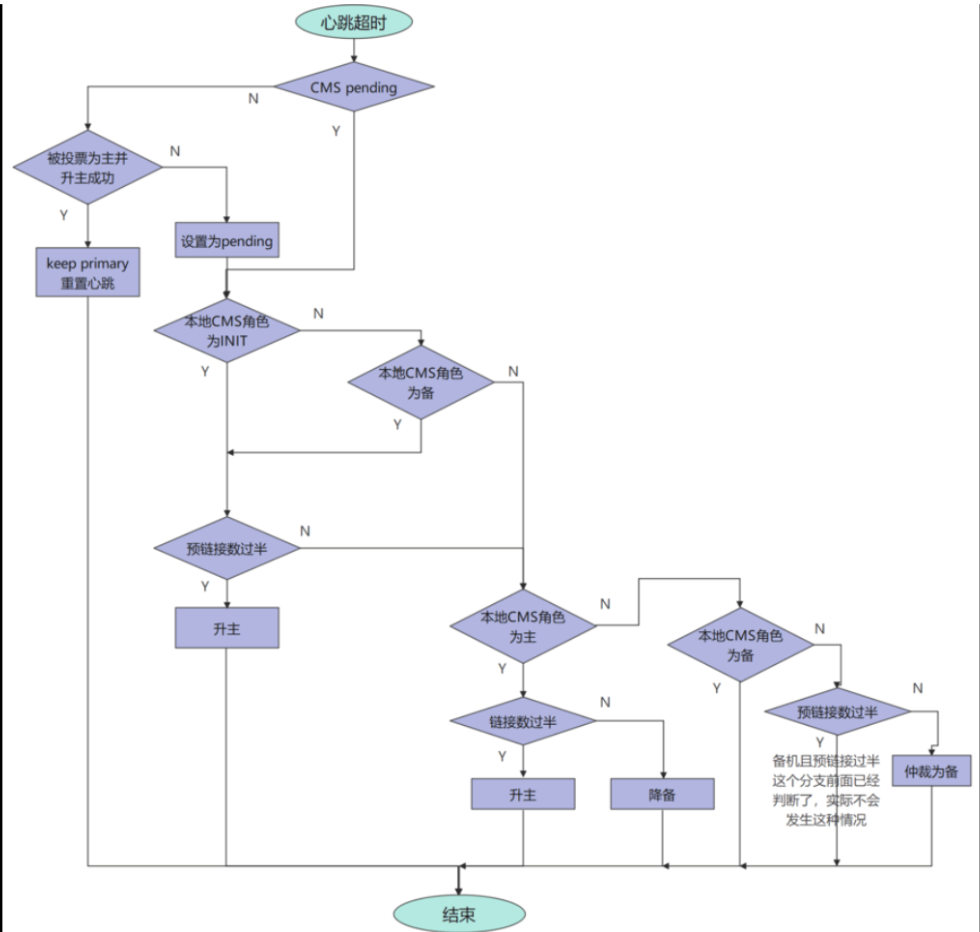
6.4.4多AZ场景下,CMS故障的处理原则
1.CM主故障,依次优先选择节点号最小的CM备升主。主恢复,不自动回切,角色降备。
2.CM备故障,不切换。备恢复,恢复原先主备式。
3.基于上述原则,能够处理CM单点故障和多点故障。
ETCD故障由ETCD集群自己处理。少数ETCD故障,不影响ETCD的高可靠和高可用;多数ETCD故障,ETCD集群不可用,CM无主,整个集群不可用。
6.4.5CMS故障处理
运维宝典
6.5ETCD故障
6.5.1ETCD故障处理原理
ETCD是一种开源分布式键值库,用于共享配置和服务发现,负责保存集群的拓扑信息。主要提供存储以及获取数据的接口,它通过协议保证 Etcd 集群中的多个节点数据的强一致性。用于存储元信息以及共享配置。提供监听机制,客户端可以监听某个key或者某些key的变更。用于监听和推送变更。提供key的过期以及续约机制,客户端通过定时刷新来实现续约。用于集群监控以及服务注册发现。提供原子的CAS(Compare-and-Swap)和CAD(Compare-andDelete)支持。用于分布式锁以及leader选举。
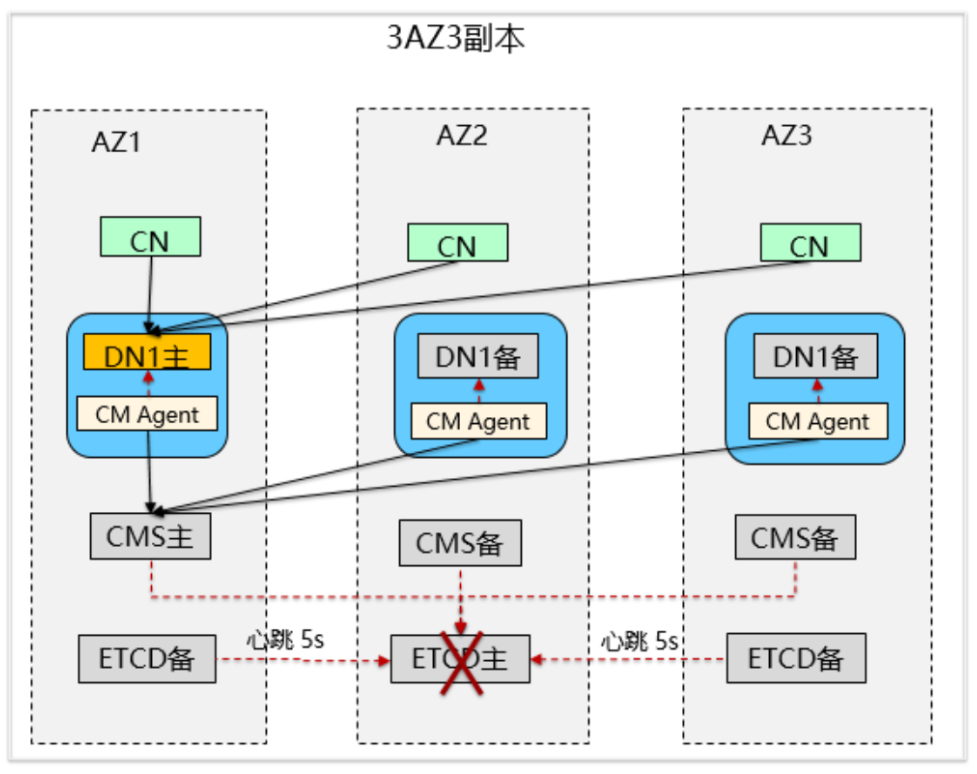
ETCD作用
1.全局事务ID、Sequence依赖ETCD存储:
2.CMS自身仲裁和CMS对其他数据库组件的仲裁依赖ETCD;
3.存储各组件的主备信息
ETCD故障
·ETCD少数派故障,若主ETCD故障,重新选主(10s);
·ETCD全故障或故障半数以上,主CMS降为备,全局无主CMS,等价于CMS全故障:
ETCD的修复
·少数派故障,可自动修复;
多数派故障,手动修复;
ETCD自选主,基于Raft分布式一致性算法,此算法可确保集群中所有节点之间的数据存储致性-这就是具有容错能力的分布式系统的目标。
ETCD如果主节点(leader)故障,备节点(follower)发起投票,获得多数投票的(candidate)升主。然后通知CMS主已经进行升主操作,后面CMS主和gtm有什么需要同步的 都会去找新的ETCD主进行同步。
故障节点恢复之后成为(follower)。在2AZ部署时(每个AZ部署同样个数ETCD),需要额外一个仲裁AZ(部署奇数个ETCD),确保有一个AZ故障时,ETCD可以多数派选主。ETCD主要作用有两个:(1)利用共识算法来存储集群状态信息(2)用于CMServer主备状态判断(故障时先写入ETCD的升主)。PS:DN主备仲裁由CMServer完成,不依赖ETCD。
ETCD故障,和CMS故障是一样的,如果所有ETCD都故障,会导致CMS之间无法通信,CMS之间通信是通过ETCD去插入数据来维持心跳的,所有ETCD都故障了,CMS也故障了,上层CN DN没发生故障,这是可以正常使用的。但是如果这时候DN发生故障了,就会影响业务
6.5.2ETCD故障处理
6.5.2.1 ETCD故障定位
1、首先确认是否为底层物理机故障
问题分析
如在告警信息中找到实例ID、节点ID、虚拟机ID,在管控面查看虚拟机状态是否正常,能否正常登录,查看虚拟机是否重启
处理方法
需HCS底座支持联合排查问题原因
2、网络断开导致ETCD异常
虚拟机无法登录或ping不通其他节点IP 或者监控显示网络有异常问题分析
在该节点上ping其他节点IP,测试是否ping通。如果ping不通,执行如下步骤,检查该节点网络、IP配置、防火墙配置等。
(1)ifconfig查看etcd使用ip是否存在
(2)检查防火墙是否开启,psuxlgrep etcd查看etcd的ip和端口,在root用户下iptables -L命令检查防火墙是否限制了IP和端口,如果有限制,去掉防火墙限制。如果ping通,执行如下步骤确认告警时间点网络是否断开
(1)查看ETCD日志,cd $GAUSSLOG/cm/etcd
查看对应时间点的etcd_xxx.log日志,如果有如下日志,可能是etcd节点间网络断开,或者对端的etcd进程down,导致本端etcd连接断开
1)transport is closing
2)lost the TCP streaming connection
3)could not connect: xxxx timeout("ROUND_TRIPPER_RAFT_MESSAGE")处理方法
需HCS底座支持联合排查问题原因
3、cpu或者磁盘I0过高导致ETCD异常
问题分析
DBS运维管理平台查看实例监控中CPU、10、内存使用率是否较高(可能存在相关告警)查看ETCD日志,cd SGAUSSLOG/cm/etcd,若存在如下报错则说明ETCD节点负载过高
1)server is likely overloaded
2)took too long to execute
3)lo util 100
处理方法
负载下降后异常会自行恢复
若仍存在异常需分析负载较高原因,先处理负载高问题
4、ETCD进程DOWN
问题分析
登陆故障etcd节点,执行命令psuxIgrep etcd,查看etcd进程是否正在运行处理方法
如果进程不在,查看etcd无法启动原因:
(1)cd $GAUSSLOG/bin,查看目录下是否有cluster_manual_start和 etcd_manual_start 两个文件,如果有表示集群被停止,确认停止集群的原因,之后启动集群即可(cm_ctlstart)
(2)cd SGAUSSHOME/bin 查看目录下是否存在etcd这个文件,文件权限是否正确,正确是700,确认文件不存在或权限不正确的原因。
(3)检查etcd的数据目录所在磁盘是否满了或者故障,通过cm_ctlquery-Cvipd查看etcd目录,若磁盘空间满需进行清理。
6.5.2.2集群内某个节点ETCD宕机
集群状态,DN节点状态均正常,某个节点ETCD出现宕机:
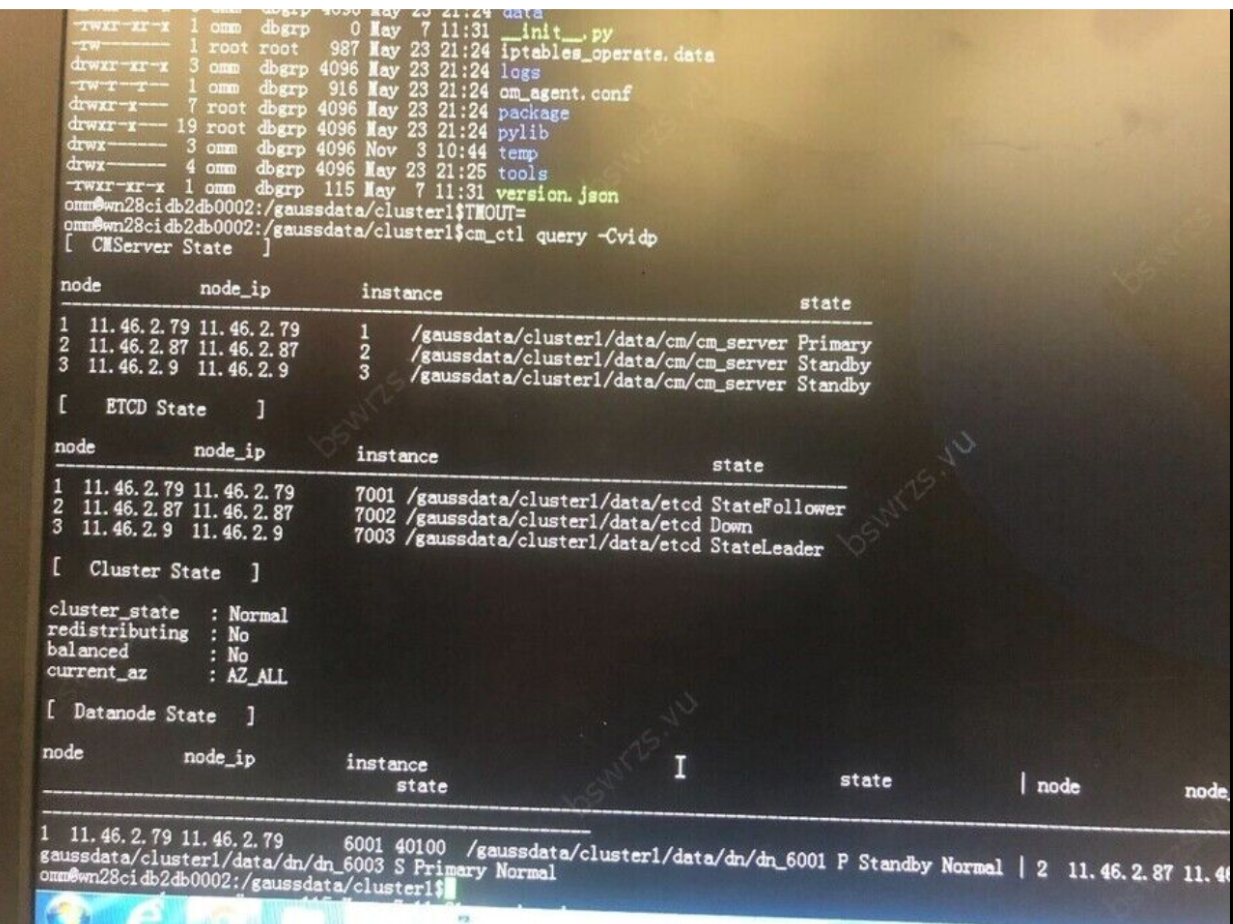
2、问题分析:
1、切换至数据库用户omm下
2、进入SGAUSSLOG/cm/cm_agent目录下,在cm_agent-xxxxxxxx-current.l0g日志中查找
etcd的相关报错:
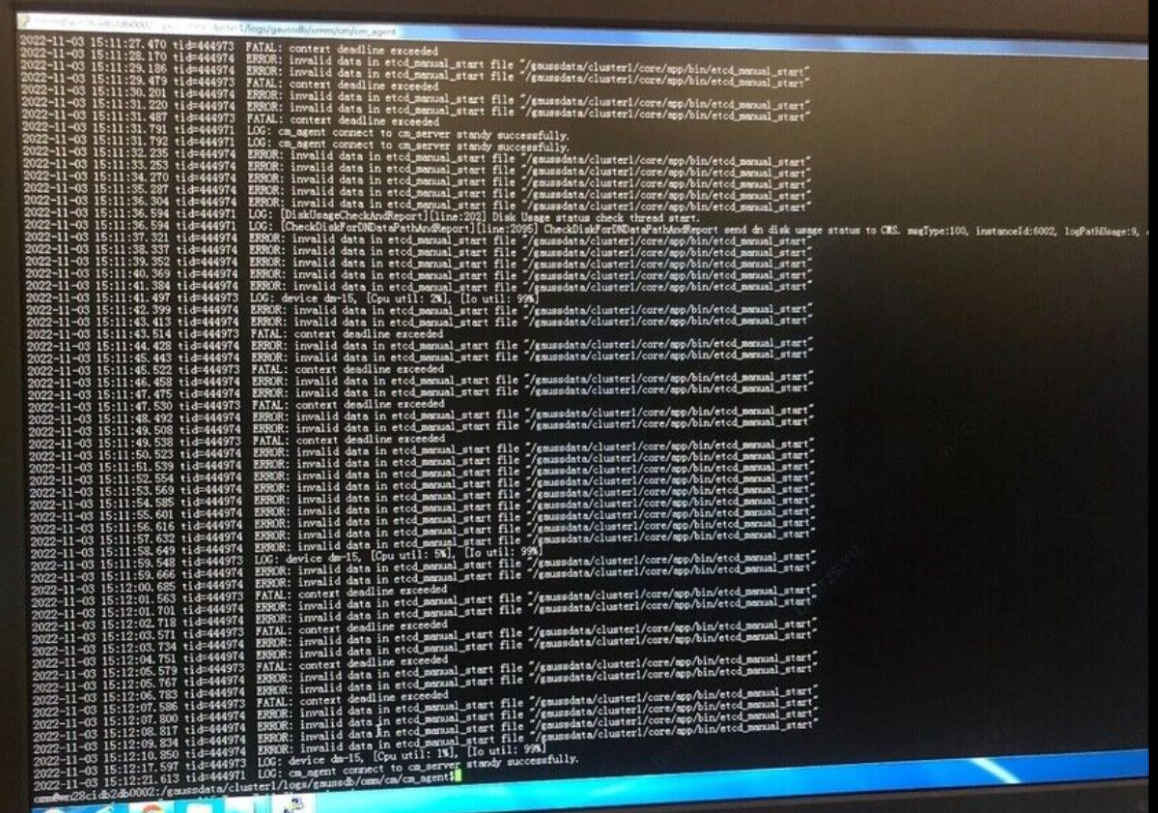
可以看出是由于/gaussdata/clusterl/core/app/bin路径下存在的etcd_manual_start文件引起的报错。
3、根据集群状态分析得出,由于近期集群发生过主备切换,而在切换的瞬间可能导致单个节点etcd状态异常,自动拉起失败,会在/gaussdata/clusterl/core/app/bin路径下生成etcd manual start文件。
4、因此需要手动删除/gaussdata/clusterl/core/app/bin路径下生成etcd_manual start文件则etcd即可自动拉起,恢复正常。
6.5.2.3ETCD少数派故障
一、故障注入:移除数据目录
1、进入到etcd数据目录
cd /opt/gaussdb/engine/etcd
2、移除数据文件
如下图,etcd 7001 down
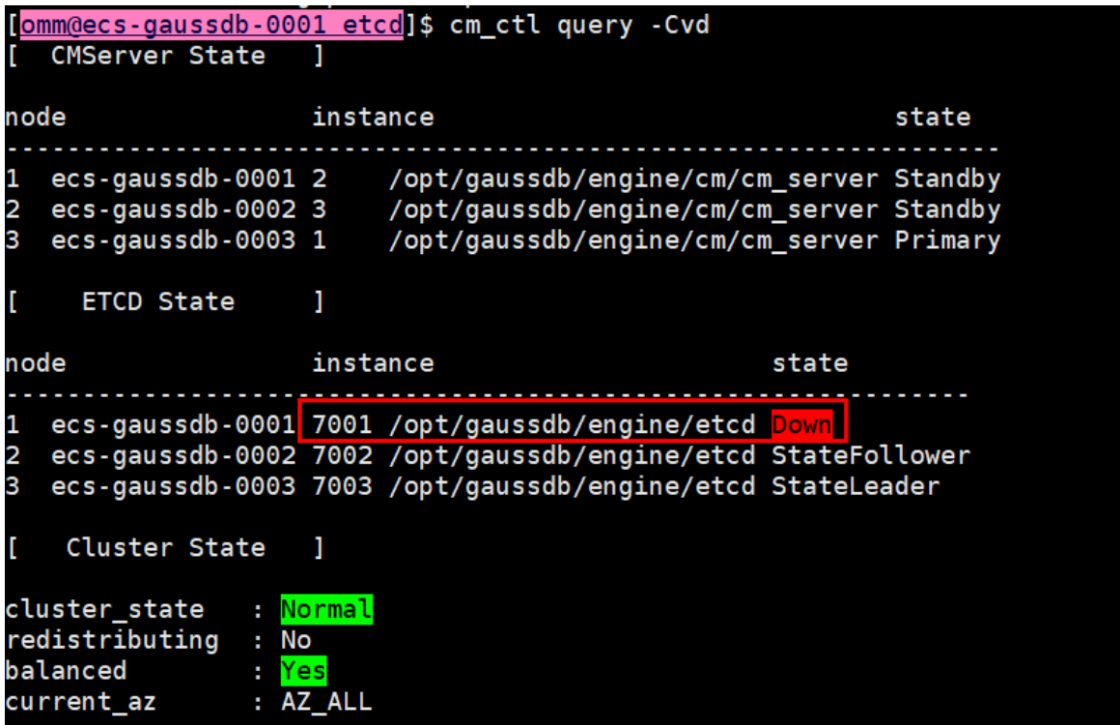
二、故障处理
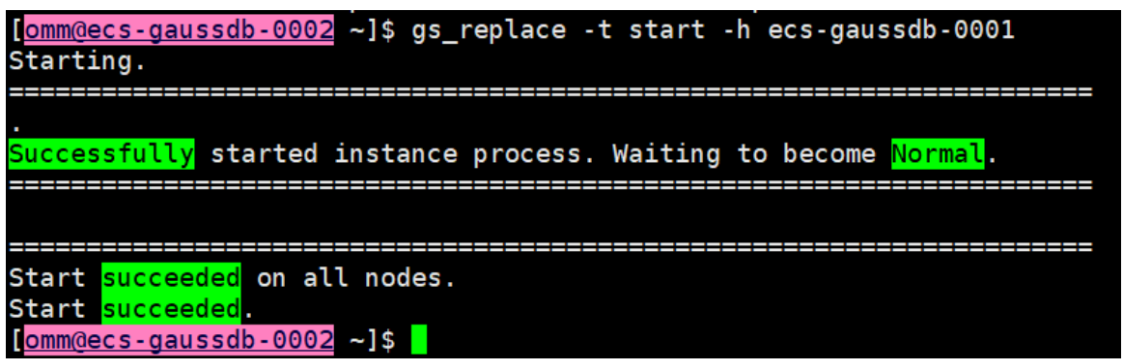
1、少数派etcd节点故障,因ETCD集群一致存在着大多数可用节点,不存在数据丢失、损坏可通过gs_replace工具进行修复;
2、在正常节点上修复
gs_replace -t config -h ecs-gaussdb-0001
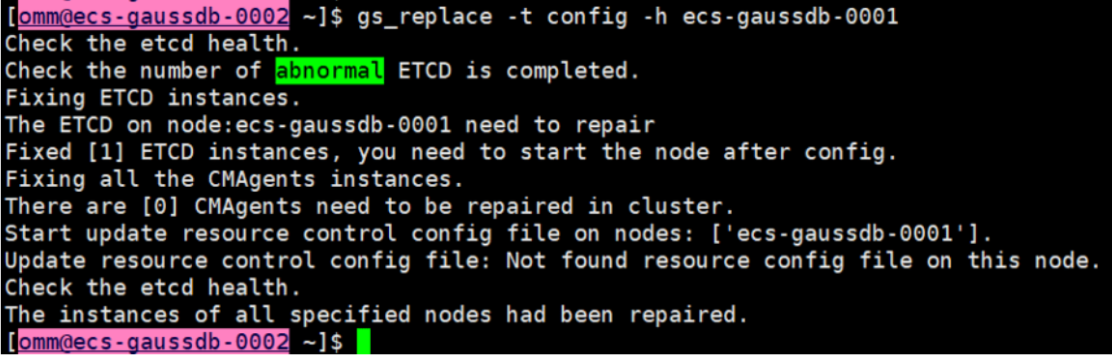
gs_replace -t start -h ecs-gaussdb-0001
6.6GTM故障
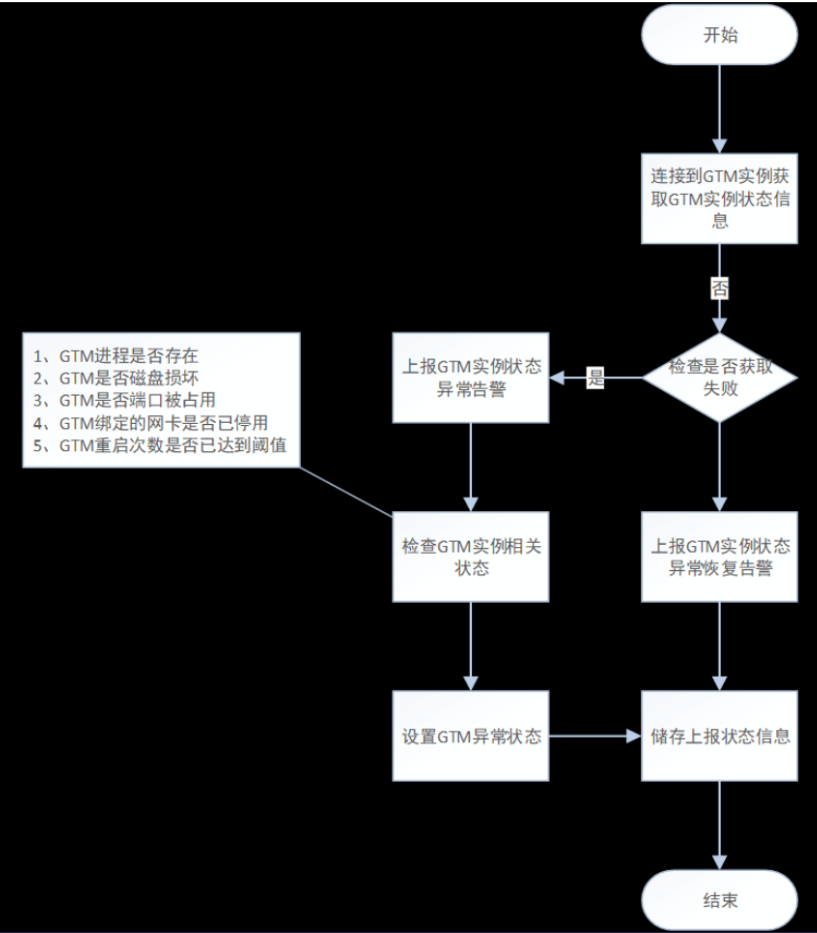
6.6.1GTM实例状态监测
CM Agent每隔1秒会连接本节点的GTM实例,获取GTM的状态信息并保存,由实例状态上报线程将GTM实例状态上报给CM Server。
CM Agent发现GTM实例状态异常时,会对GTM实例进行检查,并设置对应的连接状态。
GTM实例状态监测流程图如下图所示:
6.6.2GTM故障处理
GTM名为全局事务管理器,系统中只有一个,采用主备方式,主机故障后,备机可以接管服
务。
作为系统中常驻的服务进程,采用多线程架构。GTM主要负责分发xid与snapshot,由于xid要全局唯一,因此需要持久化到磁盘上,凡是需要持久化磁盘的都需要有备份,那么GTM主机在每将一次xid值写入到qtm.control文件中,就会和备机同步一次,备机写完后,主机再写。以此保证系统中全局事务的一致性。GTM是被动接受连接的,通常只有CN会主动连接GTM,DN在autovaccumwork时连接GTM。
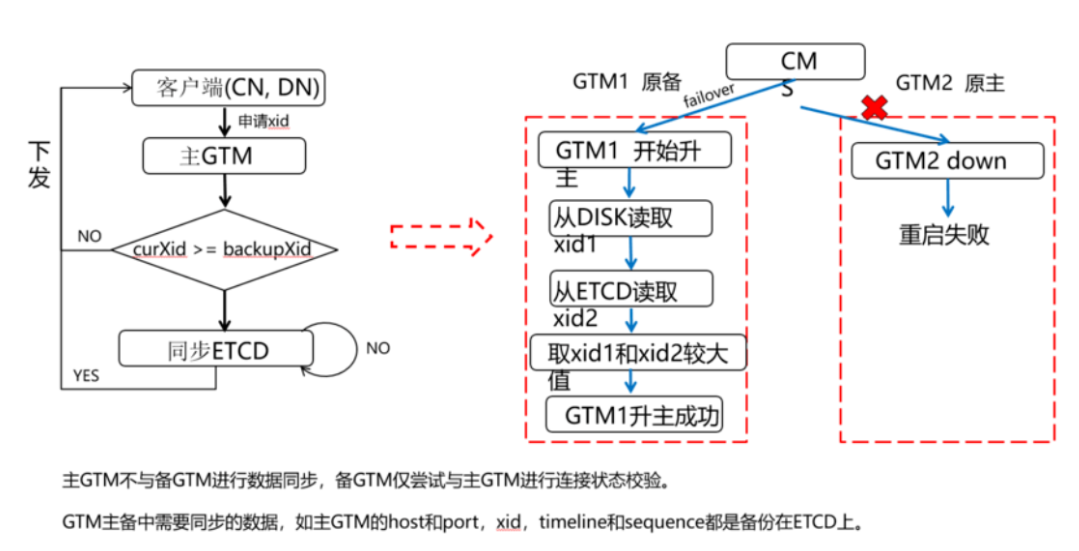
主GTM不与备GTM进行数据同步,备GTM仅尝试与主GTM进行连接状态校验。
GTM主备中需要同步的数据,如主GTM的host和port,xid,timeline和sequence都是备份在ETCD上。
GTM是负责生成和维护全局事务ID、事务快照、时间戳、sequence信息等全局唯一的信息。
整个集群只有一组GTM:主GTM一个,备GTM一个或多个。
GTM的主和备之间不进行数据同步,全局xid(事务ID),第一次申请完之后,会同步写到ETCD中。
主GTM故障情况:如果主GTM故障,则立即拉起来为pending,然后由CMServer仲裁为主机;如果主GTM一直拉不起来,则CMServer仲裁让GTM备机failover为主机,接管主GTM业务请求。GTM原备开始升主,会从DISK中读取一个xid1,再从ETCD中取到刚开始申请时的xid2,因为要拿到一个最大的全局事务ID,由于原主已经挂了,所以不知道最大的xid是多少,这个时候需要进行比较取一个较大值,然后升主成功。
备GTM/DN故障情况:如果备GTM故障,则立即拉起来为pending,然后有CMServer仲裁为备机;如果备GTM一直拉不起来,则CMServer仲裁让GTM主机由同步模式,切换为最大可用模式。
6.6.3GTM故障检测与切换

GTM主故障恢复流程
1、CM Agent定期监测GTM进程运行状态、磁盘状态、端口使用状态,并从GTM获取当前主备角色、全局事物ID、主备连接状态,同步状态等,然后上报给CM Server。
2、判断GTM备与主的连接状态;
3、在GTM故障时,CM Server根据收到的GTM状态信息,仲裁GTM备升主,并将升主指令下发给CM Agent,由Agent通知GTM备执行升主动作,主备切换动作完成,Agent定时任务会上报新的状态给CM Server。
6.6.4多AZ场景下,GTM故障的处理原则
GTM主故障,依次优先选择用户初始指定、原主同AZ备、AZ优先级最大的GTM备升主。1.
主恢复,不自动回切,可以人工回切;角色降备。
2.GTM备故障,不切换。备恢复,恢复原先主备模式。
3.基于上述原则,能够处理GTM单点故障和多点故障。GTM故障包括自身故障和GTM与ETCD的HA故障。
6.6.5GTM故障处理
运维宝典:GTM故障处理
6.7Quorum同步协议
参数:主机同步列表设置synchronus_standby_names=ANY xx(dn list)。
机制:主机同时向所有备机发送日志,事务提交以同步快的备机为准,多数备机同步日志后主机事务即可提交。作为事务提交参考的是同步备,其他备机是异步备,作为冗余备份。
实现:每个WalSnd都记录已经同步的日志进度,并在收到备机应答后及时更新同步信息,并及时唤醒backend线程,backend线程只需要等待唤醒就可以回复给调用者事务已提交的信息。
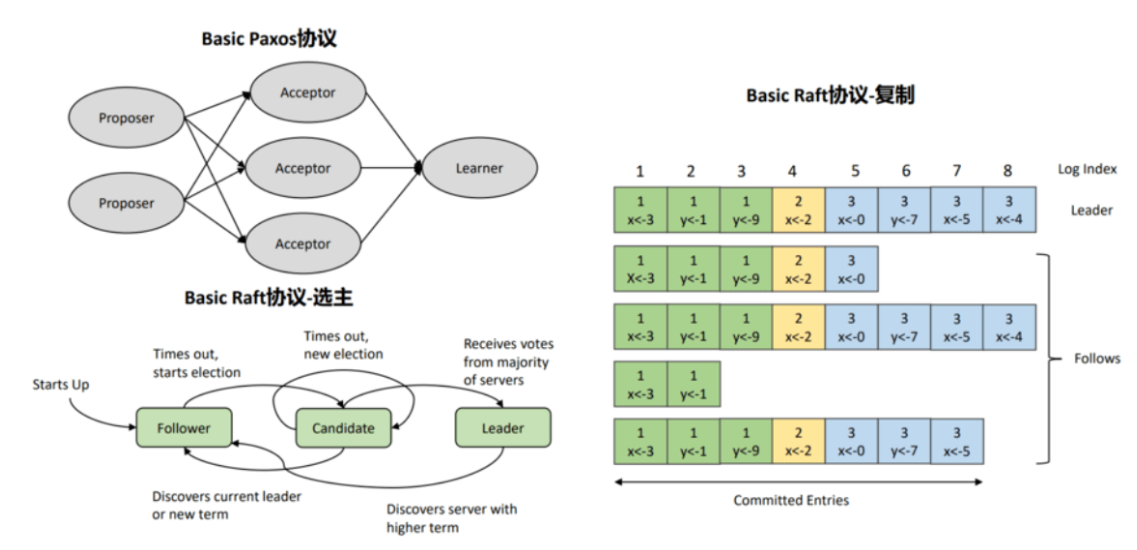
6.8、一致性复制协议
一致性复制协议Paxos、Raft等,在事务提交前,会进行一致性检测,满足半数以上的多数派响
应之后才可以提交。
两阶段提交
第一阶段:Propose阶段。Proposers向Acceptors发出Propose请求,Acceptors针对收到1.的Propose请求进行Promise承诺。
第二阶段:Accept阶段。收到多数派Acceptors承诺的Proposer,向Acceptors发出Accept请求,Acceptors针对收到的Accept请求进行接收处理。
第三阶段:Commit阶段。发出Accept请求的Proposer,在收到多数派Acceptors的接收之后3.
标志着本次Accept成功。向所有Acceptors追加Commit消息。
6.9、主备同步日志
6.9.1 同步数据的形式
流式复制(Stream Replication):是指将主节点上产生的事务日志记录(WAL)通过网络传输到备节点,备节点按照顺序应用这些日志记录来更新自己的数据。流式复制的优点是实时性高、数据量大时延迟较低,并且可以保证备节点的数据与主节点完全一致。
逻辑复制(Logical Replication)则是指在主节点上解析SQL语句并将其转化为逻辑日志,再将逻辑日志发送给备节点,备节点根据收到的逻辑日志应用相应的SQL语句来更新自己的数据。逻辑复制相对于流式复制的优势在于支持跨平台、跨版本的数据同步,而且可以过滤掉某些不需要同步的数据。但是,由于要解析SQL语句,所以逻辑复制在处理大量数据时性能可能会比流式复制略低。
6.9.2 流式复制的流程
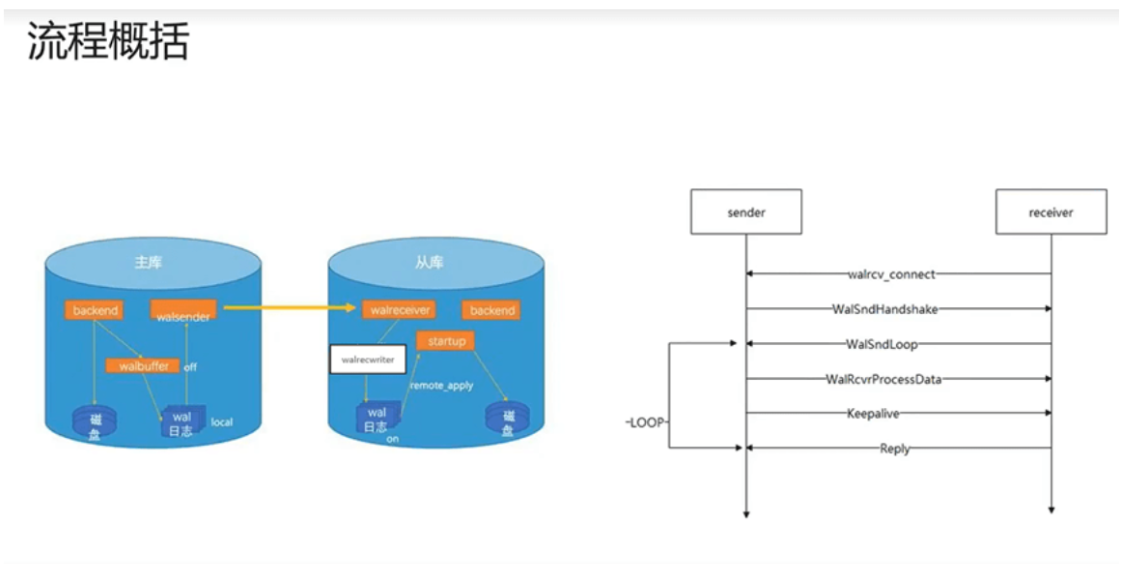
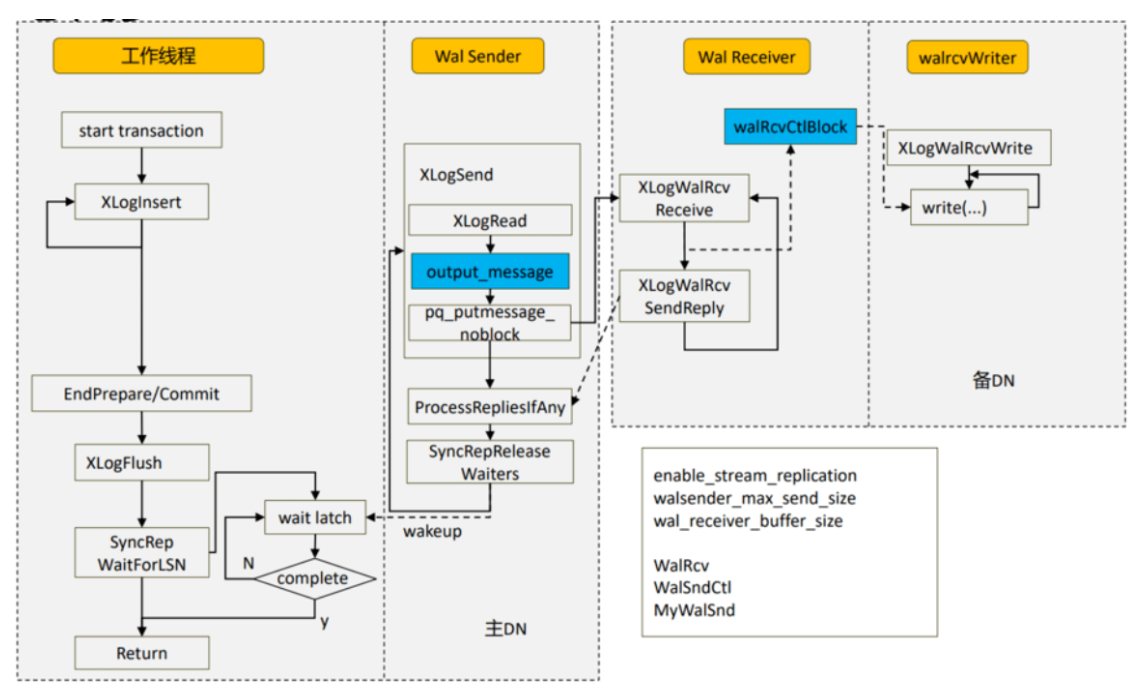
参与流式复制的几个线程以及过程:
Backend,客户端那边传过来的SQL语句,比如一个事务,写数据库,回写到walbuffer中walbuffer中会有一个walsender线程,刷写到wal日志,相当于持久化到本地磁盘,然后walsender会从日志中读取对应的日志,发给从库的walreceiver线程,拿到这些数据,放到walreciver buff中,类似于一个共享内存,数据存在的话,会唤醒walreciver write这个线程进行写日志,后面回唤醒startup线程进行日志回放,最终把数据刷新到数据页中去。
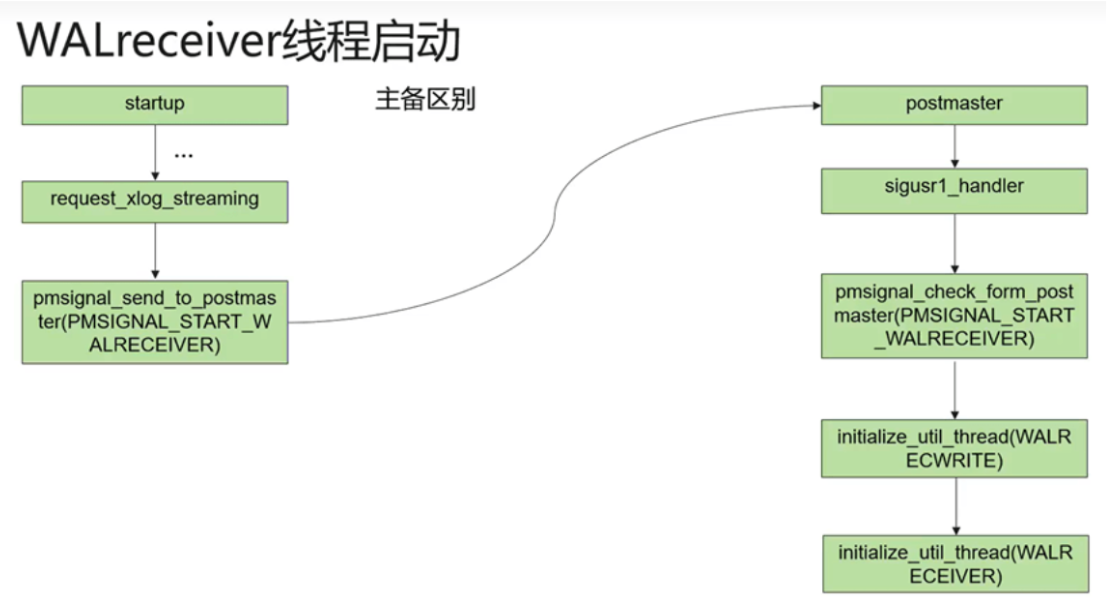
6.9.3 walreceiver线程
Walreciver线程只会存在于备机上。在数据库拉起后,postmaster线程会拉起startup线程进行
回放,把日志回放完。
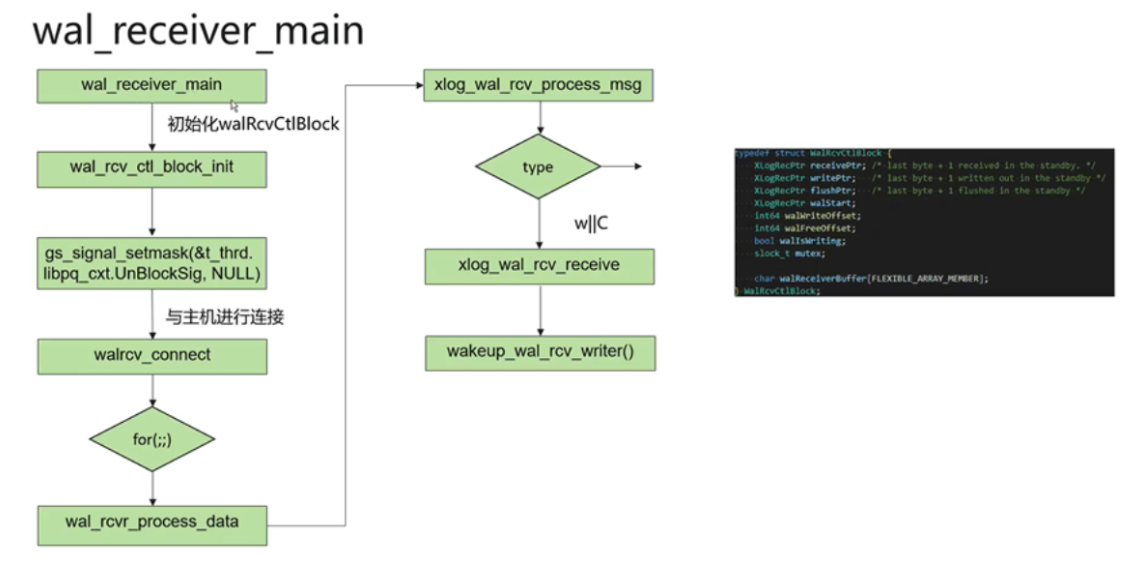
6.9.4 walsender线程
Walsender线程只会存在于主机上
6.10 主备切换
6.10.1主动切换--计划内切换switchover
·用于切换主备的角色(负载均衡、手工切换AZ的场景下)
·switchover比failover多了一个主机降备的处理,如下图所示。必须主机先降备然后备机再升主(保证主机日志已经完全同步备机)。备机升主过程参考failover流程。
主机降备后给备机发送NODESTATE PROMOTE APPROVE让备机启动升主。
switchover切换过程是:
1.cm发送switchover命令给备机
2.备机通知主机降备
3.主机降备后通知备机升主 具体流程见如下流程图所示:
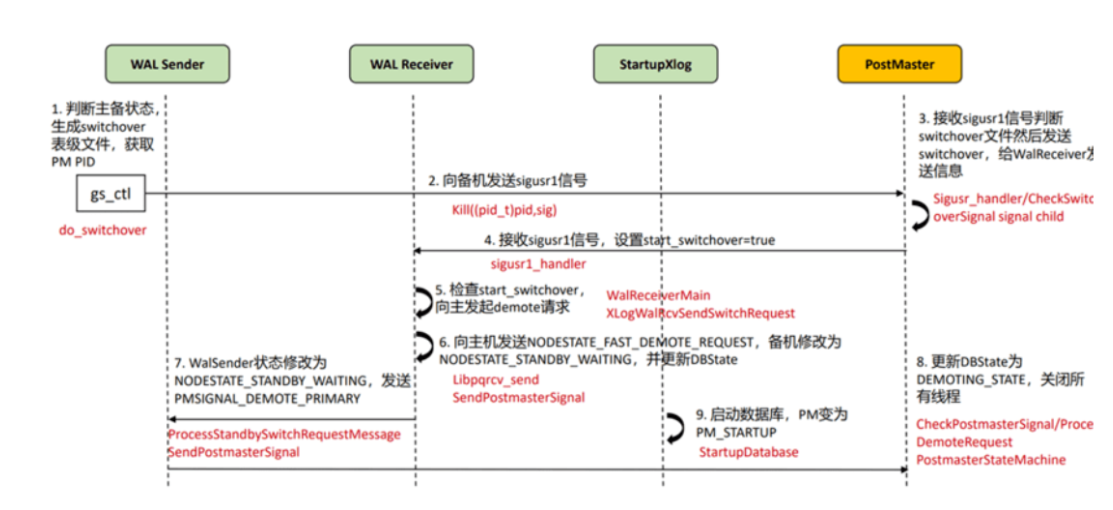
switchover完成时间主要和xlog日志待回放量,刷脏页数有关。
空载情况下,备机给主机发送信号到主机给备机回应switchover信号,由于需要做一次checkpoint,具体时间取决于刷脏页数。从备升主NOTIFY_SWITCHOVER 到主DN正常,具体时间取决于待回放日志量(从当前已回放完成的位置作为起点,回放到最后一条xlog)。
6.10.2主备倒换--计划外切换failover
·用于无主状态下升主(集群启动、主机挂掉场景下)。
·实现的核心是设置条件来关闭Startup线程,并在Startup停止信号后,将实例状态、实例角色和数据库状态重置。
具体流程见如下流程图所示:
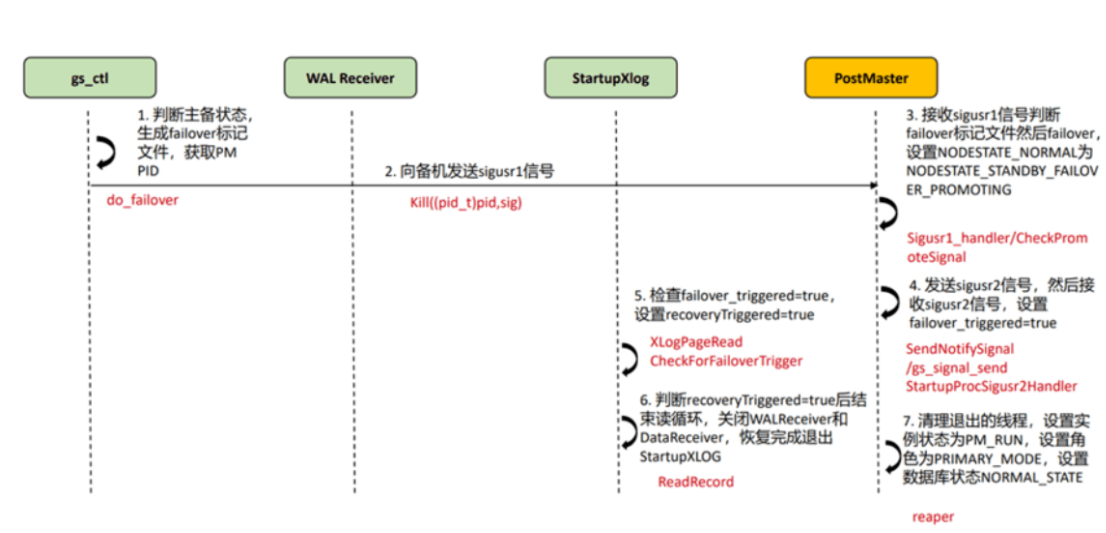
备升主的流程,显示判断主备状态,发现failover,于是PostMaster向startup发送备升主的请求,备机的startup通知walreceiver和walreceiver write两个线程退出,然后startup在完成恢复后正常退出,postmaster升主进行正常处理(一开始的时候postmaster是备机的主)整个备升主过程,具体时间取决于待回放日志量(从当前已回放完成的位置作为起点,回放到最后一条xlog)。
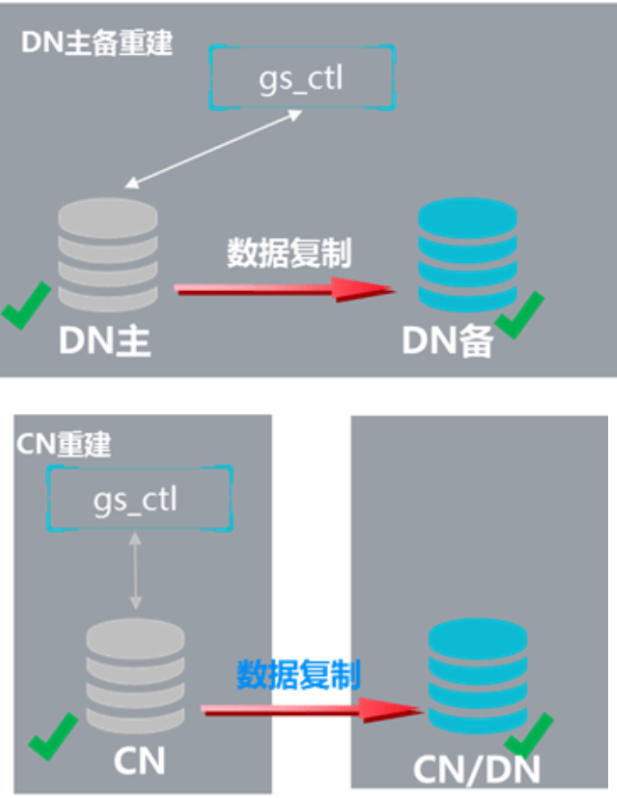
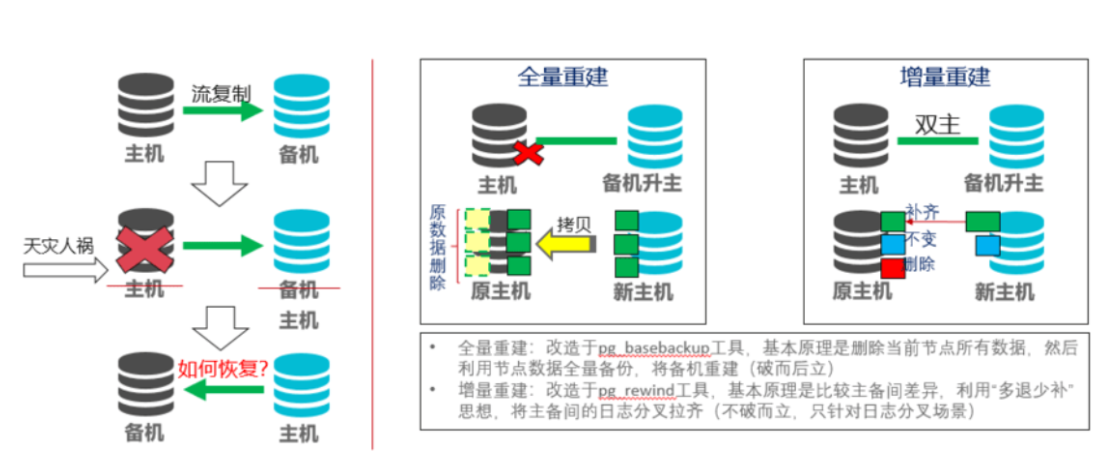
6.11数据重建(全量build和增量build)
build主要完成从一个实例重建另一个实例的工作,主要可以分为全量build和增量build两种模式,全量build通过删除本地数据目录绝大多数文件,并从对端拷贝的方式进行build;增量build通过比较本地和对端数据目录文件和日志差异的方式,对各个文件进行多删少补的操作完成build,最终是本地与对端达成同步。
6.11.1数据节点故障恢复和副本同步原理--备机全量重建
·用于实例故障后数据的重建
·分类:按照功能分为DN Build DN、CN build CN、CN build DN;按照实现分为全量build和增量build
·场景:重建功能的主要目的是单点故障修复(DNbuild DN、CN buildCN),另一个作用是进行在线扩容元数据的同步(CN build DN)
全量build要全部依据主机数据进行重建,增量build只拷贝差异文件,一般用于主机故障后重新加入集群。
6.11.2数据节点故障恢复和副本同步原理--备机增量重建
6.11.3build指令
命令格式重建备DN
cm_ctl build [-c] | [-n NODEID -D DATADIR [-f] [b full]] [-t SECS]
参数说明
-c:重建cm_server(将主节点的dcc数据目录拷贝到指定节点,只适用于一主一备式)
-n NODEID:指定重建备DN,NODEID为节点名称,可通过cm_ctlquery-Cv命令查询。-n参数需要和-D参数一起使用。
-D DATADIR:指定重建备DN,DATADIR为指定实例数据目录,可通过cm_ctlquery-Cvd命令查询。-D参数需要和-n参数一起使用。
-f:强制重建备机。-f参数需要和-n以及-D参数一起使用。
-b full:指定进行全量build。不指定情况下,对于一主多备集群部署模式进行auto build。auto build指:先调用增量build,失败之后调用全量build。对于主备从集群部署模式,则默认进行增量build。-b参数需要和-n以及-D参数一起使用。
重建备DN:
cm_ctl build -n2-D/data1/omm/cluster/data/datanode1s
重建 cm_server:
cm_ctl build -c
参数说明:
-f 强制重建备机。
-b full指定进行全量buid。不指定情况下,对于一主多备集群部署模式进行auto build。auto build指:先调用增量build,失败之后调用全量build。对于主备从集群部署模式,则默认进行增量build。
-c 重建 cm_server(将主节点的dcc数据目录拷贝到指定节点,只适用于一主一备
6.12集群高可用常用命令
1.指定AZ的数据库主备倒换:
cm_ctl switchover -z AZ1
2.指定节点的数据库主备倒换:
cm_ctl switchover-n1 -D/data1/omm/cluster/data/datanode1
3.将所有DN实例统一从主切换到备
cm_ctl switchover -A
4.重置节点状态为初始配置状态:
cm_ctl switchover -a
5.查看集群状态
cm_ctl query -Cv //查看集群详细状态,带有主备关系的。
cm_ctl query -Cvd //显示实例的数据目录。
cm_ctl query -Cvs //显示导致各个节点主备实例数量不均衡的实例,确定与集群安装初始状态不同的实例。
cm_ctl query-CvF //显示各个节点Fenced UDF状态。
cm_ctl query -Cvip //显示物理节点ip和所有CN、DN的port。
cm_ctl query -Cvx //显示集群所有异常实例。
cm_ctl query -Cvz ALL //显示集群所有实例AZ名称。
cm_ctl query -CvL ALL //显示逻辑集群状态和DN所属的逻辑集群名称。
6.执行节点修复加回被剔除的CN。
gs_replace -t config -h hostname
gs_replace -t start -h hostname
七、高可用特性
7.1主备高可用机制
7.1.1主备最大可用同步
如果采用同步模式,主备通信发生异常,会阻塞主机上的业务使用。
如果采用了主备最大可用同步(most_available_sync=on),在有同步备机宕机时,主机不会因为同步备机的故障而被阻塞,直接提交事务。若开启了keep_sync_window参数,此参数为延迟进入最大可用模式的时间的参数,若在keep_sync_window设置的时间窗口内,同步备机处于故障,如果之前采用同步模式,会阻塞主机的事务提交。若在keep_sync_window超时窗口内,同步备机故障恢复,且满足当前所配置的同步备数量,则不阻塞事务,恢复到正常状态。优点:
主机的业务不受备机的影响,同时也保证了数据的高可靠性
说明:
GaussDB默认采用主备日志异步复制的方式,您可以通过配置synchronous_standby_names参数列出采用主备日志同步复制方式的备机名称,同时配置most_available_sync参数为on。
1.synchronous_standby_names
参数说明:
潜在同步复制的备机名称列表,每个名称用逗号分隔。取值范围:字符串。当取值为*,表示匹配任意提供同步复制的备机名称。支持按如下格式配置:
ANY num_sync (standby_name [,.]) [, ANY num_sync (standby_name l, ...])]
[FIRST]num_sync (standby_name l, ...])
standby_name [, ...]
若使用gs_guc工具设置该参数,需要如下设置:
gs_guc reload -Z datanode -N @NODE_NAME@ -D @DN_PATH@ -c”‘synchronous_standby_names='ANY NODE 1(dn_instanceld1, dn_instanceld2)"’,或者:
gs_guc reload -Z datanode -N @NODE_NAME@ -D @DN_PATH@ -c“synchronous_standby_names='ANY 1(AZ1, AZ2)"‘,默认值:*
2.most_available_sync
参数说明:
在有同步备机故障时,主机事务不因同步备机故障而被阻塞。比如有两个同步备机,一个故障,另一个正常,这个时候主机事务只会等好的这个同步备,而不被故障的同步备所阻塞;
再比如执行quorum协议时,一主三同步备,配置ANY 2(node1,node2,node3),当node1、node3故障,node2正常时,主机业务同样不被阻塞。
该参数属于SIGHUP类型参数,请参考表1中对应设置方法进行设置。
取值范围:布尔型
on表示在所有同步备机故障时,不阻塞主机。
off表示在所有同步备机故障时,阻塞主机。默认值:off
3.keep_sync_window
参数说明:延迟进入最大可用模式的时间
当最大可用模式most_available_sync配置为on,在主备场景下,当存在同步备发生故障,导致不满足当前所配置的同步备数量(详细可参考synchonous_standby_name的含义)时,如果配置了keep_sync_window参数,则在keep_sync_window设置的时间窗口内,继续保持最大保护模式,即阻塞主机的事务提交,延缓进入最大可用模式的时间。
若在keep_sync_window超时窗口内,同步备机故障恢复,且满足当前所配置的同步备数量,则不阻塞事务,恢复到正常状态.
如果设置keep_sync_window,推荐最小配置为5s,以避免监控系统监控到网络不稳定的误报。
该参数属于SIGHUP类型参数,请参考表1中对应设置方法进行设置。取值范围:整型,范围0~INTMAX,单位为秒
0表示不设置keep_sync_window超时时间窗口,即直接进入最大可用模式。
其余表示keep_sync_window超时时间窗口的大小。
默认值是0
7.2流复制
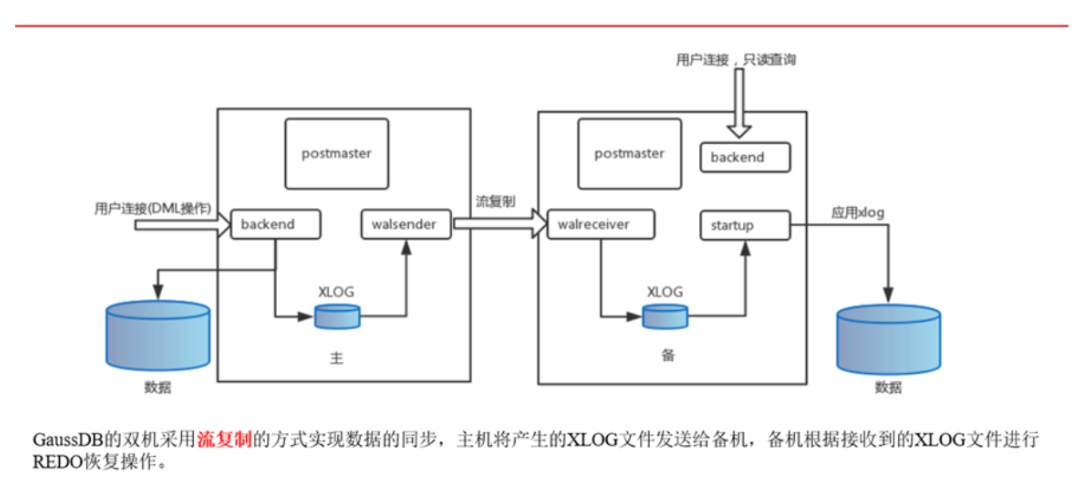
主备流复制的核心由三个进程组成:
1)walsender:用于主库发送WAL日志记录至从库
2)walreceiver:用于从库接收主库的WAL日志记录
3)startup:用于从库apply日志
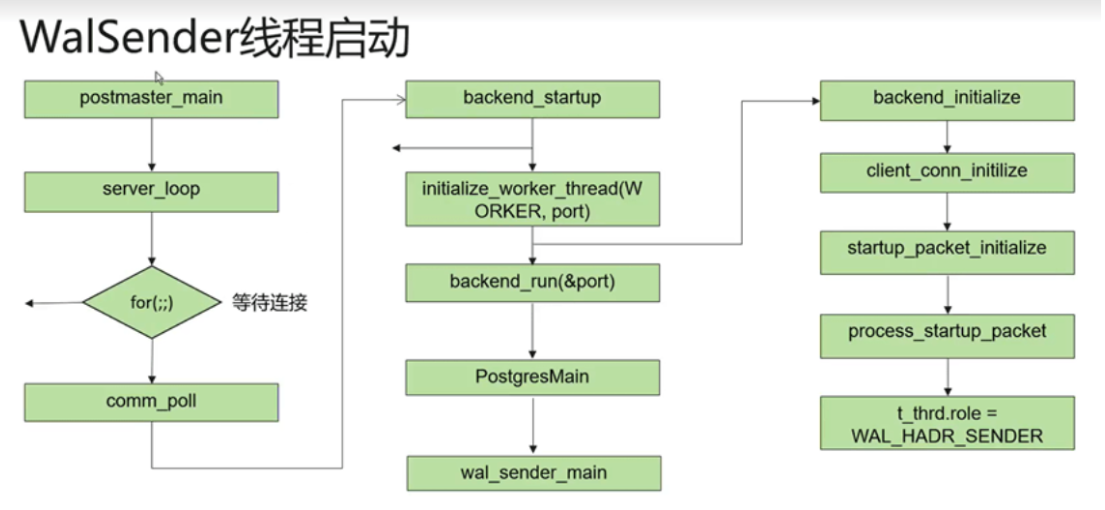
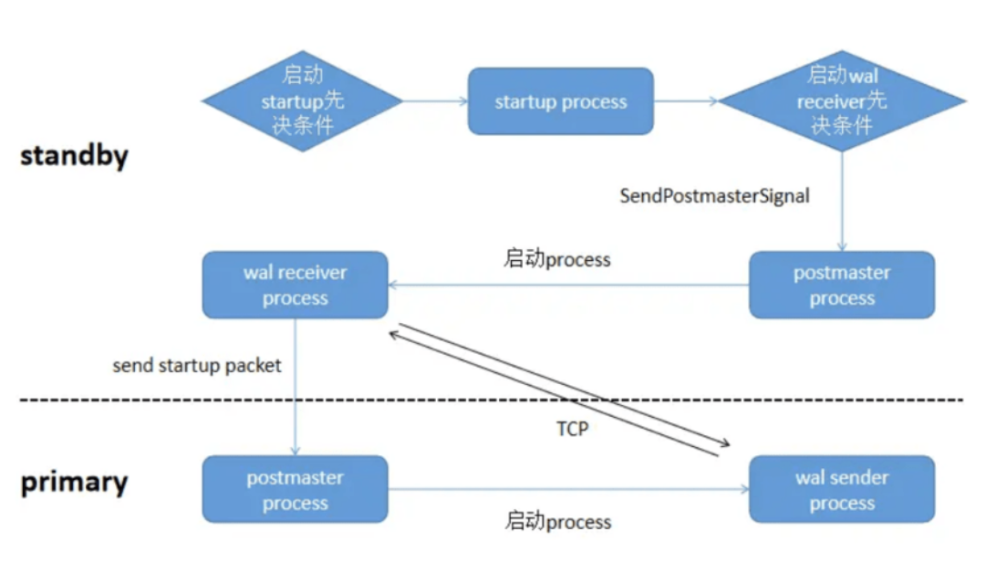
流复制启动过程中,首先启动的startup进程,然后触发启动walreceiver进程,之后walreceiver发送信号,启动walsender进程。
下图是三个进程启动过程示意图:
如果备机故障了,主机发不过去xlog,后面备机起来之后,主机会继续同步xlog
如果备机故障时间过长,主机的xlog日志已经被删除,那么备机就同步不了了,就需要做build同步。
build同步时有两个进程,build过程会先把备机上的文件全删除,然后一个build进程去同步数据文件,另外一个build进程去同步增量的xlog。
7.3高可用日志回放
7.3.1判断是并行回放还是极致RTO
gs_guc check-Z coordinator -Z datanode -N all - all -c "recovery_max_workers""recovery_parse_workers" -c "recovery_redo_workers“
recovery_max_workers=1剩下两个>1就是rto
7.3.2串行回放
7.3.3并行回放
并行回放过程
并行日志回放过程如下:
1.WalRcvWriter将主库发送的XLog写入磁盘;
2.Startup子线程从磁盘读取XLog,根据XLog的类型调用不同的分发(dispatch)函数,其中:
A、非事务日志分发给PageRedoWorker线程:根据处理的数据文件选择对应的回放线程
B、事务日志由Startup线程自身回放;分发的过程就是将XLog放入对应PageRedoWorker的SPSC队列中,若队列满了Startup线程会循环等待。
3.PageRedoWorker线程从SPSC队列中读取XLog后回放,更新本线程已经回放的XLog位置;
4.Startup线程获取所有PageRedoWorker中已经回放的XLog的小位置,判断自身的事务日志能否回放,若可以则调用对应的回放函数;
通过保证只有一个线程(Startup)来回放事务日志避免了事务回放乱序的问题,但还有个问题:即使是同一个事务内也可能存在对同一张表多次操作的XLog(例如先做INSERT,再做DELETE),这些操作之间也可能存在依赖,为了解决这个问题,并行回放会根据表的relfilenode计算回放此日志的工作线程编号。除非对表做修改(例如truncate),不然表的relfilenode是不会发生变化,这样保证同一个表的事务日志都由同一个线程回放,也就保证了回放的先后顺序,但这带来了另外一个问题:若某张表上的操作非常频繁(例如BenchmarkTPC-C场景),导致产生的XLog非常多,会使得某个工作线程非常繁忙,剩下的工作线程可能很空闲。
除此之外,还有一些特殊的DDL操作,例如创建表空间、创建数据库等,需要所有工作线程之间同步,并行回放机制回放的并不是“原始”的XLog,而是对其进行了封装,通过一些状态来标记待回放的日志是否需要同步。
7.3.4极致RTO
极致rto是通过将回放xlog拆分到block级别分发给不同线程回放,来提高并发,加快回放速度
Xlog读取
Read worker:读取xlog文件
Read page worker: 从read work的buf中读出xlog
Read manager:读取升主信号通知read worker和read page worker
Xlog分发
startup:解析record,分发到batch线程
Batch:将item拆分为block,然后分发给manager线程
回放
Page manager:根据hash分发给不同redo线程
Page redo:进行redo
xlog文件名解读和LSN
xlog就是一般说的wal日志,日志文件在数据节点如下目录中,文件名为24个数字(十六进制)
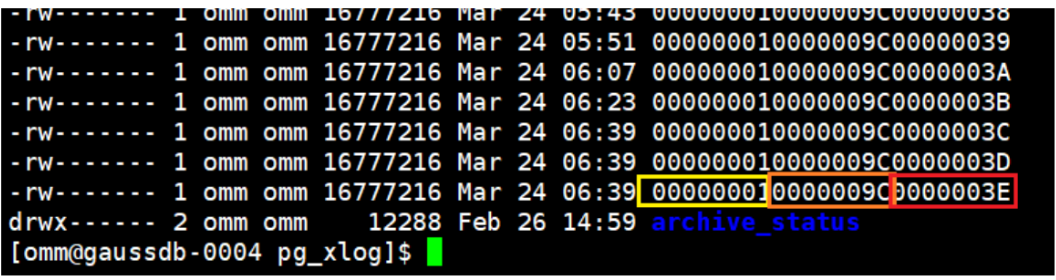
xlog日志名中,每个字符是用十六进制表示的,所以每个字符有4bit。
1)最高位32bit(前8位十六进制字符):表示时间线,按1、2、3递增2)中间32bit/8位十六进制字符:表示LSN编号的高位数值,按0、1、2、3递增
3)尾部32bit/8位十六进制字符:表示LSN编号的低位数值,按0、1、2、3递增,最大为0000FF,比如下图低位达到FF后,高位进1,低位从00开始
2.LSN编号解读
Isn一般表示为“n位十六进数/8位十六进制数”
1/18756A20:LSN高位(1)/LSN低位(18)+当前LSN在日志中的偏移量(756A20)最后6位,24bit,正好可以表示16MB的空间(2^24/1024/1024=16MB)如:LSN为0/A4F9A410
如何解读:
1)0表示高位LSN号,即xlog文件名中的中间8位00000001
2)A4表示低位LSN号,即xlog文件名中的尾部8位000000A4,最大为000000FF
3)F9A410,表示当前的LSN号在xlog文件(文件名0000000000000001000000A4)中偏移量为F9A410。最大为FFFFFF,即2^24bit=16MB,因此一个xlog文件大小是固定的16MBLSN号后六位,只能映射这么多空间。
xlog类问题处理步骤:
7.4容灾
7.4.1GaussDB高可用中容灾部署方案
1.同城双集群容灾
同城双中心是指在同城或邻近城市建立两个可独立承担关键系统运行的数据中心,双中心具备基本等同的业务处理能力并通过高速链路实时同步数据,日常情况下可同时分担业务及管理系统的运行,并可切换运行;灾难情况下可在基本不丢失数据的情况下进行灾备应急切换,保持业务连续运行。
特性规格:共享存储正常的场景RPO=0,RTO<1min。2.两地三中心异地容灾
两地三中心,顾名思义,两地指的是两座城市,即同城和异地,三中心指的是生产中心,同城容灾中心(同城双集群容灾)以及异地容灾中心。异地灾备中心是指在异地的城市建立一个备份的灾备中心,用于双中心的数据备份,当双中心出现自然灾害等原因而发生故障时,异地灾备中心可以用备份数据进行业务的恢复。
技术规格:
灾备数据库实例升主允许丢失一定的数据,RPO<=10秒;灾备数据库实例处于normal态,灾备升主RTO<=10分钟,数据库实例处于degraded状态等叠加故障场景下,执行灾备数据库实例升主RTO一般在20分钟以内。
演练特性:计划内主备数据库实例倒换,无数据丢失RPO=0,RTO<=20分钟(包含主数据库实例降为灾备实例,灾备数据库实例升主两个流程)。
7.4.2双集群高可用和容灾方案-Dorado双集群简介
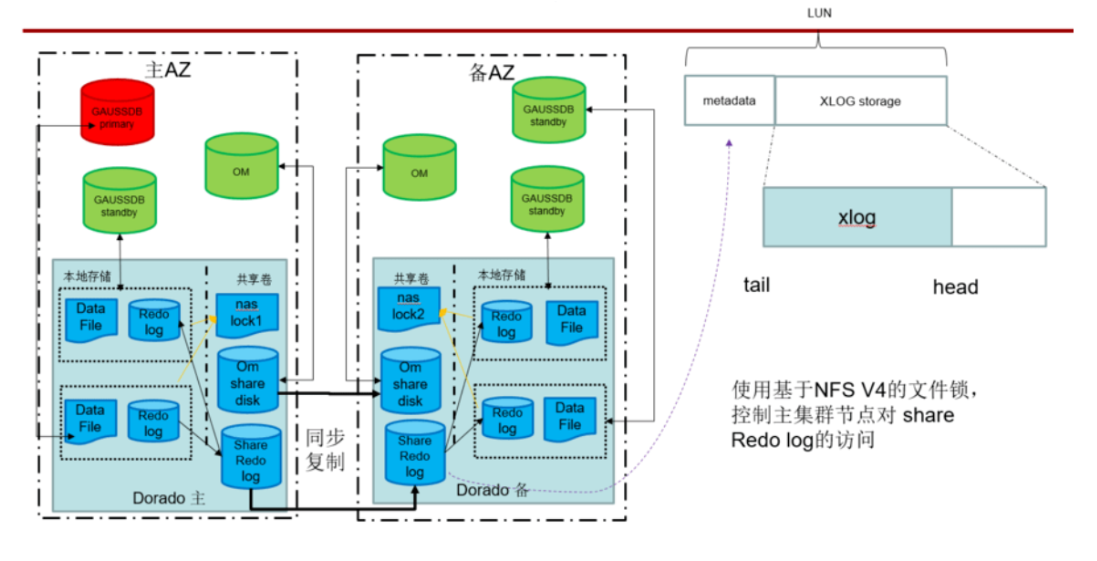
关于dorado存储,我们使用了他的2个特性:
1)远程复制LUN
2)NAS文件锁
3)日志同步原理
Gaussdb 通过使用 远程复制LUN来实现跨集群的xlog日志的共享:日志写入本测的share redolog中,由doardo存储同步到另一端的dorado存储上。通过使用nas lock在集群内部实现对 share redo log的访问控制:持有nas lock文件锁的节点才能升为primary节点,否则不能升,以此避免多primary节点同时往share redo log中写入数据造成数据破坏。
7.4.3Dorado双集群搭建
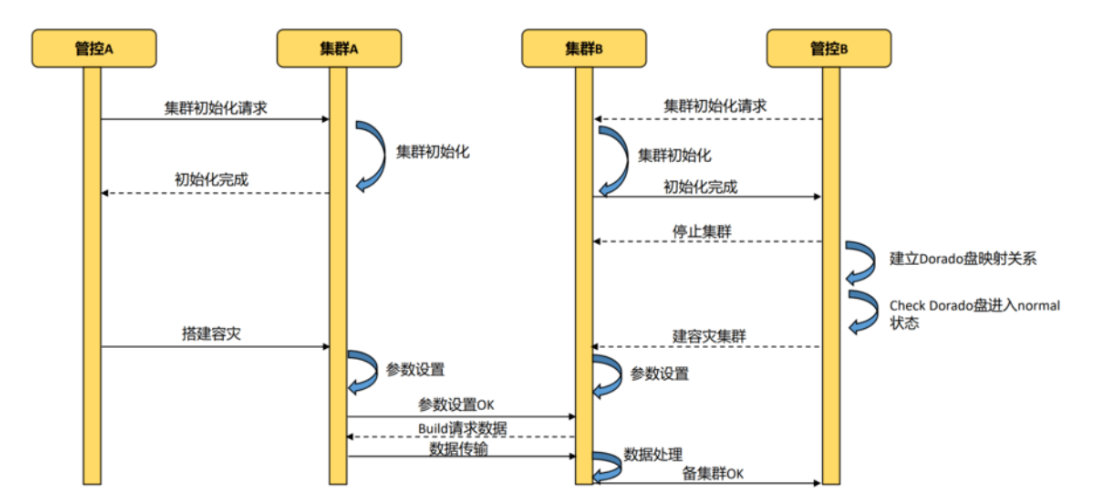
搭建步骤原理
1.集群分别初始化,此时是2个独立的集群
2.搭建双集群时,需要指定主备
a)首先配置好dorado 盘的映射关系(创建远程复制LUN),主集群的dorado盘为远程复制LUN的主端,备集群的dorado盘为远程复制LUN的备端。
b)配置好之后,LUN间会进行数据复制(从主到备)b)
c)配置主的容灾参数,运行备集群的节点连接
d)配置连接参数,同步认证信息
e)从主集群进行数据全量同步(build)
f)按照备集群拉起
3.开始按照双集群正常运行
搭建流程图
7.4.4Dorado双集群切换
7.4.4.1计划内切换switchover
计划内切换 通常是 容灾演练 场景
计划内切换,两个集群都处于正常运行状态,切换过程是1.原主集群降为备集群
2.切换dordo共享盘的主备
3.将备集群升主
流程图如下:
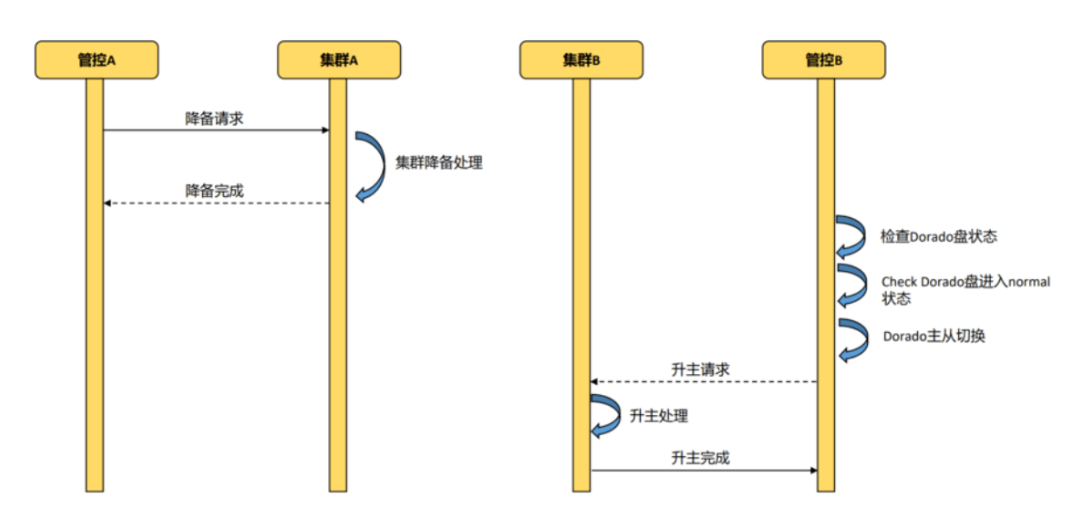
7.4.4.2计划外切换failover
计划外切换 通常是 主集群故障,需要备集群接管业务的场景。
计划外切换:
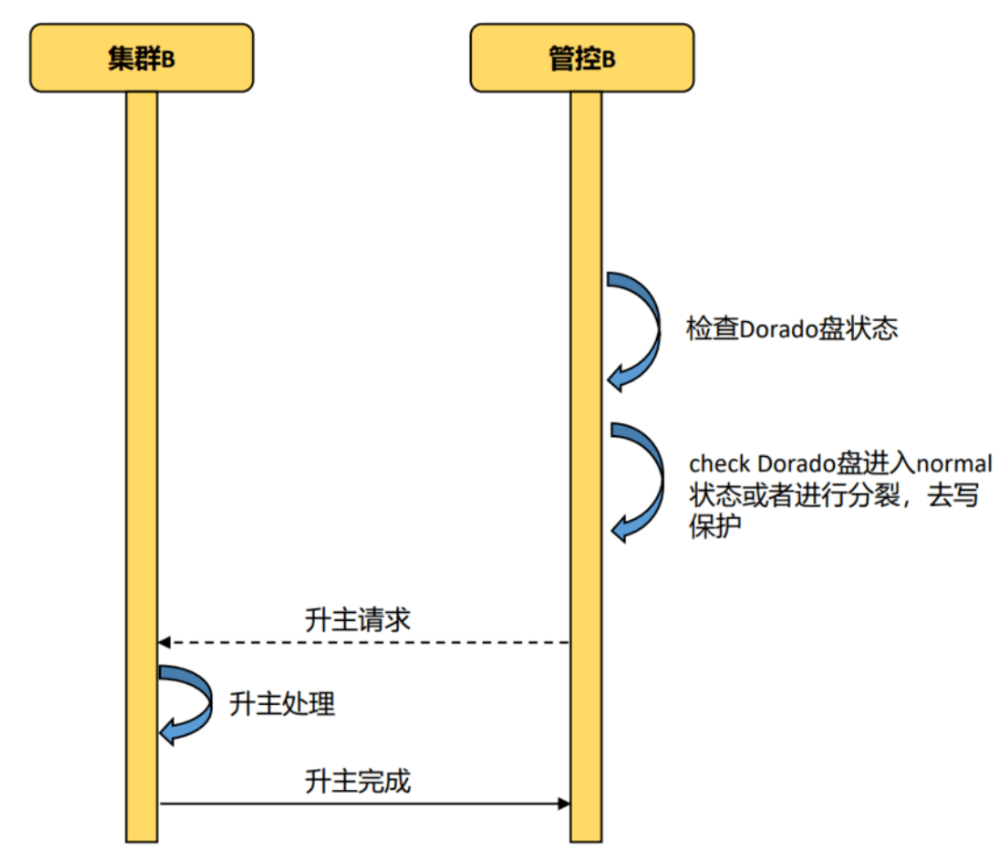
1.确认dorado共享盘的状态
a)正常状态:说明对端的dorado存储还是正常工作,进行dorado共享盘的主备切换b)分裂状态:说明对端dorado存储出现异常了(或者dorado存储间的网络故障),此时需要去掉本端dorado共享盘的写保护(即可写)
2.将备集群升主
流程图如下:
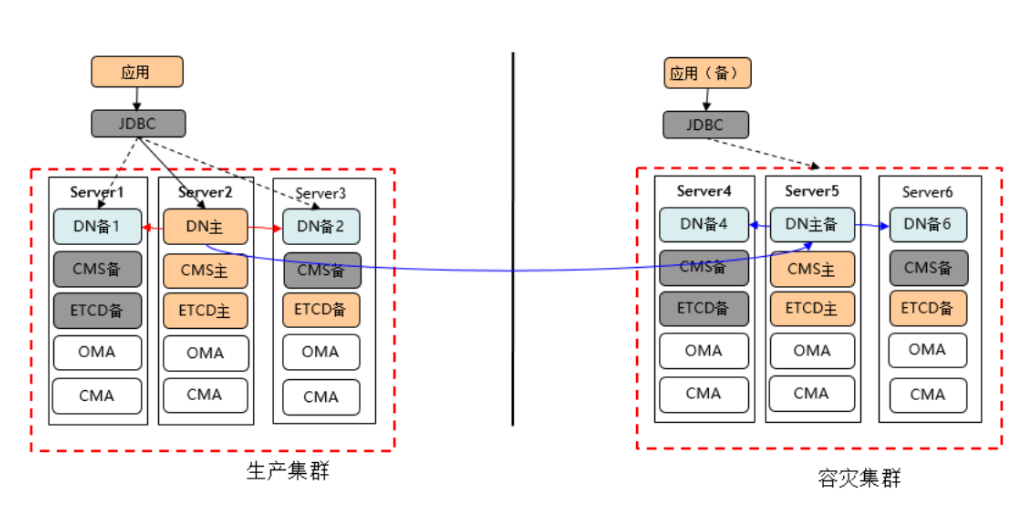
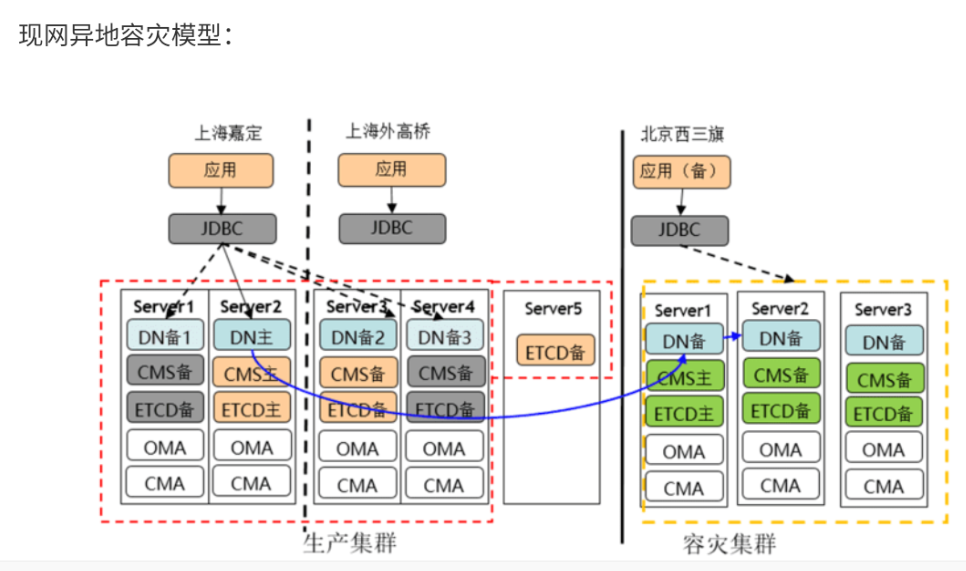
7.4.5高可用容灾方案-异地容灾
地域容灾通常是指主备数据中心距离在200KM以上的情况,主机房在发生以上极端灾难的情况下,备机房的数据还具备能继续提供服务的能力
7.4.6异地灾备集群搭建
双集群是在单集群的基础上搭建的,备集群是主集群的备,在配置好之后,会有一个数据同步过程,即图中的build。同时因为有数据同步,所以需要制定主集群,数据最终以主集群的数据为准。1.集群分别初始化,此时是2个独立的集群2.搭建双集群时,需要指定主备 a)配置连接参数,同步认证信息 b)从主集群进行数据全量同步(build)c)按照备集群拉起 3.开始按照双集群正常运行
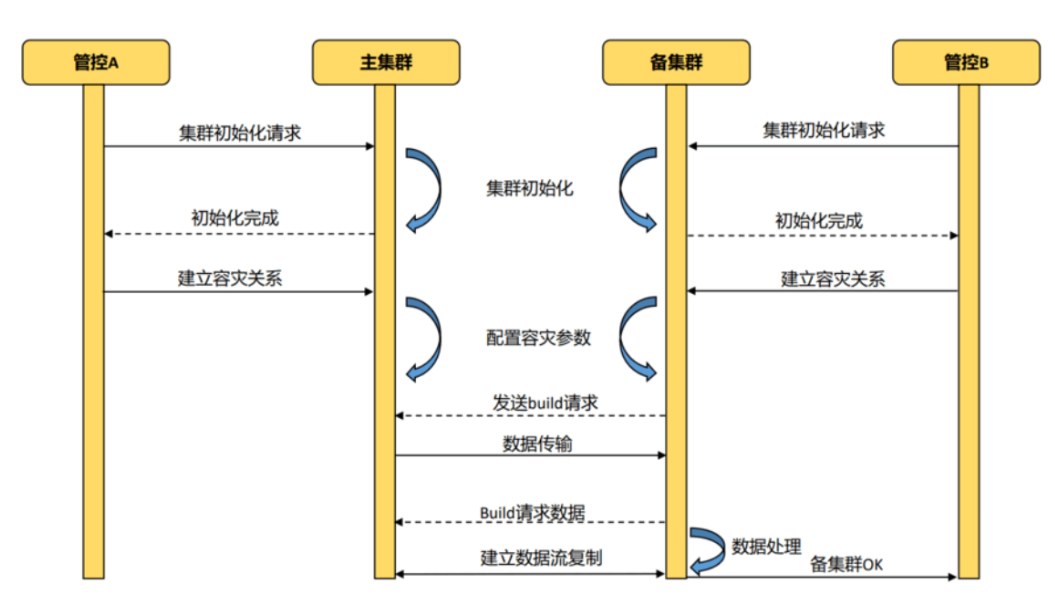
7.4.7异地容灾日志同步原理
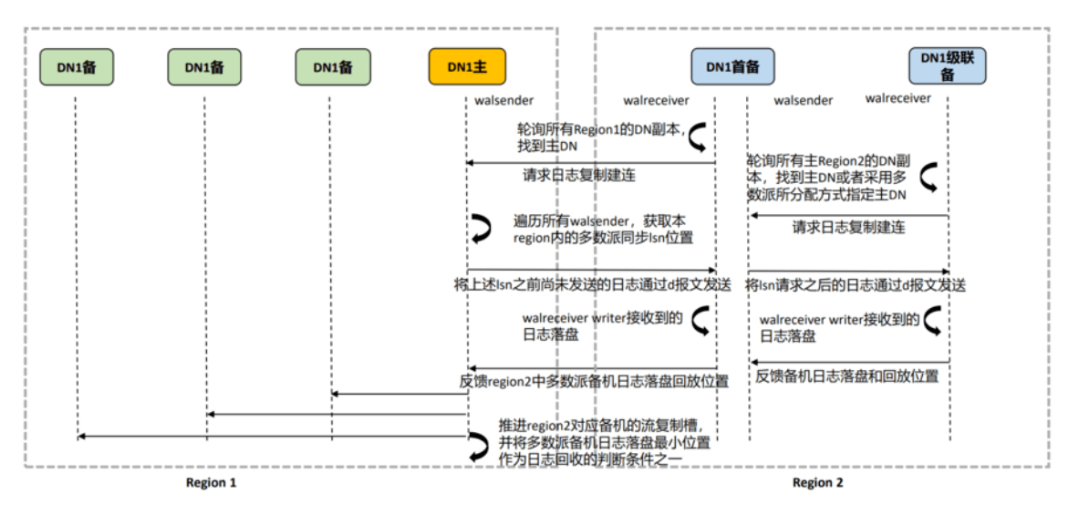
7.4.8异地容灾切换
7.4.8.1计划内切换switchover
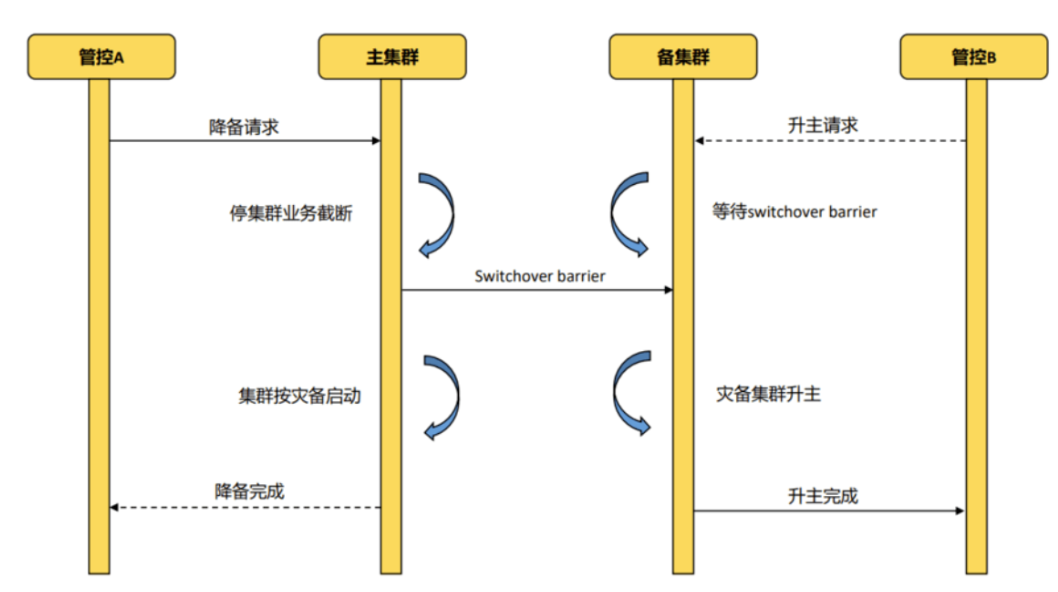
7.4.8.2计划外切换failover
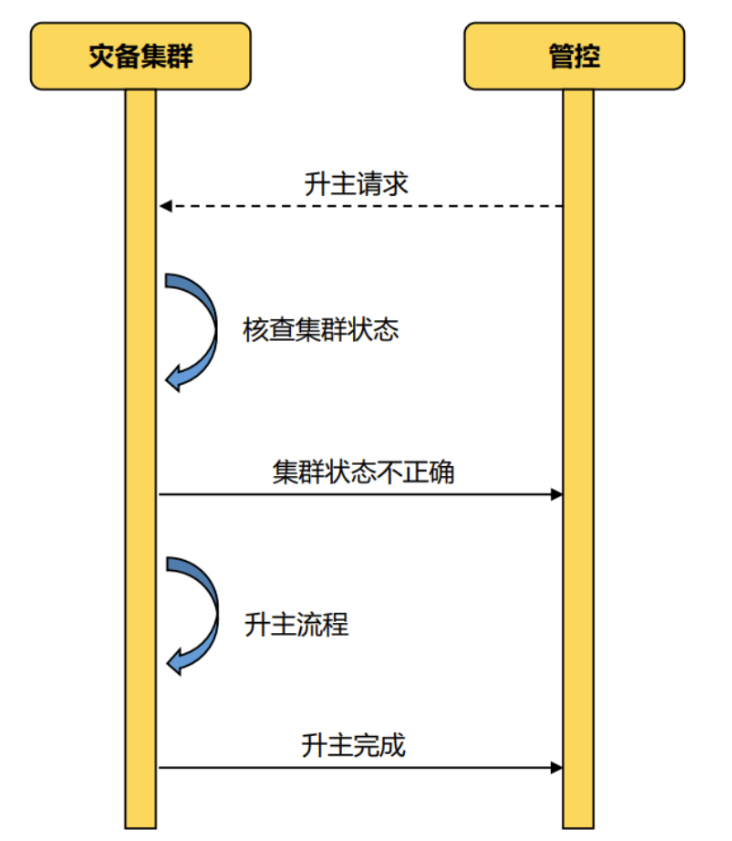
7.5备份恢复
GaussDB提供基于OBS/NAS/XBSA等多种存储介质的集群级、物理备份能力,并在同构数据库(分片个数相同,大版本号相同)中提供集群级恢复能力,支持全量备份和增量备份。采用分布式并行技术,并行地对每个数据实例的数据文件进行物理备份恢复,提供了极高的备份恢复性能。在此基础之上,还提供备份数据压缩、备份流控、断点续备等高阶功能。
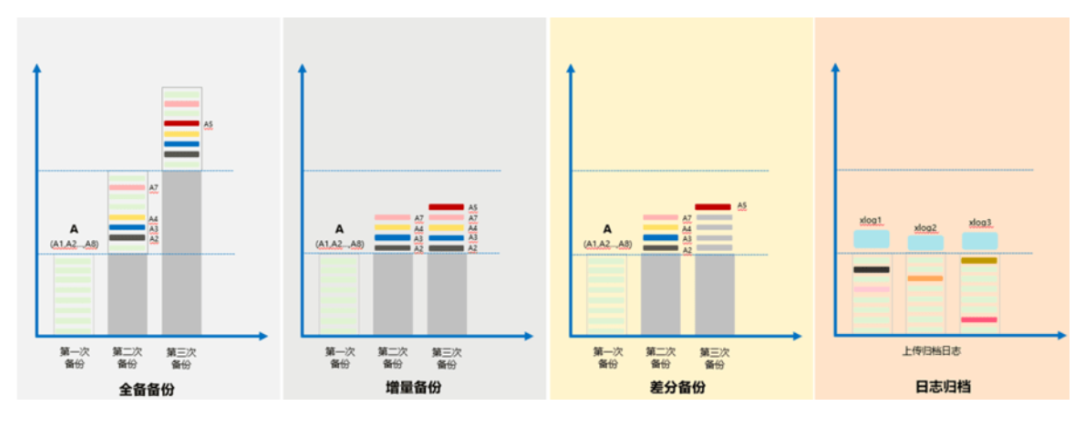
7.5.1几种备份恢复策略
全量备份
全量备份表示对所有目标数据进行备份,包含备份时刻点上数据库的全量数据,耗时长(和数据库数据总量成正比),自身即可恢复出完整的数据库。全量备份总是备份所有选择的目标,即使从上次备份后数据没有变化
增量备份
增量备份即差分备份,只包含从指定时刻点之后的增量修改数据,耗时短(和增量数据成正比,和数据总量无关),但是必须要和全量备份数据一起才能恢复出完整的数据库。GaussDB(for openGauss)默认自动每30分钟对上一次自动备份后更新的数据进行备份。
日志归档及PITR恢复
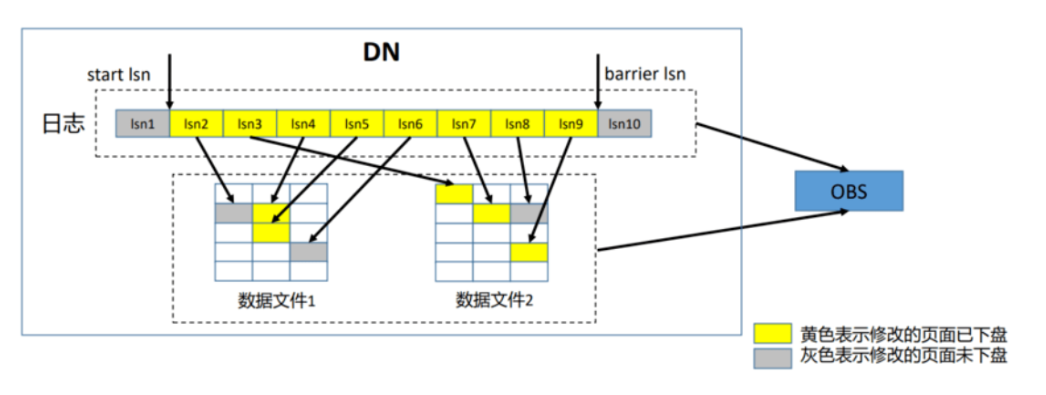
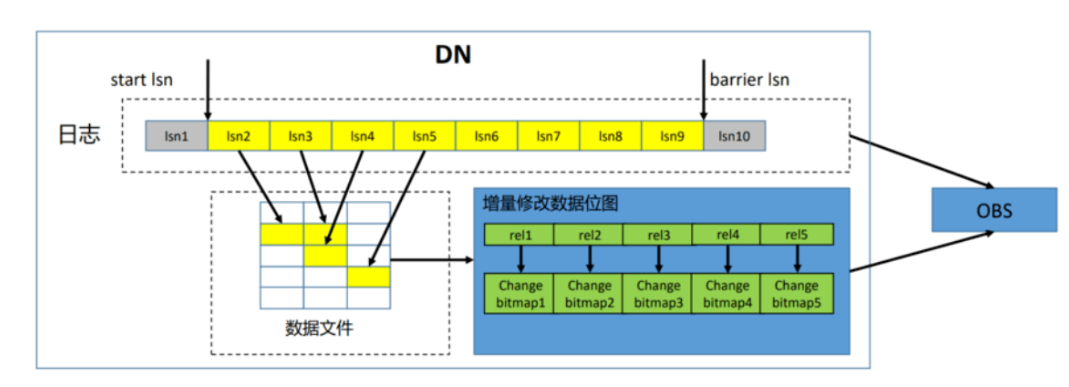
PITR功能包括日志归档功能,结合已经支持的全量备份和增量备份功能,从而支持集群的PITR功能。目前的分布式PITR的恢复时间粒度达到秒级,与当前全量、增量备份恢复功能相比,不仅可以提供更为灵活的备份恢复策略,也将进一步提升恢复的数据可靠性。
其中PITR备份策略如下图所示:
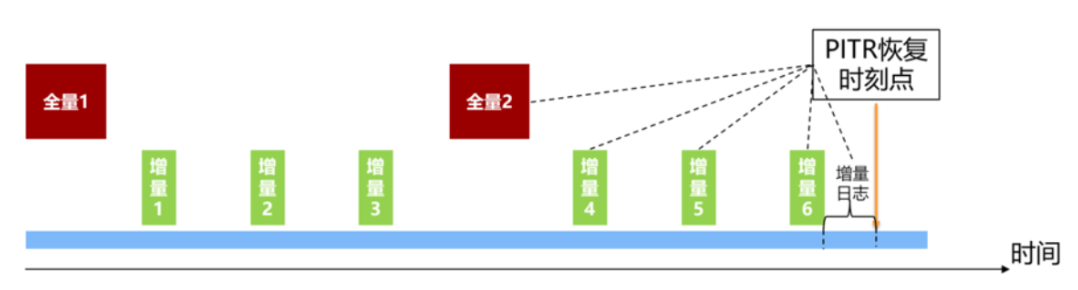
在该备份策略下,如果用户想要将数据库恢复到指定的某个时间点,就可以通过PITR技术来实现,原理为:
1.首先恢复用户指定时间点之前最后一次全量备份
2.然后恢复用户指定时间点之前、上述全量备份之后的若干次增量备份
3.最后回放用户指定时间点到上述最后那次增量备份之间的增量归档日志
备份策略
GaussDB默认开启的自动备份策略设置如下:
n保留天数:默认为30天
n备份流控:默认限速75MB/s。
n全量备份时间段:默认为24小时中,间隔一小时的随机的一个时间段,例如01:00~02:00,12:00~13:00等。
n全量备份周期:默认为一周内的每一天。
增量备份周期:默认每30分钟备份一次。
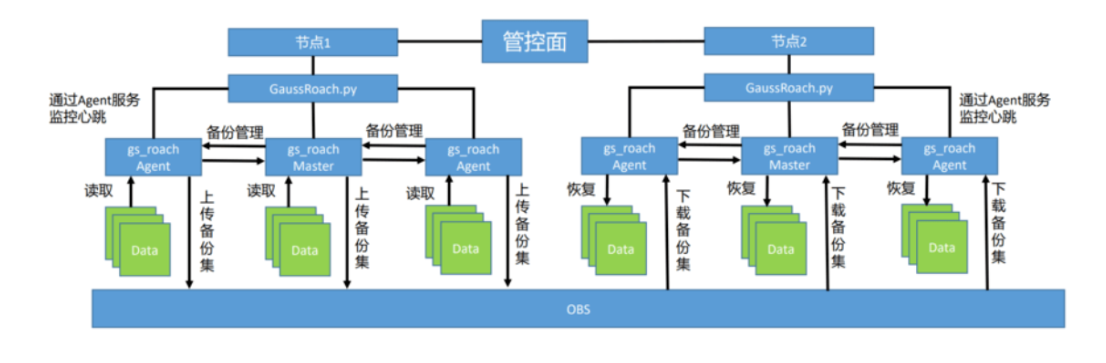
7.5.2集群备份恢复流程

















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









