






先来理解 the element of statistic learning 的公式 5.6。
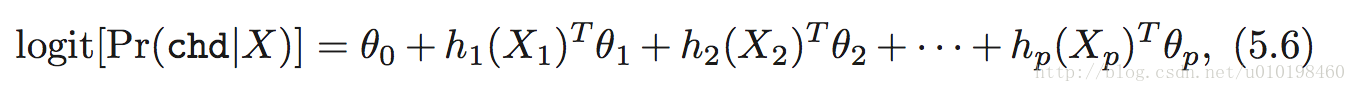
其中X1,X2 表示的是不同的预测变量。例如X1代表sbp。。。等 。
用自然三次样条基函数来拟合逻辑回归。那么h1(X1) 就包含四个基函数。同理,h2(X2)也是包含四个。
书上图5.4 可以按照以下R代码画出来,如下:
library(splines) #首先,引入样条库
SAheart <- read.csv("SAheart.data")#读入数据
attach(SAheart)
sbp.grid=seq(from=range(sbp)[1],to=range(sbp)[2])#为了便于画拟合图,把sbp预测变量分成多个小段。
fit =glm(chd~ns(sbp,df=4),data=SAheart,family=binomial)# 用自然样条基函数,来拟合逻辑回归。这样逻辑回归就有非线性的表达能力了。
pred=predict(fit,newdata=list(sbp=sbp.grid),se=T)# 预测sbp的对应的 chd值。
plot(sbp,chd,ylim=range(-2.5,5),type="n")#把预测的结果画出来
lines(sbp.grid,pred$fit,col="red",lwd=2)#
lines(sbp.grid,pred$fit+2*pred$se,col="green",lwd=2,lty="dashed")#画上相应的置信区间。
lines(sbp.grid,pred$fit-2*pred$se,col="green",lwd=2,lty="dashed")
书上的表5.1可以按照如下代码给出。结果很类似。
form = "chd ~ ns(sbp,df=4) + ns(tobacco,df=4) + ns(ldl,df=4) + famhist + ns(obesity,df=4) + ns(alcohol,df=4) + ns(age,df=4)"
form = formula(form)
m = glm( form, data=SAheart, family=binomial )
print( summary(m), digits=3 )
# Duplicates the numbers from Table 5.1:
#
drop1( m, scope=form, test="Chisq" )
下面来看5.2.3音素识别的例子。首先给出画出图5.5的代码
library(ElemStatLearn) #
aa_spot = phoneme$g == "aa"
ao_spot = phoneme$g == "ao"
aa_indx = which( aa_spot )
ao_indx = which( ao_spot )
AA_data = phoneme[ aa_indx[1:15], 1:256 ]
AO_data = phoneme[ ao_indx[1:15], 1:256 ]#提取出两个音素aa 和ao的数据,256个频率上的15个对数周期。
min_l = min( c( min( AA_data ), min( AO_data ) ) )
max_l = max( c( max( AA_data ), max( AO_data ) ) )#给出y坐标轴的大小。
ii=1
plot( as.double(AA_data[ii,]), ylim=c(min_l,max_l), type="l", col="green", xlab="Frequency", ylab="Log-periodogram" )#先画第一个元素
for( ii in 2:dim(AA_data)[1] ){
lines( as.double(AA_data[ii,]), col="green" )
}
for( ii in 1:dim(AO_data)[1] ){
lines( as.double(AO_data[ii,]), col="orange" )
}#和书上的结果一致。
把256个对数周期值作为输入,来预测音素aa 还是ao
AA_data = phoneme[ aa_indx, ]
train_inds = grep( "^train", AA_data$speaker )
test_inds = grep( "^test", AA_data$speaker )
AA_data_train = AA_data[ train_inds, 1:256 ]
AA_data_test = AA_data[ test_inds, 1:256 ]# 把 aa分为训练集和测试集两类。输入变量有256个,预测变量为1个。
n_aa = dim(AA_data_train)[1]
AA_data_train$Y = rep( 1, n_aa )
n_aa = dim(AA_data_test)[1]
AA_data_test$Y = rep( 1, n_aa )#把响应变量编码为1.同样分为训练集和测试集
#同理,处理音素ao,编码为0
AO_data = phoneme[ ao_indx, ]
train_inds = grep( "^train", AO_data$speaker )
test_inds = grep( "^test", AO_data$speaker )
AO_data_train = AO_data[ train_inds, 1:256 ]
AO_data_test = AO_data[ test_inds, 1:256 ]
n_ao = dim(AO_data_train)[1]
AO_data_train$Y = rep( 0, n_ao ) # call this class 0
n_ao = dim(AO_data_test)[1]
AO_data_test$Y = rep( 0, n_ao )
DT_train = rbind( AA_data_train, AO_data_train )
DT_test = rbind( AA_data_test, AO_data_test )
#然后利用利用训练集的数据训练模型。
form = paste( "Y ~", paste( colnames( DT_train )[1:256], collapse="+" ) )
m = glm( form, family=binomial, data=DT_train )
mc = as.double( coefficients(m) )
plot( mc, ylim=c(-0.4,+0.4), type="l", xlab="Frequency", ylab="Logistic Regression Coefficients" ) #把相应的系数画出来。
Y_hat_train = predict( m, DT_train[,1:256], type="response" )
predicted_class_label_train = as.double( Y_hat_train > 0.5 )
Y_hat_test = predict( m, DT_test[,1:256], type="response" )
predicted_class_label_test = as.double( Y_hat_test > 0.5 )
err_rate_train = mean( DT_train[,257] != predicted_class_label_train )
err_rate_test = mean( DT_test[,257] != predicted_class_label_test )
print( sprintf('Logistic Regression: err_rate_train= %10.6f; err_rate_test= %10.5f', err_rate_train, err_rate_test) )
根据训练集和测试集的结果预测 训练集上的错误率为0.093114,测试集上的错误率为 0.24374。和书上的结果差不多。
我们从图中可以看到,系数随着频率的变化很剧烈。因此希望能够借助正则化的方法来光滑系数。光滑的系数不仅更容易解释,而且分类的结果更好。
因此书中采用样条插值的方法来光滑系数。(注意这里插值的作用是光滑系数,而不是光滑预测值。)
按照书上的说法,可以采用一个基函数来过滤输入空间X,即X*=t(H)X. 然后在X* 上执行上述的逻辑回归代码。这样估算出来的参数为theta_hat。然后theta_hat再乘上基函数 即得到估算的系数beta(平滑过后的)。结果显示,测试集上的错误率为0.158左右。比直接拟合要好9个点。
但是上述方法并没有试过,以后实现了,再把代码贴上来。
然后5.3节 说明这种特征过滤的方法很常用,也很有效,信号处理的时候经常用的着。















 7225
7225

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









