







一、典型的3种存储引擎
1、hash:
代表:nosql的redis/memcached
本质为: 基于(内存中)的hash;
所以支持 随机 的增删查改,读写的时间复杂度O(1);
但是无法支持顺序读写(注,这里指典型的hash,不是指如redis的基于跳表的zset的其他功能);
基本效果:在不需要有序遍历时,最优
2、磁盘查找树:
代表:mysql
本质为:基于(磁盘的)顺序查找树,B树/B+树;
基本效果:支持有序遍历;但数据量很大后,随机读写效率低(原因往下看);
3、lsmtree:
代表:leveldb/rocksdb
本质为: 实际落地存储的数据按key划分,形成有序的不同的文件;
结合其“先内存更新后合并落盘”的机制,尽量达到磁盘的写是顺序写,尽可能减少随机写;
对于读,需合并磁盘已有历史数据和当前未落盘的驻于内存的更新,较慢;
基本效果:也可以支持有序增删查改;写速度大幅提高;读速度稍慢;
重大改进点:
写:
1、将随机的写(的操作)保存于内存中,达到一定量后,写磁盘;而不是每次都去落盘;
2、落盘的文件(即level0以下层的文件,不含memtable即level0的文件),不论文件内部还是文件相互之间,均按key有序,可以二分查找,故无论是读,还是其合并操作,均为对数时间;
3、结合1和2,尽可能的减少了随机写;实现了有效的按顺序读写;
4、落盘的数据,会定期进行文件合并,即由多个小文件的二分查找合并为一个大文件,进一步利于增删查改效率;
读:
lsmtree引擎的读,需要在落盘文件中,查找要查的所有key,并查看当前未落盘的更新中是否存在相关的修改,较麻烦但也有优化;
二、数据和索引:
1、由key找value就是索引;
比如二叉查找树、平衡二叉树、红黑树,每一个节点,可以存储数据,可以存储数据所在地址,可以log(N)的找到增删查改,可以有序遍历,到这就是索引;
比如一个有序数组,每个数组元素,包括key和value,value来存储数据,或者存储数据地址,可以按key二分查找;这也是索引;
2、B树和B-树:
实际上没有使用1中的二叉树、有序数组来存储数据的;因为:
1、数据量很大时,二叉树非常高,需要很多步;
2、有序数组如果随机的插入删除,效果会如何;
B族树最常用于数据库如mysql的存储引擎:
首先是B树:

特征:
1、每个节点不再只有一个key,而是多个key;相比二叉树,有效压低了树高
2、和典型二叉树一样,依然是每个节点包括key和value;这加剧了随机IO问题,也是B+树被使用的原因;
典型B树,形似"多叉树",且每个节点包括多个有序节点,其访问方法,和二叉树道理一样,只是每个树的节点,包括了多个key而不是二叉树那样只有一个key,这样树的高度大大被压低,以其查询伪代码为例加深印象:
BTree_Search(node, key) {
if(node == null) return null;
foreach(node.key)
{
if(node.key[i] == key) return node.data[i];
if(node.key[i] > key) return BTree_Search(point[i]->node);
}
return BTree_Search(point[i+1]->node);
}
data = BTree_Search(root, my_key);如同AVL、红黑树一样,增删节点会导致B树分裂;
其读写的算法访问效率是对数级的,了解到这够用。
实际的数据库磁盘读写,如果是B树的话,会是这样做:
1、最开始创建B树时:
磁盘中申请空间,载入到内存,写入;
2、key按顺序不断写入磁盘时:
顺序写入磁盘,速度非常快,如按顺序insert大量数据到mysql时,因为:
1、每次都是申请一个磁盘页(如4K大小),而不是要写几个字节申请几个字节;
2、B树顺序写的时候,数据都是向后自然顺延,不发生分裂,除非当前磁盘页写满时,再申请一个新的磁盘页,继续顺序写;
3、当B树很大时,随机的写时:
比如,删除某一个key1,然后又更新一个key2的数据,key1和key2不在同一个磁盘页中,然后又增加一个key3导致发生分裂;
比如有大量的这样的操作,导致:
1、寻找key1时,内存未找到,被迫从磁盘里读取一个页;
2、删除后可能导致B树分裂,可能又导致更新磁盘里的其他数据;
3、增加一个key3,又没有找到,再次从磁盘读取一个页;可能导致分裂,再次导致更新磁盘其他页数据
4、更新一个key2,又没有找到;
5、最后会发现,数据越来越多后,增删查改操作,到处都是磁盘IO,经常需要从磁盘里读,然后写;
B+树的改进:
1、非叶子节点不再存储数据;好处是,使每一个磁盘页里,有更多一些的节点;能够减少一些磁盘IO;
2、mysql实际使用时,叶子节点加入了相邻叶子节点的指针;好处是,在有序遍历时,找到了一个叶子,就可以顺序的访问其他叶子,避免了都从根节点遍历;又减少了一些磁盘IO;
B+树,在非叶子层不再存储数据,因而每个树节点变小,也就集中了更多的节点;增多了一个磁盘页中,实际节点的个数;这对于减少磁盘IO是有很大意义的;mysql就是使用B+树作为数据索引;
B+树如下图:

至此,对基于B族树的存储引擎的mysql,其查询效率就是:
1、尽可能使按可以的顺序写入;
2、在随机不按key顺序的增删查改时,就没办法了,B+树尽可能一个磁盘页里有更多的节点,减少磁盘IO次数,叶子节点中加入相邻的指针,进一步减少磁盘IO,更方便范围检索;
现在看一下,同样基于B+树的数据结构,mysql两种典型的索引方式的实现:
1、myisam:
myisam对于表的主键的索引方式,如一个表有3个列,col1、col2、col3
myisam的叶子存储的数据是,数据所在的地址,而不是数据内容
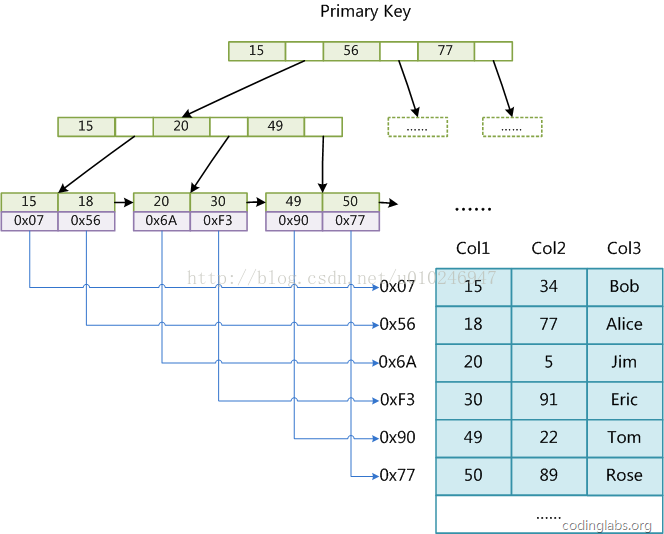
下图是myisam的非主键的索引,和主键索引方式差不多,也是存数据的地址:

myisam的索引方式的表,在查询时先通过B+树找到key,进而找到数据地址,然后再根据地址,找到数据内容;
2、innodb:
再来看一下innodb的,使用过mysql的都知道如下准则或建议:
1、innodb的表要求必须有主键;
2、主键尽可能建议是,按顺序自增的id;
3、主键不应该太长;
来看下为什么,下面是innodb的表的主键的索引:

innodb索引方式是把数据完全放在叶子节点上,而不是myisam那样只存数据地址;
再来看innodb的表的辅助键的索引:

看吧,innodb的表的辅助键的索引,存的其实是它对应的主键;
也就是:
1、innodb的索引,其实都是到它的主键索引,比如通过辅助键的查询,就是先通过辅助键索引,查到对应的主键,然后再去查主键的索引;
这就是为什么,innodb的表必须有主键;
同时也是为什么,innodb的表的行锁,其实也只是支持字段是主键时的操作时;如果是非主键字段,和myisamy一样是表锁;
innodb的表支持行锁,这也是其支持事务的必要条件之一
2、可见innodb的表是非常依赖主键的了,所以如果主键不是按照自增的顺序,那么在插入时,会出现B+树更多的分裂,内存找不到的又得找磁盘,导致更多的磁盘IO;
这就是为什么,innodb的表建议按业务无关的自增id作为主键;
3、如果主键是一个特别长的字符串之类东西,那么辅助键的索引,叶子节点也都会存这些特别长的主键,那么辅助键的索引,会很大;
这就是为什么,innodb的表不建议主键使用特别长的字段;
4、innodb的叶子存的是数据,比起myisam存的是地址,在写时,原则上应该会少一些磁盘IO,因为myisam还需要再去获取数据;
上面介绍了基于B族树存储引擎的(mysql)的读写原理,结论是:不论是B树,还是B+树,在数据量很大时,随机IO问题均无法良好处理;
3、lsmtree引擎:
大量的随机写,导致B族树在数据很大时,出现大量磁盘IO,导致速度越来越慢,lsmtree是怎么解决这个问题的:
1、尽可能减少写磁盘次数;
2、即便写磁盘,也是尽可能顺序写;
方法:
1、对数据,按key划分为若干level;
每一个level对应若干文件,包括存在于内存中和落盘了的;
文件内key都是有序的,同级的各个文件之间,一般也有序
如leveldb/rocksdb,level0对应于内存中的数据(0.sst),后面的依次是1、2、3、...的各级文件(默认到level6级)
2、写时,先写对应于内存的最低level的文件;这是之所以写的快的一个重要原因
存在于内存的数据,也是被持久化的以防丢失;
存在于内存的数据,到达一定大小后,被合并到下一级文件落盘;
3、落盘后的各级文件,也会定期进行排序加合并(compact),合并后数据进入下一层level;
这样的写入操作,大多数的写,都是对一个磁盘页顺序的写,或者申请新磁盘页写,而不再是随机写
所以总结lsmtree的写为什么快的两大原因:
1、每次写,都是在写内存;
2、定期合并写入磁盘,产生的写都是按key顺序写,而不是随机查找key再写;
可见compact是个很重要的事情了,下面是基于lsmtree引擎的rocksdb的compact过程:
首先看一下rocksdb的各级文件组织形式:

然后,各级的每个文件,内部都是按key有序,除了内存对应的level0文件,各级的内部文件之间,也是按key有序的;
这样,查找一个key,很方便二分查找(当然还有bloomfilter等的进一步优化)

再然后,每一级的数据到达一定阈值时,会触发排序归并,简单说,就是在两个level的文件中,把key有重叠的部分,合并到高层level的文件里
这个在lsmtree里,叫数据压缩(compact);



对于rocksdb,除了内存那个level0到level1的compact,其他各级之间的compact是可以并行的;通常设置较小的level0到level1的compact阈值,加快这一层的compact
良好的归并策略的配置,使数据尽可能集中在最高层(90%以上),而不是中间层,这样有利于compact的速度;
另外,对于基于lsmtree的(rocksdb的)读,需要在各级文件中二分查找,磁盘IO也不少,此外还需要关注level0里的对于这个key的操作,比较明显的优化是,通过bloomfilter略掉肯定不存在该key的文件,减少无谓查找;
附:
rocksdb vs leveldb:
1、rocksdb可以有多个memtable(level0的内存文件的部分);致力于解决写速度快于compact速度的问题;
2、rocksdb支持merge operator操作,即用户可以自定义对key的合并;
3、rocksdb支持多线程的compact(除了level0的内存文件的部分);
4、rocksdb支持多个key查找(multiget)、范围查找(rangeget);
5、rocksdb支持单进程打开多个rocksdb实例;
6、rocksdb支持在compact时根据key的有效期进行滤除;















 2756
2756











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









