






在设计分类器的时候,经常需要降低特征的数量,一方面是为了降低计算复杂度,另一方面可以使得分类器更具有通用性。
为了简便处理,很多时候需要假定特征之间是相互独立的。这里先介绍如何利用单个特征进行分类,主要介绍两种度量方法来衡量特征的可分性。
1, 对数据特征进行基于统计的假设检验。
比如针对单个特征,检查该特征是否具有可分性。即该特征在两个类中的均值是否相等。如果假定该特征服从正态分布,并且方差相等,则可用t检验。如果方差不等,用F检验。
如果该特征不服从正态分布,可采用其他标准,如Kruskal-Wallis统计等,具体问题具体分析。
2,根据ROC曲线来判断类的可分性。如果某两个类的可分性很强,那么它们的ROC曲线下方的面积会很大。
利用单个特征进行分类,没有充分考虑各特征之间的相关性,而特征的相关性会影响多个特征组合的分类能力。下面介绍如何同时选取多个特征向量。
在介绍特征向量选取之前,需要介绍基于多特征类可分性的度量方法。
1,发散性(divergence)。
当采用特征向量X时,两类之间的发散性定义为

用平均发散性计算平均的类可分性
发散性的定义不仅取决于均值,还取决于方差,也就是说即便两个类的均值是一样的,如果方差不同,发散性依然可以把两类区分开。一般使用发散性的时候会做一个变换

这主要是为了解决发散性对不同均值向量依赖性问题,不深究。
发散性的定义有个问题,就是当类分布不是正态分布时,不好计算,因此有必要采用一些简单的准则。
2,定义类内散布矩阵和类间散布矩阵如下:
计算准则定义为
该值越大,说明类的可分性越好。
下面进入问题的关键,如何从M个特征中,找出L个,作为子集。可分为两类介绍。
一,采用标量的方法
1,特征被单独处理,采用上面介绍的任意一个分类度量标准ROC,一维发散性,FDR等。计算每一个特征的测量值,排序然后选出最好的那个。
2,为了选出第二好的,把最好的那个和剩下的M-1个计算相关系数。
3,选出
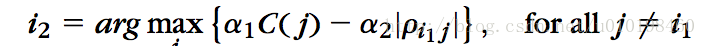
其中alpha(1,2)分别为两项重要性的权重。
4,依次类推,后面的选择公式为
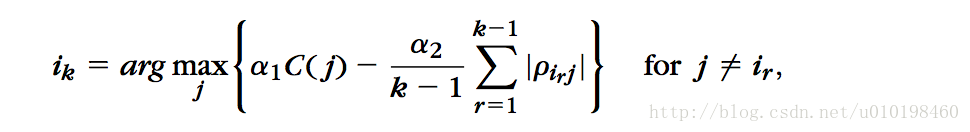
即考虑所有已选择特征的平均相关性。
上述过程有多个变体,fine 83中采用了多个准则来改进该过程,有兴趣可参考之。
[Fine83] FinetteS.,BleierA.,SwindelW.“Breasttissueclassificationusingdiagnosticultrasoundand pattern recognition techniques: I. Methods of pattern recognition,”Ultrasonic Imaging,Vol. 5, pp. 55–70, 1983.
二:采用向量的方法
采用标量的方法优点是计算简单,但是对于复杂问题和高相关性的特征效果不好。下面介绍基于向量的方法。
1,前向,后向,双向搜索。假定有4个特征,我们希望从中选两个。后向搜索过程如下: 先计算4个特征的分类准则C,然后计算4个特征中,所有3种组合的分类准则。选择一个最好的。例如为(1,2,3)。然后对这三个再计算两两组合,从中找到一个最好的。
前向和双向的过程类似,不赘述。
这是一个次优的方法,因为每踢掉一个变量,就不会把它加进来。浮动搜索技术可以改进这个方法。
具体可见
Pudi94] PudilP.,NovovicovaJ.,KittlerJ.“Floatingsearchmethodsinfeatureselection,”PatternRecognition Letters,Vol. 15, pp. 1119–1125, 1994.
还有一些基于决策树或随机森林的特征选择方法,后面会另文介绍。















 598
598

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









