







一、Hive是什么?
Hive 是基于 Hadoop 构建的一套数据仓库分析系统,它提供了丰富的 SQL 查询方式来分析存储在 Hadoop 分布式文件系统中的数据, 可以将结构化的数据文件映射为一张数据库表,并提供完整的 SQL 查询功能,可以将 SQL 语句转换为 MapReduce 任务进行运行,通过自己的 SQL 去 查询分析需要的内容,这套 SQL 简称 Hive SQL。
二、理解Hive 架构
Hive 架构可以分为四部分。
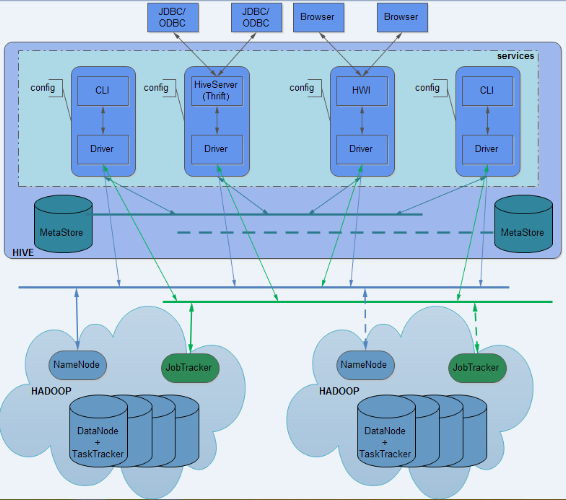
用户接口
Hive 对外提供了三种服务模式,即 Hive 命令行模式(CLI),Hive 的 Web 模式(WUI),Hive 的远程服务(Client)。下面介绍这些服务的用法。
1、 Hive 命令行模式
Hive 命令行模式启动有两种方式。执行这条命令的前提是要配置 Hive 的环境变量。
1) 进入 /home/hadoop/app/hive 目录,执行如下命令。./hive
2) 直接执行命令。
hive - -service cli
Hive 命令行模式用于 Linux 平台命令行查询,查询语句基本跟 MySQL 查询语句类似,运行结果如下所示。
[hadoop@ywendeng hive]$ hive
hive> show tables;
OK
stock
stock_partition
tst
Time taken: 1.088 seconds, Fetched: 3 row(s)
hive> select * from tst;
OK
Time taken: 0.934 seconds
hive> exit;
[hadoop@djt11 hive]$2、Hive Web 模式
Hive Web 界面的启动命令如下。
hive - -service hwi
通过浏览器访问 Hive,默认端口为 9999。
异常:16/05/31 20:24:52 FATAL hwi.HWIServer: HWI WAR file not found at /home/hadoop/app/hive/home/hadoop/app/hive/lib/hive-hwi-0.12.0.war
解决办法:将hive-default.xml 文件中关于hwi的配置文件拷贝到hive-site.xml文件中
示例:
<property>
<name>hive.hwi.war.file</name>
<value>lib/hive-hwi-0.12.0-SNAPSHOT.war</value>
<description>This sets the path to the HWI war file, relative to ${HIVE_HOME}. </description>
</property>
<property>
<name>hive.hwi.listen.host</name>
<value>0.0.0.0</value>
<description>This is the host address the Hive Web Interface will listen on</description>
</property>
<property>
<name>hive.hwi.listen.port</name>
<value>9999</value>
<description>This is the port the Hive Web Interface will listen on</description>
</property> 3、 Hive 的远程服务
远程服务(默认端口号 10000)启动方式命令如下,“nohup…&” 是 Linux 命令,表示命令在后台运行。
nohup hive - -service hiveserver2 & //在Hive 0.11.0版本之后,提供了HiveServer2服务Hive 远程服务通过 JDBC 等访问来连接 Hive ,这是程序员最需要的方式。
hive --service hiveserver2 & //默认端口10000
hive --service hiveserver2 --hiveconf hive.server2.thrift.port 10002 & //可以通过命令行直接将端口号改为10002hive的远程服务端口号也可以在hive-default.xml文件中配置,修改hive.server2.thrift.port对应的值即可。
< property>
< name>hive.server2.thrift.port< /name>
< value>10000< /value>
< description>Port number of HiveServer2 Thrift interface when hive.server2.transport.mode is 'binary'.< /description>
< /property>Hive 的 JDBC 连接和 MySQL 类似,如下所示。
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.SQLException;
public class HiveJdbcClient {
private static String driverName = "org.apache.hive.jdbc.HiveDriver";//hive驱动名称 hive0.11.0之后的版本
//private static String driverName = "org.apache.hadoop.hive.jdbc.HiveDriver";//hive驱动名称 hive0.11.0之前的版本
public static void main(String[] args) throws SQLException {
try{
Class.forName(driverName);
}catch(ClassNotFoundException e){
e.printStackTrace();
System.exit(1);
}
//第一个参数:jdbc:hive://djt11:10000/default 连接hive2服务的连接地址
//第二个参数:hadoop 对HDFS有操作权限的用户
//第三个参数:hive 用户密码 在非安全模式下,指定一个用户运行查询,忽略密码
Connection con = DriverManager.getConnection("jdbc:hive://djt11:10000/default", "hadoop", "");
System.out.print(con.getClientInfo());
}
}元数据存储
Hive 将元数据存储在 RDBMS 中,一般常用 MySQL 和 Derby。默认情况下,Hive 元数据保存在内嵌的 Derby 数据库中,只能允许一个会话连接,只适合简单的测试。实际生产环境中不适用, 为了支持多用户会话,则需要一个独立的元数据库,使用 MySQL 作为元数据库,Hive 内部对 MySQL 提供了很好的支持,配置一个独立的元数据库需要增加以下步骤。
1) 安装 mysql 数据库。
准备工作 ,需要根据你的linux 系统版本下载对应的MySQL rpm 包。
rpm -qa | 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2137
2137











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









