







上一篇介绍了虚拟化分别从计算虚拟化、存储虚拟化和网络虚拟化几个角度总体说了一下。下面就主意进行讲解,本篇先介绍计算虚拟化,其实我觉得用计算虚拟化可能比较狭隘,我个人更偏向另个一个更大的概念,软件定义的计算。
计算虚拟化分类
计算虚拟化就是在虚拟系统和底层硬件之间抽象出CPU和内存等,以供虚拟机使用。计算虚拟化技术需要模拟出一套操作系统的运行环境,在这个环境你可以安装window也是可以按照linux,这些操作系统被称作guestos。他们相互独立,互不影响(相对的,因为当主机资源不足会出现竞争等问题,导致运行缓慢等问题)。计算虚拟化可以将主机单个物理核虚拟出多个vcpu,这些vcpu本质上就是运行的进程,考虑到系统调度,所以并不是虚拟的核数越多越好;内存相似的,把物理机上面内存进行逻辑划分出多个段,供不同的虚拟机使用,每个虚拟机看到的都是自己独立的一个内存。除了这些还需要模拟网络设备、BIOS等。这个虚拟化软件叫做hypervisor,著名的有ESXI、xen、KVM等,通常分为两种,第一种是直接部署到物理服务器上面的,如下图ESXI

由于直接部署到裸机上面,hypervisor需要自带各种硬件驱动,虚拟机的所有操作都需要经过hypervisor。还有另一种虚拟化hypervisor,以KVM最为流行(个人电脑上面安装的virtualbox以及workstations也是),它们依赖与宿主机操作系统,这样的好处就是可以充分利用宿主机的各种资源管理以及驱动,但销量上面会打一些折扣。下图是KVM的在使用IO时候的流程图。

当然也可以从全虚拟化、半虚拟化、硬件辅助虚拟化的角度去说,现在数据中心基本都是硬件辅助虚拟化了,全虚拟化就是完全靠软件模拟、半虚拟需要修改操作让其知道自己运行在虚拟环境中、硬件辅助由硬件为每个guestos提供一套寄存器、guestos可以直接运行在特权级,这样提高效率。
虽然当前数据中心商用的虚拟化软件仍然以VMware的ESXI为主,但在openstack的推动下,KVM慢慢追赶并且KVM是开源的,下面简单介绍一下KVM。KVM是基于内核的,从内核2.6以后就自带了,可以运行在x86和power等主流架构上。
KVM主要是CPU和内存的虚拟化,其它设备的虚拟化和虚拟机的管理则需要依赖QEMU完成。一个虚拟机本质上就是一个进程,运行在QEMU-KVM进程地址空间,KVM(内核空间)和qemu(用户空间)相结合一起向用户提供完整的虚拟化环境。在硬件辅助虚拟化的环境中,
CPU
CPU具有根模式和非根模式,每种模式下又有ring0和ring3。宿主机运行在根模式下,宿主机的内核处于ring0,而用户态程序处于ring3,guestos运行在非根模式,相似的,guestos的内核运行在ring0,用户态程序运行在ring3。当处于非根模式的guestos,当外部中断或缺页异常,或者主动调用 VMCALL 指令调用 VMM 的服务的时候(与系统调用类似)的时候,硬件自动挂起 Guest OS,CPU会从非根模式切换到根模式,整个过程称为vm_exit,相反的,VMM 通过显式调用 VMLAUNCH 或 VMRESUME 指令切换到 VMX non-root operation 模式,硬件自动加载 Guest OS 的上下文,于是 Guest OS 获得运行,这种转换称为 VM entry。
内存
除了 CPU 虚拟化,另一个关键是内存虚拟化,通过内存虚拟化共享物理系统内存,动态分配给虚拟机。虚拟机的内存虚拟化很象现在的操作系统支持的虚拟内存方式,应用程序看到邻近的内存地址空间,这个地址空间无需和下面的物理机器内存直接对应,操作系统保持着虚拟页到物理页的映射。现在所有的 x86 CPU 都包括了一个称为内存管理的模块MMU(Memory Management Unit)和 TLB(Translation Lookaside Buffer),通过MMU和TLB来优化虚拟内存的性能。KVM 实现客户机内存的方式是,利用mmap系统调用,在QEMU主线程的虚拟地址空间中申明一段连续的大小的空间用于客户机物理内存映射。
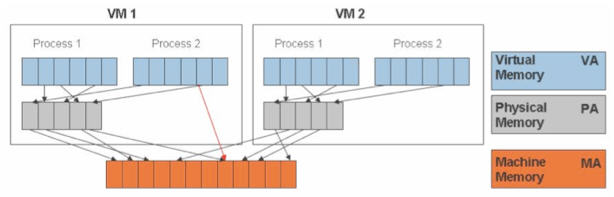
KVM 为了在一台机器上运行多个虚拟机,需要增加一个新的内存虚拟化层,也就是说,必须虚拟 MMU 来支持客户操作系统,来实现 VA -> PA -> MA 的翻译。客户操作系统继续控制虚拟地址到客户内存物理地址的映射 (VA -> PA),但是客户操作系统不能直接访问实际机器内存,因此VMM 需要负责映射客户物理内存到实际机器内存 (PA -> MA)。
VMM 内存虚拟化的实现方式:
软件方式:通过软件实现内存地址的翻译,比如 Shadow page table (影子页表)技术
硬件实现:基于 CPU 的辅助虚拟化功能,比如 AMD 的 NPT 和 Intel 的 EPT 技术
关于内存管理还有像内存气泡技术、内存交换技术、零页共享技术等关于KVM详细细节和实战将在后面blog讲述。
计算池
当通过底层的虚拟化技术将底层计算资源抽象过后,就可以在数据中心层面形成一个统一的计算资源池,这就是云计算设计的初衷,资源池化,按需计费。当完成池化以后,用户申请使用计算资源的时候就可以从池中取出一部分资源供用户使用,当用户退订资源后,这部分资源又回到池中,供其他用户使用。这里涉及到两个概念:资源调度和异构虚拟化的问题。
资源调度就是当用户申请资源的时候,系统需要调度确定资源位置(决定虚拟机开在那台物理机器上)。通常的调度算法分为两层,第一层是主机过滤第二层是权值打分。如下图:

通过Filter和weight决定这次创建资源应该分配到那一台服务器上。
第二个问题是异构资源,就是数据中心里面有多种虚拟化存在的场景,当然对于最终用户是不需要感知的,当有不同的虚拟化存在的时候,平台需要去适配各种虚拟化接口。

高级使用
在实际的生产环境中计算虚拟化还有很多重要东西,我这里列举几个我认为是关键的一些因素。
SR-IOV
SR-IOV是采用直通技术,将虚拟机直接和物理网卡直接通信,避免软件层对网络转发的延迟、抖动的影响,满足高性能场景。在通常的服务器虚拟化中需要创建虚拟网卡,tun、tap、veth等软件虚拟的网络设备,这些网络设备一端连接到虚拟机中,另一端连接到虚拟网桥上,最终通过物理网卡输出或者输入,由于软件模拟的设备在性能和稳定性上和物理设备差别还是挺大,很容易导致IO的瓶颈。SR-IOV是一种不需要软件模拟就可以共享IO设备的技术,它通过虚拟通道(PF:完整的PCIe设备、VF:简化的PCIe,仅包含I/O功能)将一个PCIe设备虚拟出多个PCIe设备。
容器
我把容器也纳入计算虚拟化,容器相比于虚拟机有很多优势如:轻量级(无需打包整个操作系统,镜像通几百兆之内,相比于虚拟机动辄几个G的镜像小很多)、跨平台(容器一直鼓吹的就是一次打包多次部署,build->ship->run)、细粒度(容器可以将cpu等资源进行更细粒度的划分,如0.1个CPU),当然容器也有很多问题如:隔离比较差、不够安全等,这些事我将在后面单独的关于容器的blog介绍。容器技术并非是一个新的东西,LXC很早就有了,容器依赖的cgroup资源限制,namespace资源隔离等这些都是Linux已经有的技术,Docker最大的贡献应该是定义了一套镜像规范。容器技术推动着CI/CD的进步,虽然CI/CD技术已经不是新鲜概念,但在容器技术之前CI/CD很难落地。容器技术目前已Docker最为出名,当然还有rkt等其他的容器,为了不使容器技术过于封闭,Linux基金会把。容器技术广泛应用也带来运维管理的问题,也就出现了各种容器管理平台如swarm、marathon、kubernetes等。

















 4663
4663

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











