







1.背景
目前,很多应用中都因为用了多任务取得了不错的效果,那么如何将这些任务的loss有机组合在一起?
一种简答粗暴方法就是手动调节多任务之间的loss的相对权重,然后加和,如下:
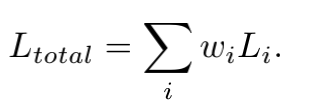
这种方式把权重作为超参调试的方式,往往耗时耗力。
本文参考[1]就如何动态设置多任务(分类与回归)之间的loss的相对权重做简单介绍。
2.解决方案
在贝叶斯建模中,认为模型有一些不确定性(随机变量),可能是先验问题导致的,也有可能是后验问题导致的,大体可将其分为两种,如下:
- 认知不确定性:数据不足导致的模型学习不足的不确定性,比如:小学生去参加高考,很多知识都没学过,自然考不好。
- 偶然不确定性:噪声导致的不确定性
偶然不确定性又分为:
- 数据依赖不确定性(异方差):输入数据的不确定性,导致输出不确定,比如:小明学习使用的教材部分有问题,导致小明考试考不到高分。
- 任务依赖不确定性(同方差):不同任务自身的学习能力的不同,导致学习结果不确定性。比如:小明为了提高成绩,一方面努力学习知识概念,另一方面猛做练习题,他们都有各自的优势,但是也都有一定的局限性。
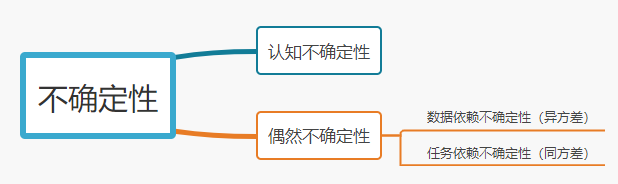
其中,同方差 指的是假定数据输入一定的情况下,真实的分布与任务的输出之间有一个恒定的方差。
解决方案为什么考虑的用贝叶斯NN?贝叶斯建模中的不确定性能够表示不同任务之间的难易程度,能够很好的为任务的输出f,真实分布y以及方差δ之间建模。
动态loss权重就是考虑在同方差条件下,接下来我们如何建模展开。
3 建模
假设输入为 X X X,参数矩阵为 W W W,输出为 f W ( x ) f^W(x) fW(x),真实分布为 y y y。
3.1 回归任务
对于回归任务,在给定其输出
f
W
(
x
)
f^W(x)
fW(x)的情况下
y
y
y的概率为高斯似然:
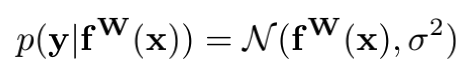
(对于高斯似然,
σ
σ
σ为模型的观测噪声参数,表示输出数据中的噪声量)
将
f
W
(
x
)
f^W(x)
fW(x)和
y
y
y代入上述高斯函数中,可得:
p
(
y
∣
f
W
(
x
)
)
=
1
2
π
σ
e
−
(
y
−
f
W
(
x
)
)
2
2
σ
2
p(y|f^W(x))=\frac{1}{\sqrt{2\pi}\sigma}e^{-\frac{(y-f^W(x))^2}{2\sigma^2}}
p(y∣fW(x))=2πσ1e−2σ2(y−fW(x))2
两边求对数,可得其对数似然函数,如下:
l o g p ( y ∣ f W ( x ) ) ∝ − ( y − f W ( x ) ) 2 2 σ 2 − l o g σ logp(y|f^W(x))\propto-\frac{(y-f^W(x))^2}{2\sigma^2}-log\sigma logp(y∣fW(x))∝−2σ2(y−fW(x))2−logσ
3.2 分类任务
对于分类任务,为了建立起与 σ σ σ的关系,其概率描述为softmax的一种更为普遍的表示形式Boltzmann分布,也叫吉布斯分布:
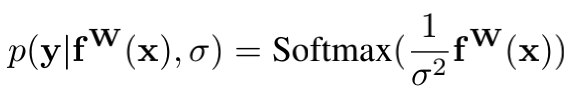
系数 σ σ σ可以是设定的,也可以是通过学习得到的,决定离散分布的平坦程度。该值和分布的不确定性(熵)有关。
同理,将
f
W
(
x
)
f^W(x)
fW(x)和
y
y
y代入上述softmax函数中,可得对数似然函数,如下:
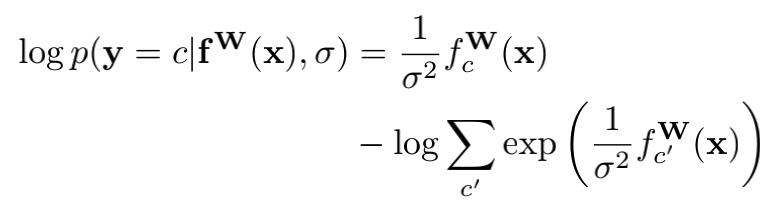
其中,c为某一类别
3.3 多任务
对于回归与分类任务混合的多任务似然,假定
y
1
y_1
y1、…、
y
k
y_k
yk分别为回归任务和分类任务的真实输出,其似然为:
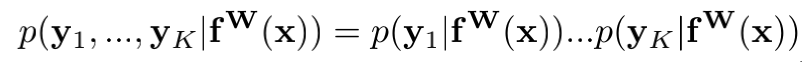
那么,假设多任务的loss记作
L
(
W
,
σ
1
,
σ
2
)
L(W,\sigma_1 ,\sigma_2 )
L(W,σ1,σ2),那么则有:
=
L
(
W
,
σ
1
,
σ
2
)
L(W,\sigma_1 ,\sigma_2 )
L(W,σ1,σ2)
=
−
l
o
g
N
(
y
1
;
f
W
(
x
)
,
σ
1
2
)
⋅
s
o
f
t
m
a
x
(
y
2
=
c
;
f
W
(
x
)
,
σ
2
)
-logN(y_1;f^W(x),\sigma ^2_1)\cdot softmax(y_2=c;f^W(x),\sigma _2)
−logN(y1;fW(x),σ12)⋅softmax(y2=c;fW(x),σ2)
=
1
2
σ
1
2
∥
y
1
−
f
W
(
x
)
∥
2
+
l
o
g
σ
1
−
l
o
g
p
(
y
2
=
c
∣
f
W
(
x
)
,
σ
2
)
\frac{1}{2\sigma ^2_1}\left \| y_1 - f^W(x) \right \|^2 + log\sigma_1 - logp(y_2=c|f^W(x),\sigma_2)
2σ121
y1−fW(x)
2+logσ1−logp(y2=c∣fW(x),σ2)
=
1
2
σ
1
2
∥
y
1
−
f
W
(
x
)
∥
2
+
l
o
g
σ
1
−
1
σ
2
2
f
c
′
W
(
x
)
+
l
o
g
∑
c
′
e
1
σ
2
2
f
c
′
W
(
x
)
\frac{1}{2\sigma ^2_1}\left \| y_1 - f^W(x) \right \|^2 + log\sigma_1 - \frac{1}{\sigma_2^2}f_{c{'}}^W(x)+log\sum_{c{'}}e^{\frac{1}{\sigma^2_2}{f_{c{'}}^W(x)}}
2σ121
y1−fW(x)
2+logσ1−σ221fc′W(x)+log∑c′eσ221fc′W(x)
=
1
2
σ
1
2
∥
y
1
−
f
W
(
x
)
∥
2
+
l
o
g
σ
1
+
1
σ
2
2
l
o
g
∑
c
′
e
f
c
′
W
(
x
)
−
1
σ
2
2
f
c
′
W
(
x
)
+
l
o
g
∑
c
′
e
1
σ
2
2
f
c
′
W
(
x
)
−
1
σ
2
2
l
o
g
∑
c
′
e
f
c
′
W
(
x
)
\frac{1}{2\sigma ^2_1}\left \| y_1 - f^W(x) \right \|^2 + log\sigma_1 + \frac{1}{\sigma ^2_2}log\sum_{c{'}}e^{f_{c{'}}^W(x)} - \frac{1}{\sigma_2^2}f_{c{'}}^W(x)+ log\sum_{c{'}}e^{\frac{1}{\sigma^2_2}{f_{c{'}}^W(x)}}- \frac{1}{\sigma ^2_2}log\sum_{c{'}}e^{f_{c{'}}^W(x)}
2σ121
y1−fW(x)
2+logσ1+σ221log∑c′efc′W(x)−σ221fc′W(x)+log∑c′eσ221fc′W(x)−σ221log∑c′efc′W(x)
=
1
2
σ
1
2
∥
y
1
−
f
W
(
x
)
∥
2
+
l
o
g
σ
1
−
1
σ
2
2
l
o
g
s
o
f
t
m
a
x
(
y
2
,
f
W
(
x
)
)
+
l
o
g
∑
c
′
e
1
σ
2
2
f
c
′
W
(
x
)
−
1
σ
2
2
l
o
g
∑
c
′
e
f
c
′
W
(
x
)
\frac{1}{2\sigma ^2_1}\left \| y_1 - f^W(x) \right \|^2 +log\sigma_1 - \frac{1}{\sigma_2^2}log \ softmax(y_2,f^W(x))+ log\sum_{c{'}}e^{\frac{1}{\sigma^2_2}{f_{c{'}}^W(x)}}- \frac{1}{\sigma ^2_2}log\sum_{c{'}}e^{f_{c{'}}^W(x)}
2σ121
y1−fW(x)
2+logσ1−σ221log softmax(y2,fW(x))+log∑c′eσ221fc′W(x)−σ221log∑c′efc′W(x)
=
1
2
σ
1
2
∥
y
1
−
f
W
(
x
)
∥
2
+
l
o
g
σ
1
−
1
σ
2
2
l
o
g
s
o
f
t
m
a
x
(
y
2
,
f
W
(
x
)
)
+
l
o
g
∑
c
′
e
1
σ
2
2
f
c
′
W
(
x
)
(
∑
c
′
e
f
c
′
W
(
x
)
)
1
σ
2
2
\frac{1}{2\sigma ^2_1}\left \| y_1 - f^W(x) \right \|^2 +log\sigma_1 - \frac{1}{\sigma_2^2}log \ softmax(y_2,f^W(x)) + log\frac{\sum_{c{'}}e^{\frac{1}{\sigma^2_2}{f_{c{'}}^W(x)}}}{(\sum_{c{'}}e^{f_{c{'}}^W(x)})^\frac{1}{\sigma_2^2}}
2σ121
y1−fW(x)
2+logσ1−σ221log softmax(y2,fW(x))+log(∑c′efc′W(x))σ221∑c′eσ221fc′W(x)
由于当
σ
2
\sigma_2
σ2->1时,有
1
σ
2
∑
c
′
e
1
σ
2
2
f
c
′
W
(
x
)
\frac{1}{\sigma_2}\sum_{c{'}}e^{\frac{1}{\sigma^2_2} {f_{c{'}}^W(x)}}
σ21∑c′eσ221fc′W(x)≈
(
∑
c
′
e
1
σ
2
2
f
c
′
W
(
x
)
)
1
σ
2
(\sum_{c{'}}e^{\frac{1}{\sigma^2_2}{f_{c{'}}^W(x)}})^\frac{1}{\sigma_2}
(∑c′eσ221fc′W(x))σ21,
所以上式最后一个
l
o
g
∑
c
′
e
1
σ
2
2
f
c
′
W
(
x
)
(
∑
c
′
e
f
c
′
W
(
x
)
)
1
σ
2
2
≈
l
o
g
σ
2
log\frac{\sum_{c{'}}e^{\frac{1}{\sigma^2_2}{f_{c{'}}^W(x)}}}{(\sum_{c{'}}e^{f_{c{'}}^W(x)})^\frac{1}{\sigma_2^2}} \approx log\sigma_2
log(∑c′efc′W(x))σ221∑c′eσ221fc′W(x)≈logσ2,
则有:
L
(
W
,
σ
1
,
σ
2
)
L(W,\sigma_1 ,\sigma_2 )
L(W,σ1,σ2) ≈
1
2
σ
1
2
∥
y
1
−
f
W
(
x
)
∥
2
+
l
o
g
σ
1
−
1
σ
2
2
l
o
g
s
o
f
t
m
a
x
(
y
2
,
f
W
(
x
)
)
+
l
o
g
σ
2
\frac{1}{2\sigma ^2_1}\left \| y_1 - f^W(x) \right \|^2 +log\sigma_1 - \frac{1}{\sigma_2^2}log \ softmax(y_2,f^W(x)) + log\sigma_2
2σ121
y1−fW(x)
2+logσ1−σ221log softmax(y2,fW(x))+logσ2
令
L
1
(
W
)
=
∥
y
1
−
f
W
(
x
)
∥
2
L_1(W)=\left \| y_1 - f^W(x) \right \|^2
L1(W)=
y1−fW(x)
2为回归问题的loss,
L
2
(
W
)
=
−
l
o
g
(
s
o
f
t
m
a
x
(
y
2
,
f
W
(
x
)
)
)
L_2(W)=-log(softmax(y_2,f^W(x)))
L2(W)=−log(softmax(y2,fW(x)))为分类问题的loss,则有多任务loss为:
L ( W , σ 1 , σ 2 ) L(W,\sigma_1 ,\sigma_2 ) L(W,σ1,σ2) ≈ 1 2 σ 1 2 L 1 ( W ) + l o g σ 1 + 1 σ 2 2 L 2 ( W ) + l o g σ 2 \frac{1}{2\sigma ^2_1}L_1(W)+log\sigma_1 + \frac{1}{\sigma_2^2}L_2(W)+ log\sigma_2 2σ121L1(W)+logσ1+σ221L2(W)+logσ2
4.代码实现
实际实现中,为了防止分母出现0,提升数值的稳定性以及简化计算,回归loss的系数去掉了 1 2 \frac{1}{2} 21,如下:
L ( W , σ 1 , σ 2 ) L(W,\sigma_1 ,\sigma_2 ) L(W,σ1,σ2) ≈ 1 σ 1 2 L 1 ( W ) + 1 σ 2 2 L 2 ( W ) + 2 l o g σ 1 + 2 l o g σ 2 \frac{1}{\sigma ^2_1}L_1(W) + \frac{1}{\sigma_2^2}L_2(W)+2log\sigma_1+ 2log\sigma_2 σ121L1(W)+σ221L2(W)+2logσ1+2logσ2
并且,一般令 s = l o g σ 2 s=log\sigma^2 s=logσ2,上式可以化简为:
L ( W , σ 1 , σ 2 ) L(W,\sigma_1 ,\sigma_2 ) L(W,σ1,σ2) ≈ e − s 1 L 1 ( W ) + e − s 2 L 2 ( W ) + s 1 + s 2 e^{-s1}L_1(W)+ e^{-s2}L_2(W)+s1+s2 e−s1L1(W)+e−s2L2(W)+s1+s2
pytorch代码实现如下:
class DynamicWeightedLoss(nn.Module):
def __init__(self, num=2):
super(DynamicWeightedLoss, self).__init__()
params = torch.ones(num, requires_grad=True)
self.params = torch.nn.Parameter(params)
def forward(self, *x):
loss_sum = 0
for i, loss in enumerate(x):
loss_sum += torch.exp(-self.params[i]) * loss
+ self.params[i]
return loss_sum
论文[2]对论文[1]做了loss的正则项做了优化,它的loss如下:
L
(
W
,
σ
1
,
σ
2
)
=
1
2
σ
1
2
L
1
(
W
)
+
1
2
σ
2
2
L
2
(
W
)
+
l
o
g
(
σ
1
2
+
1
)
+
l
o
g
(
σ
2
2
+
1
)
L(W,\sigma_1 ,\sigma_2 ) = \frac{1}{2\sigma ^2_1}L_1(W) + \frac{1}{2\sigma_2^2}L_2(W)+log(\sigma_1^2+1)+ log(\sigma_2^2+1)
L(W,σ1,σ2)=2σ121L1(W)+2σ221L2(W)+log(σ12+1)+log(σ22+1),
其pytroch代码实现如下:
class DynamicWeightedLoss(nn.Module):
def __init__(self, num=2):
super(DynamicWeightedLoss, self).__init__()
params = torch.ones(num, requires_grad=True)
self.params = torch.nn.Parameter(params)
def forward(self, *x):
loss_sum = 0
for i, loss in enumerate(x):
loss_sum += 0.5 / (self.params[i] ** 2) * loss
+ torch.log(1 + self.params[i] ** 2)
return loss_sum
5.进一步了解
如果还想对贝叶斯不确定性进一步了解,可以阅读reference部分的论文[3],如果还想对动态loss以及多任务进一步了解可以阅读综述性文章[4,5]以及一些经典的多任务论文[6,7,8]。
reference:
[1].Multi-Task Learning Using Uncertainty to Weigh Losses for Scene Geometry and Semantics
[2].Auxiliary Tasks in Multi-task Learning
[3].What Uncertainties Do We Need in Bayesian Deep Learning for Computer Vision?
[4].An Overview of Multi-Task Learning in Deep Neural Networks.pdf
[5].https://zhuanlan.zhihu.com/p/269492239
[6].Multi-Task Learning as Multi-Objective Optimization
[7].MMOE
[8].SNR
















 2506
2506











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









