







 本文探讨了使用深度学习,特别是autoencoder进行话题建模,发现其效果优于传统的LDA方法。通过调整autoencoder的损失函数为KL Divergence并优化激活函数,实验结果显示在新闻20组数据集上的主题建模效果达到0.73,显著提升。此外,还讨论了学习二进制latent vector的可能性,以优化存储和计算效率。
本文探讨了使用深度学习,特别是autoencoder进行话题建模,发现其效果优于传统的LDA方法。通过调整autoencoder的损失函数为KL Divergence并优化激活函数,实验结果显示在新闻20组数据集上的主题建模效果达到0.73,显著提升。此外,还讨论了学习二进制latent vector的可能性,以优化存储和计算效率。
深度学习也可以做topic modeling
4个月前想好好学学LDA的求解原理,发现还是很困难,用Gibbs Sampling以及一些variant方法解决问题的过程是知道了,但是依然不能很好的明白会什么这么做会有效,以及为什么会想到要那么做。
之后就去研究深度学习了,现在回过头来,发现其实用深度学习,也可以做topic modeling,而且从实验结果来说,要比LDA的效果,好太多了。
LDA产生的结果,是bag-of-words数据的软聚类,同时生成文档对主题的稀疏表示。
事实上,我们同样可以用autoencoder产生好的效果。
autoencoder结构非常简单,
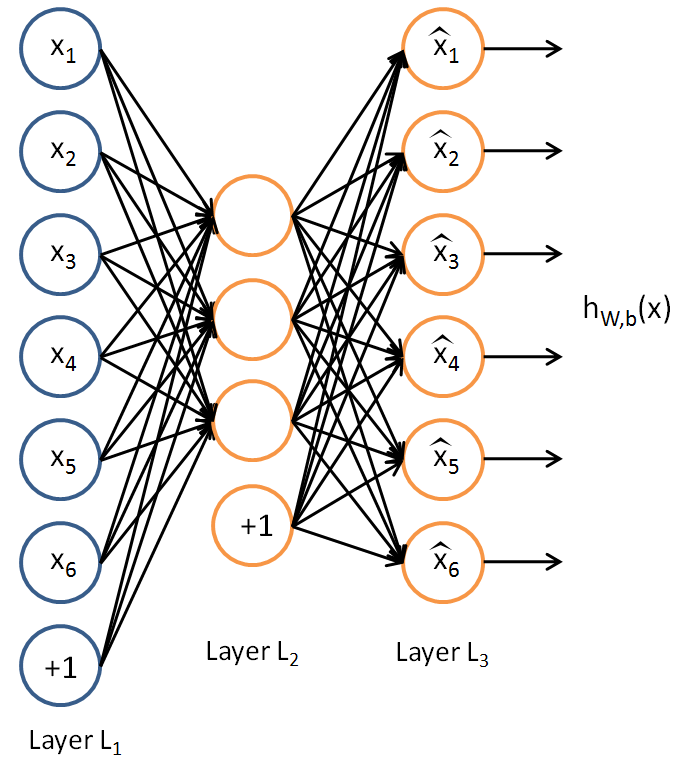
输入的是bag-of-words的稀疏向量,输出的也是一个稀疏向量,误差就是这两个向量之间的差距,即损失函数。
对训练之后得到的latent vector,进行聚类,就可以得到我们想要的topic modeling。
用news20group数据集,评测生成的topic结果,metric用的是Homogeneity and completeness scores




n是总样本数,
nc是属于classc的数目 ,
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1910
1910

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









