







同前面的那篇文章一样(参见:最大熵模型进行中文分词),本文运用字标注法进行中文分词,分别使用4-tag和6-tag对语料进行字标注,观察分词效果。前面的文章中使用了模型工具包中自带的一个样例进行4-tag中文分词,但由于其选取的特征是针对英文词性标注开发的,故准确率和召回率较低(召回率为83.7%,准确率为84.1%)。 PS:为什么用作词性标注的特征也可以用来做分词呢?这是因为最大熵模型处理问题的时候和具体的实际问题是无关的,模型处理任何问题都会转化为对序列数据的标注问题。因此序列化标注的问题都可以通过最大熵模型解决,只不过针对不同的问题,特征的选取也不太一样。特征模板的的优劣会影响到结果的正确性。
第一部分 最大熵模型工具包安装说明
最大熵模型方面使用开源的张乐博士的最大熵模型工具包(Maximum Entropy Modeling Toolkit for Python and C++)。使用的中文语料资源是SIGHAN提供的backoff 2005语料,目前封闭测试最好的结果是4-tag+CFR标注分词,在北大语料库上可以在准确率,召回率以及F值上达到92%以上的效果,在微软语料库上可以到达96%以上的效果。以下我们将转入这篇文章的主题,基于最大熵模型的字标注中文分词。
下载安装和使用张乐博士的最大熵模型工具包,本文使用的是其在github上的代码:maxent , 安装说明:
1.进入到代码主目录maxent-master后,正常按照“configure & make & (sudo) make install就可以完成C++库的安装。
注意:(1)gcc编译器最好是4.7版本以上,我试过在4.4.3上面是不成功的,升级到4.7之后就可以了,具体请参阅:升级Ubuntu中g++和gcc的版本)。
(2)gcc版本没问题了,如果报出 ./configure错误,请参阅:Linux下./configure错误详解。
2.再进入到子目录python下,安装python包:python setup.py build & (sudo) python setup.py install,这个python库是通过强大的SWIG生成的。
注意:中间如果报出:python.h 没有各个文件或目录 的错误,请参阅:解决python.h 没有那个文件或目录 的方法。
关于这个最大熵模型工具包详情及背景,推荐看官方manual文档,写得非常详细。
第二部分 4-tag和6-tag
1.字标注。
什么是字标注呢?先看一个句子:我是一名程序员。将所有字分为4类,S表示单字,B表示词首,M表示词中,E表示词尾。
如果我们知道上述句子中每个字的类别,即:
我/S 是/S 一/B 名/E 程/B 序/M 员/E 。/S
那么我们就可以知道这个句子的分词结果:我 是 一名 程序员 。
从这里可以看出,分词问题转化成了一个分类问题,即对每个字分类。我们知道,机器学习方法可以很好地处理分类问题。 所以接下来,我们需要用机器学习的方法来解决分词。
2. 4-tag && 6-tag
如果把字的类型分为四类(4-tag),就是:S(单字),B(词首),M(词中),E(词尾)。
如果把字的类型分成六类(6-tag),就是:S(单字),B(词首),C(第二个字),D(第三个字),M(词中),E(词尾)。
例如:如果【中华人民共和国】作为一个词的话,按照4-tag,描述为:中/B 华/M 人/M 民/M 共/M 和/M 国/E。如果按照6-tag,描述为:中/B 华/C 人/D 民/M 共/M 和/M 国/E。
从这里可以看出,分词问题转化成了一个分类问题,即对每个字分类。我们知道,机器学习方法可以很好地处理分类问题。 所以接下来,我们需要用机器学习的方法来解决分词。本文将分别用4-tag和6-tag对训练语料和测试语料进行标注,利用训练语料求得对应的模型,得到测试语料的分词结果。
机器学习处理问题的基本思想是,首先对标注好的数据进行训练,得到模型,再根据模型对新数据进行预测。这样我们将问题转化为三个子问题:
(1)标注数据是什么?
(2)模型是什么?
(3)如何使用模型进行预测?
具体到以字分词问题,我们简单地回答上述三个问题。
(1)标注好的数据就是:字x在情境A下类别为a;字x在情境B下类别为b;字x在情境C下类别为c……
(2)模型就是:一些公式。这些公式是对数据的一种描述,其中包含了标注好的数据的信息,以及一些未知的参数,对模型的训练就是采用机器学习的方法,赋予未知的参数一些合适的值,这些值使得公式的值达到最优。
(3)如何预测:给定字x,情境Z,我们得到模型后,就可以根据 x,Z,模型,得到在这种情况下x取各个类别的概率是多少,由此可以预测出x的类别。
在上述回答中,有几个地方是没有定义的,例如,什么叫情境。在以字分词中,情境就是对一个字环境的描述,例如在句子我是程序员中,如果我们将一个字的情境定义为:这个字前面的字和这个字后面的字。那么“程”这个字的情境为:“是”,以及“序”。所以,所谓标注好的数据就是:{类别:情境}的集合,我们举例说明。
将C-1定义为字前的字,C0定义为当前字,C1定义为字后的字,那么如果我们有一句分好词的句子:我 是 一名 程序员 。
首先我们需要对每个字打个标签,表示类别:我/S 是/S 一/B 名/E 程/B 序/M 员/E 。/S
然后就可以转化为标注数据了,例如“程”字,可以得到一条标注数据为: B C-1=名 C0=程 C1=序。这条标注数据意思为当遇到C-1=名 C0=程 C1=序这种情境时,类别为B。
所以,由一堆分好词的数据,就可以得到许多条这样的标注数据。得到标注数据后,就可以使用机器学习包进行训练,训练后可以得到相应的模型,预测时导入模型,然后给出相应情境(即C-1=? C0=? C1=?),就可以知道在此情境下各个类别的概率,在此可以简单地 认识哪个类别概率大,结果就是哪个类别,当然,也可以设计其它的方式。
在整个过程中,情境,机器学习方法,预测的方法都是可变的,但是以字分词大概的思想应该都是这样的。
第四部分 分词实践
1.语料来源
数据来自 Bakeoff2005 官方网站:http://sighan.cs.uchicago.edu/bakeoff2005/ 下载其中的 icwb2-data.tar.bz2 解压后取出以下文件:
(1)训练数据:icwb2-data/training/pku_ training.utf8
(2)测试数据:icwb2-data/testing/pku_ test.utf8
(3)正确分词结果:icwb2-data/gold/pku_ test_ gold.utf8
(4)评分工具:icwb2-data/script/socre
2.分词过程数据示例
注:下面展示的仅仅是数据示例,并非完整的数据
(1)训练语料

(2)训练语料的字标注结果

(3)训练语料的特征

其中,Ci 表示与当前字偏移为i的字
(4)测试语料

(5)测试语料的特征

(6)测试语料的字标注结果
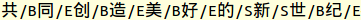
(7)测试语料的分词结果
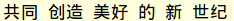
3.计算准确率和召回率以及F值
有了这个字标注分词结果,我们就可以利用backoff2005的测试脚本来测一下这次分词的效果了:
./icwb2-data/scripts/score ./icwb2-data/gold/pku_training_words.utf8 ./icwb2-data/gold/pku_test_gold.utf8 pku_result.utf8 > pku_maxent.score
其中,pku_result.utf8 是你的结果文件,pku_maxent.score是你指定的存放评分结果的文件名
第五部分 分词结果
下面是测试结果:
| 类别 | 迭代次数 | 真实词数 | 得到词数 | 召回率 | 准确率 | F值 |
| 4-tag | 100 | 104372 | 102810 | 89.40% | 90.70% | 0.9 |
| 4-tag | 150 | 104372 | 102806 | 89.40% | 90.80% | 0.901 |
| 4-tag | 200 | 104372 | 102808 | 89.50% | 90.80% | 0.901 |
| 6-tag | 100 | 104372 | 103246 | 91.00% | 92.00% | 0.915 |
| 6-tag | 150 | 104372 | 103240 | 91.00% | 92.00% | 0.915 |
| 6-tag | 200 | 104372 | 103237 | 91.10% | 92.10% | 0.915 |
| 6-tag | 300 | 104372 | 103212 | 91.10% | 92.10% | 0.916 |
从结果来看,6-tag的结果要优于4-tag的结果。最高值为:召回率91.1%,准确率92.1,F值为0.916。
第六部分 源代码
#! /usr/bin/env python
# -*- coding: utf-8 -*-
# 基于最大熵模型及字标注的分词工具4-tag && 6-tag
import codecs
import sys
from maxent import MaxentModel
# 标注训练集6-tag
def tag6_training_set(training_file, tag_training_set_file):
fin = codecs.open(training_file, 'r', 'utf-8')
contents = fin.read()
contents = contents.replace(u'\r', u'')
contents = contents.replace(u'\n', u'')
words = contents.split(' ')
print len(words)
tag_words_list = []
i = 0
for word in words:
i += 1
if(i % 100 == 0):
tag_words_list.append(u'\r')
if(len(word) == 0):
continue
if(len(word) == 1):
tag_word = word + '/S'
elif (len(word) == 2):
tag_word = word[0] + '/B' + word[1] + '/E'
elif (len(word) == 3):
tag_word = word[0] + '/B' + word[1] + '/C' + word[2] + '/E'
elif (len(word) == 4):
tag_word = word[0] + '/B' + word[1] + '/C' + word[2] + '/D' + word[3] + '/E'
else:
tag_word = word[0] + '/B' + word[1] + '/C' + word[2] + '/D'
mid_words = word[3:-1]
for mid_word in mid_words:
tag_word += (mid_word + '/M')
tag_word += (word[-1] + '/E')
tag_words_list.append(tag_word)
tag_words = ''.join(tag_words_list)
fout = codecs.open(tag_training_set_file, 'w', 'utf-8')
fout.write(tag_words)
fout.close()
return (words, tag_words_list)
# 标注训练集4-tag
def tag4_training_set(training_file, tag_training_set_file):
fin = codecs.open(training_file, 'r', 'utf-8')
contents = fin.read()
contents = contents.replace(u'\r', u'')
contents = contents.replace(u'\n', u'')
words = contents.split(' ')
print len(words)
tag_words_list = []
i = 0
for word in words:
i += 1
if(i % 100 == 0):
tag_words_list.append(u'\r')
if(len(word) == 0):
continue
if(len(word) == 1):
tag_word = word + '/S'
elif (len(word) == 2):
tag_word = word[0] + '/B' + word[1] + '/E'
else:
tag_word = word[0] + '/B' + word[1] + '/C' + word[2] + '/D'
mid_words = word[1:-1]
for mid_word in mid_words:
tag_word += (mid_word + '/M')
tag_word += (word[-1] + '/E')
tag_words_list.append(tag_word)
tag_words = ''.join(tag_words_list)
fout = codecs.open(tag_training_set_file, 'w', 'utf-8')
fout.write(tag_words)
fout.close()
return (words, tag_words_list)
def get_near_char(contents, i, times):
words_len = len(contents) / times;
if (i < 0 or i > words_len - 1):
return '_'
else:
return contents[i*times]
def get_near_tag(contents, i ,times):
words_len = len(contents) / times;
if (i < 0 or i > words_len - 1):
return '_'
else:
return contents[i*times*2]
def isPu(char):
punctuation = [u',', u'。', u'?', u'!', u';', u'--', u'、', u'——', u'(', u')', u'《', u'》', u':', u'“', u'”', u'’', u'‘']
if char in punctuation:
return '1'
else:
return '0'
def get_class(char):
zh_num = [u'零', u'○', u'一', u'二', u'三', u'四', u'五', u'六', u'七', u'八', u'九', u'十', u'百', u'千', u'万']
ar_num = [u'0', u'1', u'2', u'3', u'4', u'5', u'6', u'7', u'8', u'9', u'.', u'0',u'1',u'2',u'3',u'4',u'5',u'6',u'7',u'8',u'9']
date = [u'日', u'年', u'月']
letter = ['a', 'b', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'g', 'k', 'l', 'm', 'n', 'o', 'p', 'q', 'r', 's', 't', 'u', 'v', 'w', 'x', 'y', 'z', 'A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'I', 'J', 'K', 'L', 'M', 'N', 'O', 'P', 'Q', 'R', 'S', 'T', 'U', 'V', 'W', 'X', 'Y', 'Z']
if char in zh_num or char in ar_num:
return '1'
elif char in date:
return '2'
elif char in letter:
return '3'
else:
return '4'
# 获取训练集特征
def get_event(tag_file_path, event_file_path):
f = codecs.open(tag_file_path, 'r', 'utf-8')
contents = f.read()
contents = contents.replace(u'\r', u'')
contents = contents.replace(u'\n', u'')
words_len = len(contents)/3
event_list = []
index = range(0, words_len)
for i in index:
pre_char = get_near_char(contents, i-1, 3)
pre_pre_char = get_near_char(contents, i-2, 3)
cur_char = get_near_char(contents, i, 3)
next_char = get_near_char(contents, i+1, 3)
next_next_char = get_near_char(contents, i+2, 3)
event_list.append(
contents[i*3+2] + ' '
+ 'C-2='+pre_pre_char + ' ' + 'C-1='+pre_char + ' '
+ ' ' + 'C0=' + cur_char + ' '
+ 'C1=' + next_char + ' ' + 'C2=' + next_next_char + ' '
+ 'C-2=' + pre_pre_char + 'C-1=' + pre_char + ' '
+ 'C-1=' + pre_char + 'C0=' + cur_char + ' '
+ 'C0=' + cur_char + 'C1=' + next_char + ' '
+ 'C1=' + next_char + 'C2=' + next_next_char + ' '
+ 'C-1=' + pre_char + 'C1=' + next_char + ' '
+ 'C-2=' + pre_pre_char + 'C-1=' + pre_char + 'C0=' + cur_char + ' '
+ 'C-1=' + pre_char + 'C0=' + cur_char + 'C1=' + next_char + ' '
+ 'C0=' + cur_char + 'C1=' + next_char + 'C2=' + next_next_char + ' '
+ 'Pu=' + isPu(cur_char) + ' '
+ 'Tc-2=' + get_class(pre_pre_char) + 'Tc-1=' + get_class(pre_char)
+ 'Tc0=' + get_class(cur_char) + 'Tc1=' + get_class(next_char)
+ 'Tc2=' + get_class(next_next_char) + ' '
+ '\r')
# events = ''.join(event_list)
fout = codecs.open(event_file_path, 'w', 'utf-8')
for event in event_list:
fout.write(event)
fout.close()
return event_list
# 测试集生成特征
def get_feature(test_file_path, feature_file_path):
f = codecs.open(test_file_path, 'r', 'utf-8')
contents = f.read()
contents_list = contents.split('\r\n')
contents_list.remove('')
contents_list.remove('')
fout = codecs.open(feature_file_path, 'w', 'utf-8')
for line in contents_list:
words_len = len(line)
feature_list = []
index = range(0, words_len)
for i in index:
pre_char = get_near_char(line, i-1, 1)
pre_pre_char = get_near_char(line, i-2, 1)
cur_char = get_near_char(line, i, 1)
next_char = get_near_char(line, i+1, 1)
next_next_char = get_near_char(line, i+2, 1)
feature_list.append(
'C-2=' + pre_pre_char + ' ' + 'C-1=' + pre_char + ' '
+ 'C0=' + cur_char + ' '
+ 'C1=' + next_char + ' ' + 'C2=' + next_next_char + ' '
+ 'C-2=' + pre_pre_char + 'C-1=' + pre_char + ' '
+ 'C-1=' + pre_char + 'C0=' + cur_char + ' '
+ 'C0=' + cur_char + 'C1=' + next_char + ' '
+ 'C1=' + next_char + 'C2=' + next_next_char + ' '
+ 'C-1=' + pre_char + 'C1=' + next_char + ' '
+ 'C-2=' + pre_pre_char + 'C-1=' + pre_char + 'C0=' + cur_char + ' '
+ 'C-1=' + pre_char + 'C0=' + cur_char + 'C1=' + next_char + ' '
+ 'C0=' + cur_char + 'C1=' + next_char + 'C2=' + next_next_char + ' '
+ 'Pu=' + isPu(cur_char) + ' '
+ 'Tc-2=' + get_class(pre_pre_char) + 'Tc-1=' + get_class(pre_char)
+ 'Tc0=' + get_class(cur_char) + 'Tc1=' + get_class(next_char)
+ 'Tc2=' + get_class(next_next_char) + ' '
+ '\r')
for item in feature_list:
fout.write(item)
fout.write('split\r\n')
fout.close()
return feature_list
#
def split_by_blank(line):
line_list = []
line_len = len(line)
i = 0
while i < line_len:
line_list.append(line[i])
i += 2
return line_list
# 训练模型
def training(feature_file_path, trained_model_file, times):
m = MaxentModel()
fin = codecs.open(feature_file_path, 'r', 'utf-8')
all_list = []
m.begin_add_event()
for line in fin:
line = line.rstrip()
line_list = line.split(' ')
str_list = []
for item in line_list:
str_list.append(item.encode('utf-8'))
all_list.append(str_list)
m.add_event(str_list[1:], str_list[0], 1)
m.end_add_event()
print 'begin training'
m.train(times, "lbfgs")
print 'end training'
m.save(trained_model_file)
return all_list
#
def max_prob(label_prob_list):
max_prob = 0
max_prob_label = ''
for label_prob in label_prob_list:
if label_prob[1] > max_prob:
max_prob = label_prob[1]
max_prob_label = label_prob[0]
return max_prob_label
# 标注测试集
def tag_test(test_feature_file, trained_model_file, tag_test_set_file):
fin = codecs.open(test_feature_file, 'r', 'utf-8')
fout = codecs.open(tag_test_set_file, 'w', 'utf-8')
m = MaxentModel()
m.load(trained_model_file)
contents = fin.read()
feature_list = contents.split('\r')
feature_list.remove('\n')
for feature in feature_list:
if (feature == 'split'):
fout.write('\n\n\n')
continue
str_feature = []
u_feature = feature.split(' ')
for item in u_feature:
str_feature.append(item.encode('utf-8'))
label_prob_list = m.eval_all(str_feature)
label = max_prob(label_prob_list)
try:
new_tag = str_feature[2].split('=')[1] + '/' + label
except IndexError:
print str_feature
fout.write(new_tag.decode('utf-8'))
pre_tag = label
return feature_list
# 获取最终结果6-tag
def tag6_to_words(tag_training_set_file, result_file):
fin = codecs.open(tag_training_set_file, 'r', 'utf-8')
fout = codecs.open(result_file, 'w', 'utf-8')
contents = fin.read()
words_len = len(contents) / 3
result = []
i = 0
while (i < words_len):
cur_word_label = contents[i*3+2]
cur_word = contents[i*3]
if (cur_word_label == 'S'):
result.append(cur_word + ' ')
elif (cur_word_label == 'B'):
result.append(cur_word)
elif (cur_word_label == 'C'):
result.append(cur_word)
elif (cur_word_label == 'D'):
result.append(cur_word)
elif (cur_word_label == 'M'):
result.append(cur_word)
elif (cur_word_label == 'E'):
result.append(cur_word + ' ')
else:
result.append(cur_word)
i += 1
fout.write(''.join(result))
# 获取最终结果4-tag
def tag4_to_words(tag_training_set_file, result_file):
fin = codecs.open(tag_training_set_file, 'r', 'utf-8')
fout = codecs.open(result_file, 'w', 'utf-8')
contents = fin.read()
words_len = len(contents) / 3
result = []
i = 0
while (i < words_len):
cur_word_label = contents[i*3+2]
cur_word = contents[i*3]
if (cur_word_label == 'S'):
result.append(cur_word + ' ')
elif (cur_word_label == 'B'):
result.append(cur_word)
elif (cur_word_label == 'M'):
result.append(cur_word)
elif (cur_word_label == 'E'):
result.append(cur_word + ' ')
else:
result.append(cur_word)
i += 1
fout.write(''.join(result))
#
def main():
args = sys.argv[1:]
if len(args) < 3:
print 'Usage: python ' + sys.argv[0] + ' training_file test_file result_file'
exit(-1)
training_file = args[0]
test_file = args[1]
result_file = args[2]
# 标注训练集
tag_training_set_file = training_file + ".tag"
#tag4_training_set(training_file, tag_training_set_file)
tag6_training_set(training_file, tag_training_set_file)
print 'tag train set succeed'
# 获取训练集特征
feature_file_path = training_file + ".feature"
get_event(tag_training_set_file, feature_file_path)
print 'get training set feature succeed'
# 测试集生成特征
test_feature_file = test_file + ".feature"
get_feature(test_file, test_feature_file)
print 'get test set features succeed'
# 训练模型
times = [10]
for time in times:
trained_model_file = training_file + '.' + str(time) + ".model"
training(feature_file_path, trained_model_file, time)
print 'training model succeed: ' + str(time)
# 标注测试集
tag_test_set_file = test_file + ".tag"
tag_test(test_feature_file, trained_model_file, tag_test_set_file)
print 'tag test set succeed'
# 获取最终结果
#tag4_to_words(tag_test_set_file, result_file + '.' + str(time))
tag6_to_words(tag_test_set_file, result_file + '.' + str(time))
print 'get final result succeed ' + result_file + '.' + str(time)
'''
def main():
args = sys.argv[1:]
if len(args) < 3:
print 'Usage: python ' + sys.argv[0] + ' trainen_model_file test_file result_file'
exit(-1)
trained_model_file = args[0]
test_file = args[1]
result_file = args[2]
# 测试集生成特征
test_feature_file = test_file + ".feature"
get_feature(test_file, test_feature_file)
print 'get test set features succeed'
# 训练模型
times = [10]
for time in times:
#trained_model_file = training_file + '.' + str(time) + ".model"
#training(feature_file_path, trained_model_file, time)
#print 'training model succeed: ' + str(time)
# 标注测试集
tag_test_set_file = test_file + ".tag"
tag_test(test_feature_file, trained_model_file, tag_test_set_file)
print 'tag test set succeed'
# 获取最终结果
tag_to_words(tag_test_set_file, result_file + '.' + str(time))
print 'get final result succeed ' + result_file + '.' + str(time)
'''
if __name__ == "__main__":
main()
参考资料:
本文测试过程主要参考了下面的文章:
【1】使用Python,字标注及最大熵法进行中文分词http://blog.csdn.net/on_1y/article/details/9769919















 3799
3799

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









