







一、什么是kafka
kafka是分布式发布-订阅消息系统。它最初由LinkedIn公司开发,之后成为Apache项目的一部分。Kafka是一种快速、可扩展的、设计内在就是分布式的,分区的和可复制的提交日志服务。
重点内容
二、kafka架构
Kafka内在就是分布式的,一个Kafka集群通常包括多个broker。为了均衡负载,将话题分成多个分区,每个broker存储一或多个分区。多个生产者和消费者能够同时生产和获取消息。
架构中的主要组件解析如下:
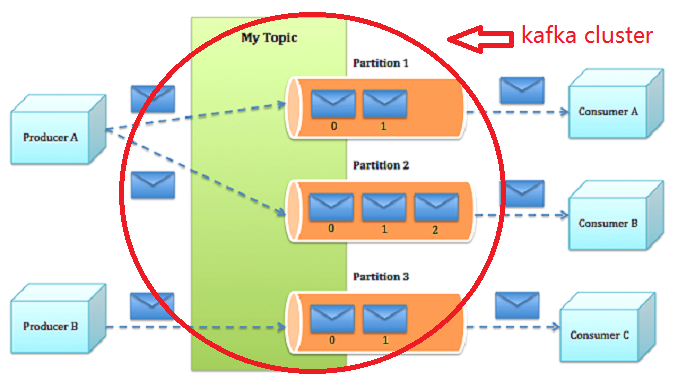
- 话题(Topic)是特定类型的消息流。消息是字节的有效负载(Payload),话题是消息的分类名或种子(Feed)名。
- 生产者(Producer)是能够发布消息到话题的任何对象。 已发布的消息保存在一组服务器中,它们被称为Broker或Kafka集群。
- 消费者可以订阅一个或多个话题,并从Broker拉数据,从而消费这些已发布的消息。
三、kafka存储结构设计
kafka存储布局是在话题的每个分区对应一个逻辑日志。物理上,一个日志为相同大小的一组分段文件。每次生产者发布消息到一个分区,代理就将消息追加到最后一个段文件中。当发布的消息数量达到设定值或者经过一定的时间后,段文件真正写入磁盘中。写入完成后,消息公开给消费者。其结构如下图所示:
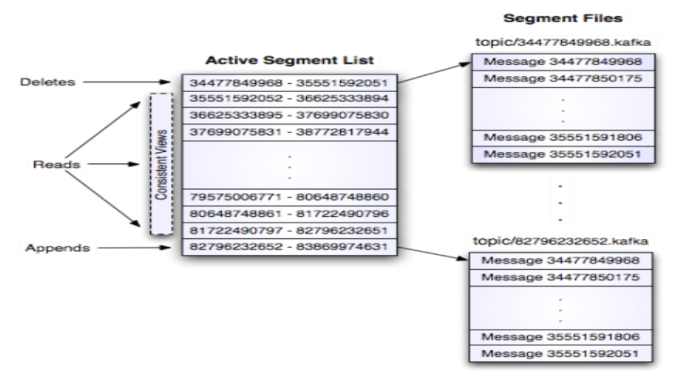
消费者始终从特定分区顺序地获取消息,如果消费者知道特定消息的偏移量,也就说明消费者已经消费了之前的所有消息。消费者向代理发出异步拉请求,准备字节缓冲区用于消费。每个异步拉请求都包含要消费的消息偏移量。Kafka利用sendfile API高效地从代理的日志段文件中分发字节给消费者。
四、kafka 应用代码示例
Kafka生产者代码示例:
public KafkaMailProducer(String topic, String directoryPath) {
props.put("serializer.class", "kafka.serializer.StringEncoder");
props.put("metadata.broker.list",  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 952
952

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









