







梯度下降法
一、基本概念
梯度下降法,就是利用负梯度方向来决定每次迭代的新的搜索方向,使得每次迭代能使待优化的目标函数逐步减小。梯度下降法是2范数下的最速下降法。 最速下降法的一种简单形式是:x(k+1)=x(k)-a*g(k),其中a称为学习速率,可以是较小的常数。g(k)是x(k)的梯度。
机器学习算法究竟有多好,或者说误差为多少,我们可以下面的一个误差函数J(θ), θ在神经网络中可以理解为权值,如何调整权值θ以使得J(θ)取得最小值有很多方法,梯度下降法是按下面的流程进行的:
1)首先对θ赋值,这个值可以是随机的,也可以让θ是一个全零的向量。
2)改变θ的值,使得J(θ)按梯度下降的方向进行减少。
为了更清楚,给出下面的图:

这是一个表示参数θ与误差函数J(θ)的关系图,红色的部分是表示J(θ)有着比较高的取值,我们需要的是,能够让J(θ)的值尽量的低。也就是深蓝色的部分。θ0,θ1表示θ向量的两个维度。
在上面提到梯度下降法的第一步是给θ给一个初值,假设随机给的初值是在图上的十字点。然后我们将θ按照梯度下降的方向进行调整,就会使得J(θ)往更低的方向进行变化,如图所示,算法的结束将是在θ下降到无法继续下降为止。当然,可能梯度下降的最终点并非是全局最小点,可能是一个局部最小点,可能是下面的情况:

二、导数
(1)定义
设有定义域和取值都在实数域中的函数  。若
。若 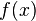 在点
在点 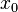 的某个邻域内有定义,则当自变量
的某个邻域内有定义,则当自变量 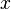 在 处取得增量
在 处取得增量 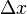 (点
(点  仍在该邻域内)时,相应地函数
仍在该邻域内)时,相应地函数  取得增量
取得增量 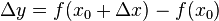 ;如果
;如果 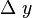 与
与 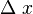 之比当
之比当  时的极限存在,则称函数
时的极限存在,则称函数  在点 处可导,并称这个极限为函数 在点 处的导数,记为
在点 处可导,并称这个极限为函数 在点 处的导数,记为 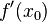 ,即:
,即:
 |
也可记作 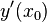 、
、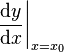 、
、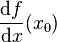 或
或  。
。
对于一般的函数,如果不使用增量的概念,函数 在点  处的导数也可以定义为:当定义域内的变量
处的导数也可以定义为:当定义域内的变量  趋近于 时,
趋近于 时,

的极限。也就是说,
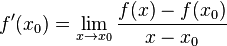
导数反应的变化率
一个函数在某一点的导数描述了这个函数在这一点附近的变化率。导数的本质是通过极限的概念对函数进行局部的线性逼近。当函数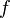 的自变量在一点
的自变量在一点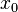 上产生一个增量
上产生一个增量 时,函数输出值的增量与自变量增量的比值在趋于0时的极限如果存在,即为在处的导数,记作
时,函数输出值的增量与自变量增量的比值在趋于0时的极限如果存在,即为在处的导数,记作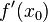 、或
、或
(2)几何意义:

一个实值函数的图像曲线。函数在一点的导数等于它的图像上这一点处之切线的斜率,导数是函数的局部性质。不是所有的函数都有导数,一个函数也不一定在所有的点上都有导数。若某函数在某一点导数存在,则称其在这一点可导,否则称为不可导。如果函数的自变量和取值都是实数的话,那么函数在某一点的导数就是该函数所代表的曲线在这一点上的切线斜率。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 229
229











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









