







文章目录
1、TF-IDF介绍
(1)意义
主要用于自然语言中文本特征向量化。
特征向量化方案:
- 词的特征位置映射: Hash映射
- 词的特征值选取:不再简单地用词频作为特征值,而改用NLP中最经典的衡量一个词在一篇文章中重要性的指标(TF-IDF)
(2)核心思想
- 这个词在一篇文章中出现的频次越高,重要性越高!
- 在整个样本集中,含有这个词的文章数越少,这个词重要性越高!
(3)计算公式
TF-IDF =TF × IDF
- TF :词频(可以用频次,也可以用频率)
- IDF:逆文档频率 = log( 文档总数 / (1+出现这个词的文档数) )
比如说:
经验样本中共有3篇文档。在一篇文档中有“电池”这个词,且出现了3次。其余两篇文档中没有出现这个词。
那么TF-IDF = 3 × log(3 / (1+1) )
在一篇文档中有“手机”这个词,且出现了3次,其余两篇文档中也出现了这个词。
那么TF-IDF = 3 × log(3 / ( 3+1) )
2、需求分析
(1)样本数据
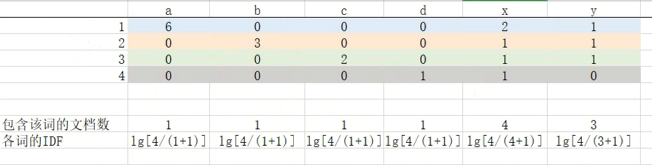
需求:有如下的数据,将该文本的特征向量化
docid,doc
1,a a a a a a x x y
2,b b b x y
3,c c x y
4,d x
(2)分析
需要确定三点:
- 向量的长度:去重后的词个数 × 10(可取别的,尽量大,减少哈希碰撞)
- 词在向量中的特征位置:词的Hash映射
- 词在向量中的特征值:TF-IDF
该样本中,计算TF-IDF的思路如下图:
(3)技术点
- SparkSql的DSL风格★★
- Spark相关算子★★
- UDF函数 ★★★
- UDAF函数★★★★★
3、实战 · 深入剖析
代码共分三大块:
- 主线代码
- 工具类代码
- UDFA函数代码
(1)主线代码
package cn.ianlou.tf_idf
import org.apache.log4j.{Level, Logger}
import org.apache.spark.sql.{DataFrame, SparkSession}
/**
* @date: 2020/2/22 21:50
* @site: www.ianlou.cn
* @author: lekko 六水
* @qq: 496208110
* @description:
*
*/
object TFIDF_SQL {
def main(args: Array[String]): Unit = {
Logger.getLogger("org.apache.spark").setLevel(Level.WARN)
val spark: SparkSession = SparkSession
.builder()
.appName(this.getClass.getSimpleName)
.master("local[*]")
.getOrCreate()
// 1、 读取文件加载数据
val sample: DataFrame = spark.read
.option("header", true)
.csv("userProfile/data/tfidf/docs.txt")
import cn.ianlou.tf_idf.TF_IDF_Utils._
// 2、特征向量化工程 -> TF词频向量化
// 自定义UDF函数 docToTF( ),并注册 设定向量长度为26(26个字母数)
spark.udf.register("docToTF", docToTF)
val tf: DataFrame = sample.selectExpr("docid", "docToTF(doc, 26) as tfArr")
/** TF数据如下:
* +-----+-------------------------------------------------------------------+
* |docid| tfArr |
* +-----+-------------------------------------------------------------------+
* |1 |[0.0, 0.0, ...... 2.0, 1.0, 0.0, 6.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0]|
* |2 |[0.0, 0.0, ...... 1.0, 1.0, 0.0, 0.0, 3.0, 0.0, 0.0, 0.0, 0.0, 0.0]|
* |3 |[0.0, 0.0, ...... 1.0, 1.0, 0.0, 0.0, 0.0, 2.0, 0.0, 0.0, 0.0, 0.0]|
* |4 |[0.0, 0.0, ...... 1.0, 0.0, 0.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, 0.0]|
* +-----+-------------------------------------------------------------------+
*/
// 3、特征向量化工程 -> TF数组中不为0的值替换成1,规范、归一化
spark.udf.register("tfarrToOne", tfarrToOne)
val toOneTmp: DataFrame = tf.selectExpr("docid", "tfarrToOne(tfArr) as toOne")
/** 归一化后的数据:
* +-----+------------------------------------------------------------------------------+
* |docid| toOne |
* +-----+------------------------------------------------------------------------------+
* |1 |[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 0, 1, 0, 0, 0, 0, 0, 0]|
* |2 |[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 0, 0, 1, 0, 0, 0, 0, 0]|
* |3 |[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 0, 0, 0, 1, 0, 0, 0, 0]|
* |4 |[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 1, 0, 0, 0]|
* +-----+------------------------------------------------------------------------------+
*/
// 4、特征向量化工程 -> 将归一化后的所有数组,对应位置的元素累加到一起
// 获得该位置的词 出现过的文档数量
//sparkSql中没有对多行数组进行聚合的,多进一出,所以需要写UDAF函数 arrSum()
import cn.ianlou.tf_idf.ArrSumUDAF
spark.udf.register("arrSum", ArrSumUDAF)
val docCntDF: DataFrame = toOneTmp.selectExpr("arrSum(toOne) as wd_Doc_Cons")
/** 映射在特征向量中位置的词语,在经验样本中所出现过的文档数:
* +-----------------------------------------------------------------------------+
* | wd_Doc_Cons |
* +-----------------------------------------------------------------------------+
* |[0.0, 0.0, 0.0, ...... 0.0, 4.0, 3.0, 0.0, 1.0, 1.0, 1.0, 1.0, 0.0, 0.0, 0.0]|
* +-----------------------------------------------------------------------------+
*/
// 5、计算IDF -> log(文档总数/(1+词出现过的文档数))
val total: Long = sample.count()
spark.udf.register("doc_consToIdf", doc_consToIdf)
val idf: DataFrame = docCntDF.selectExpr("doc_consToIdf(wd_Doc_Cons, " + total + ") as idf")
/** 得到的IDF:
* +-------------------------------------------------------------------------------------------+
* |idf |
* +-------------------------------------------------------------------------------------------+
* |[2.602......2.602, -0.001, 0.123, 2.602, 0.598, 0.598, 0.598, 0.598, 2.602, 2.602, 2.602] |
* +-------------------------------------------------------------------------------------------+
*/
// 6、将TF 和 IDF 做拉链,然后相乘得到TF-IDF
val frame: DataFrame = tf.crossJoin(idf)
spark.udf.register("toTF_IDF", toTF_IDF)
val final_TFIDF: DataFrame = frame.selectExpr("toTF_IDF(tfArr, idf)")
final_TFIDF.show(20, false)
/** 得到的最终的TF-IDF:
* +-----------------------------------------------------------------------------------+
* | UDF:toTF_IDF(tfArr, idf) |
* +-----------------------------------------------------------------------------------+
* |[0.0, ...0.0, 0.0, -0.00217, 0.12349, 0.0, 3.58643, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0] |
* |[0.0, ...0.0, 0.0, -0.00108, 0.12349, 0.0, 0.0, 1.79321, 0.0, 0.0, 0.0, 0.0, 0.0] |
* |[0.0, ...0.0, 0.0, -0.00108, 0.12349, 0.0, 0.0, 0.0, 1.195477, 0.0, 0.0, 0.0, 0.0] |
* |[0.0, ...0.0, 0.0, -0.00108, 0.0, 0.0, 0.0, 0.0, 0.0, 0.59774, 0.0, 0.0, 0.0] |
* +-----------------------------------------------------------------------------------+
*/
spark.close()
}
}
(2)工具类代码
package cn.ianlou.tf_idf
import scala.collection.mutable
/**
* @date: 2020/2/22 21:56
* @site: www.ianlou.cn
* @author: lekko 六水
* @qq: 496208110
*/
object TF_IDF_Utils {
/**
* UDF函数:
* 输入一篇文档,输出TF词频的特征向量(数组类型)
* a a a a a a x x y => [0, 6, 0, 1...0, 2, 0]
*/
val docToTF = (doc: String, len: Int) => {
//构建一个空数组,元素都为0.0,长度为len
val arr: Array[Double] = Array.fill(len)(0.0)
val tmap: Map[String, Array[String]] = doc.split(" ").groupBy(e => e)
// <(a -> 6), (x -> 2), (y -> 1)>
val wcount: Map[String, Int] = tmap.map(mp => (mp._1, mp._2.size))
//将arr空数组中的值替换,按词的hash值映射到数组中
for ((k, v) <- wcount) {
val index: Int = (k.hashCode & Integer.MAX_VALUE) % len
arr(index) = v
}
arr
}
/**
* UDF函数:
* 输入一个数组,将数组中的非0值,替换成1
*/
val tfarrToOne = (arr: mutable.WrappedArray[Double]) => {
arr.map(e => if (e != 0) 1 else 0)
}
/**
* UDF函数:
* 将聚合好的词所出现过的文档数的数组,计算后转成IDF log(文档总数/(1+词文档数))
*/
val doc_consToIdf = (arrs: mutable.WrappedArray[Double], total: Int) => {
arrs.map(e => Math.log10(total / (0.01 + e)))
}
/**
* UDF函数:
* 将TF和IDF结果crossJoin后,输入TF数组和IDF数组,
* 输出两个数组对应位置上元素相乘后的结果数组
*/
val toTF_IDF = (arr1: mutable.WrappedArray[Double], arr2: mutable.WrappedArray[Double]) => {
arr1.zip(arr2).map(tp => (tp._1 * tp._2))
}
}
(3)UDAF函数
package cn.ianlou.tf_idf
import org.apache.spark.sql.Row
import org.apache.spark.sql.expressions.{MutableAggregationBuffer, UserDefinedAggregateFunction}
import org.apache.spark.sql.types.{DataType, DataTypes, StructType}
/**
* @date: 2020/2/22 23:09
* @site: www.ianlou.cn
* @author: lekko 六水
* @qq: 496208110
* @description: UDAF用户自定义聚合函数:多进一出
* 需要继承UserDefinedAggregateFunction,并实现所有的抽象方法
*/
object ArrSumUDAF extends UserDefinedAggregateFunction {
//函数的输入参数,有几个字段,分别是什么类型 arrSum(toOne)
override def inputSchema: StructType = new StructType()
.add("toOne", DataTypes.createArrayType(DataTypes.DoubleType))
// buffer 是在聚合函数运算过程中,用于存储局部聚合结果的缓存
override def bufferSchema: StructType = new StructType()
.add("buffer", DataTypes.createArrayType(DataTypes.DoubleType))
// 最后返回结果的数据类型,在本需求中,还是一个Double数组
override def dataType: DataType = DataTypes.createArrayType(DataTypes.DoubleType)
// 聚合运算逻辑,是否总是能返回确定结果
override def deterministic: Boolean = true
//对buffer进行初始化,在本需求中,我们先给一个长度为0的空double数组
override def initialize(buffer: MutableAggregationBuffer): Unit = buffer
.update(0, Array.emptyDoubleArray)
//局部聚合的逻辑所在地,大的逻辑就是,根据输入的一行数据input,来更新局部缓存buffer中的数据
override def update(buffer: MutableAggregationBuffer, input: Row): Unit = {
// 1、从Row中取出double类型的数组
val inpArr: Seq[Double] = input.getSeq[Double](0)
var buffArr: Seq[Double] = buffer.getSeq[Double](0)
// 2、判断初始缓存数组大小是否为0, 若是,则buff数组为初始数组,然后给定初始数组的长度
if (buffArr.size < 1) buffArr = Array.fill(inpArr.size)(0.0)
// 3、将buffer数组和输入的数组进行拉链,然后sum相加
buffArr = buffArr.zip(inpArr).map(tp => (tp._1 + tp._2))
// 4、将聚合结果更新到buffer中去
buffer.update(0, buffArr)
}
// 全局聚合逻辑所在地,将各个partition的局部聚合结果,往buffer上做累加
override def merge(buffer1: MutableAggregationBuffer, buffer2: Row): Unit = {
val inpArr: Seq[Double] = buffer2.getSeq[Double](0)
var finalArr: Seq[Double] = buffer1.getSeq[Double](0)
if (finalArr.size < 1) finalArr = Array.fill(inpArr.size)(0.0) //初始化全局聚合的累加数组
finalArr = finalArr.zip(inpArr).map(tp => (tp._1 + tp._2))
buffer1.update(0, finalArr)
}
// 最后向外部返回最终的全局聚合结果
override def evaluate(buffer: Row): Any = buffer.getSeq[Double](0)
}
4、TF-IDF直接调用篇
上面的手撕,是为了更加清楚、理解TF-IDF整个的计算过程、计算原理。
其实有封装好的算法,可直接调用,就能得到TF-IDF:
(1)代码
package cn.ianlou.tf_idf
import org.apache.log4j.{Level, Logger}
import org.apache.spark.ml.feature.{HashingTF, IDF, IDFModel}
import org.apache.spark.sql.{DataFrame, SparkSession}
/**
* @date: 2020/2/23 21:06
* @site: www.ianlou.cn
* @author: lekko 六水
* @qq: 496208110
* @description:
*
*/
object TFIDF_Mllib {
def main(args: Array[String]): Unit = {
Logger.getLogger("org.apache.spark").setLevel(Level.WARN)
val spark: SparkSession = SparkSession
.builder()
.appName(this.getClass.getSimpleName)
.master("local[*]")
.getOrCreate()
val sample: DataFrame = spark.read
.option("header", true)
.csv("userProfile/data/tfidf/docs.txt")
// 1、加载样本数据,进行切词
val sampleDF: DataFrame = sample.selectExpr("docid", "split(doc, ' ') as words")
// 2、 构建hashingTF对象,获取TF值向量
val tfDF: HashingTF = new HashingTF()
.setInputCol("words")
.setOutputCol("tf_vector")
val tf: DataFrame = tfDF.transform(sampleDF)
// 3、构建IDF对象,获取IDF模型向量
val idfDF: IDF = new IDF()
.setInputCol("tf_vector")
.setOutputCol("tfidf_vec")
val idf_model: IDFModel = idfDF.fit(tf)
// 4、将TF和IDF转换成TF-IDF
val tfidf: DataFrame = idf_model.transform(tf)
tfidf.show(20, false)
spark.close()
}
}
(2)问题解决
正如上一篇提到的,用TF-IDF作为特征值有效解决了,用词频代表特征值的局限性和不妥性。
TFIDF也是最经典的,处理NLP中衡量一个词在一篇文章重要性的指标。















 7803
7803











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









