









前言
前面说过,spider-flow有着非常优秀的插件机制,可以通过插件实现功能的扩展。前面有小伙伴问到mongodb的集成使用,本文就来梳理下spider-flow中使用mongodb插件的过程,其实非常简单。
PS:
spider-flow的作者已经实现了一些常用的插件,如redis、mongo、es、ocr等,开发和使用方式类似,再有其他需要可自行扩展。
使用过程
1. 引入依赖
这里提供两种方式:
- 一种是通过下载源码,本地编译,在spider-flow-web中引入
<dependency>
<groupId>org.spiderflow</groupId>
<artifactId>spider-flow-mongo</artifactId>
</dependency>
- 另外一种是在spider-flow-web中引入下载编译好的jar包
下载插件jar包并放入根目录下的lib目录下,下载地址: 点击下载插件jar包
引入方式略有差异:
<dependency>
<groupId>org.spiderflow</groupId>
<artifactId>spider-flow-mongo</artifactId>
<version>0.5.0.v20231129</version>
<scope>system</scope>
<systemPath>${project.basedir}/lib/spider-flow-mongo-0.5.0.v20231129.jar</systemPath>
</dependency>
另外 需要在build的spring-boot-maven-plugin配置中添加配置:
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
<configuration>
<includeSystemScope>true</includeSystemScope>
</configuration>
</plugin>
</plugins>
<resources>
<resource>
<directory>lib</directory>
<targetPath>/BOOT-INF/lib/</targetPath>
<includes>
<include>**/*.jar</include>
</includes>
</resource>
</resources>
</build>
再遇到问题可以先百度,解决不掉的可以留言。
2. spider-flow数据库执行如下sql
SET FOREIGN_KEY_CHECKS=0;
DROP TABLE IF EXISTS `sp_mongo`;
CREATE TABLE `sp_mongo` (
`id` varchar(32) NOT NULL,
`name` varchar(64) DEFAULT NULL,
`alias` varchar(32) DEFAULT NULL,
`host` varchar(64) DEFAULT NULL,
`port` int(6) DEFAULT NULL,
`database` varchar(64) DEFAULT NULL,
`username` varchar(32) DEFAULT NULL,
`password` varchar(32) DEFAULT NULL,
`create_date` datetime DEFAULT CURRENT_TIMESTAMP,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
3. 准备mongodb数据源
这个步骤是我自己搭建环境测试的步骤,如果已经有对应数据源,本步骤可忽略。
安装docker并执行如下命令:
docker run -it --restart always --net host --name mongo -d mongo
运行完成后使用如下命令查看日志:
docker logs -f mongo --tail 200
启动成功后执行如下命令进入容器:
docker exec -it mongo mongosh
创建collection及用户并完成用户授权
use aa;
db.createUser({user: 'root', pwd: '123456',
roles:[{role:"root",db:"admin"}]})
这样就可以使用root用户访问mongodb的aa数据库了。
其他关于mongodb的使用命令可自行百度完成,也欢迎留言讨论。
4. 启动spider-flow应用
正常启动后进入页面,会看到左侧菜单多出了一个Mongodbs数据源的菜单。
5.页面配置及测试
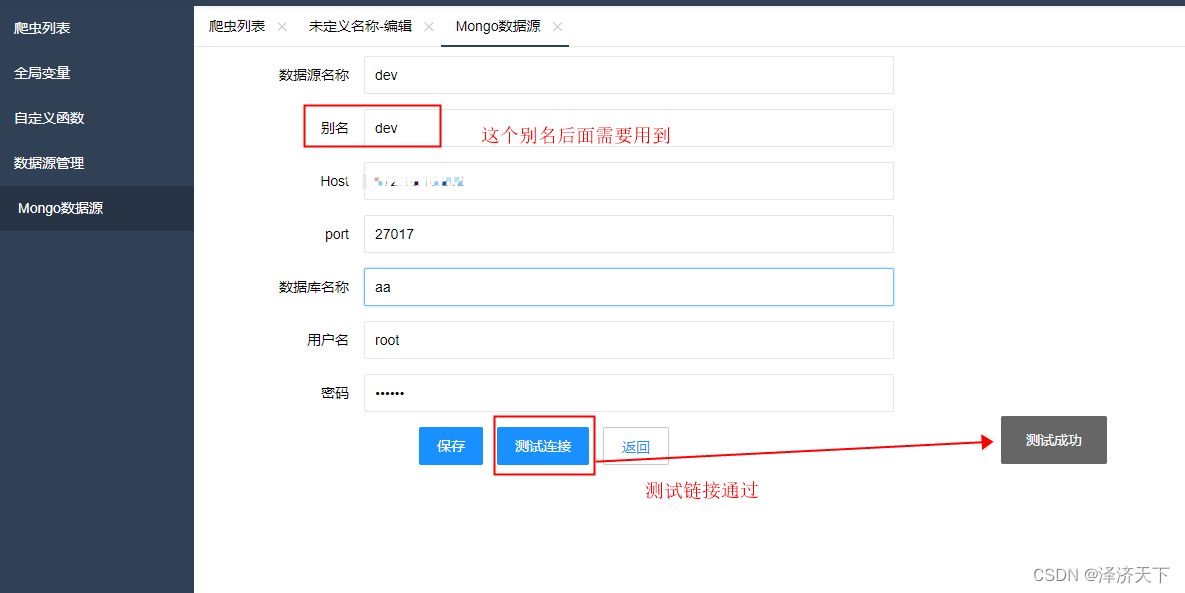
1. 配置数据源并测试通过
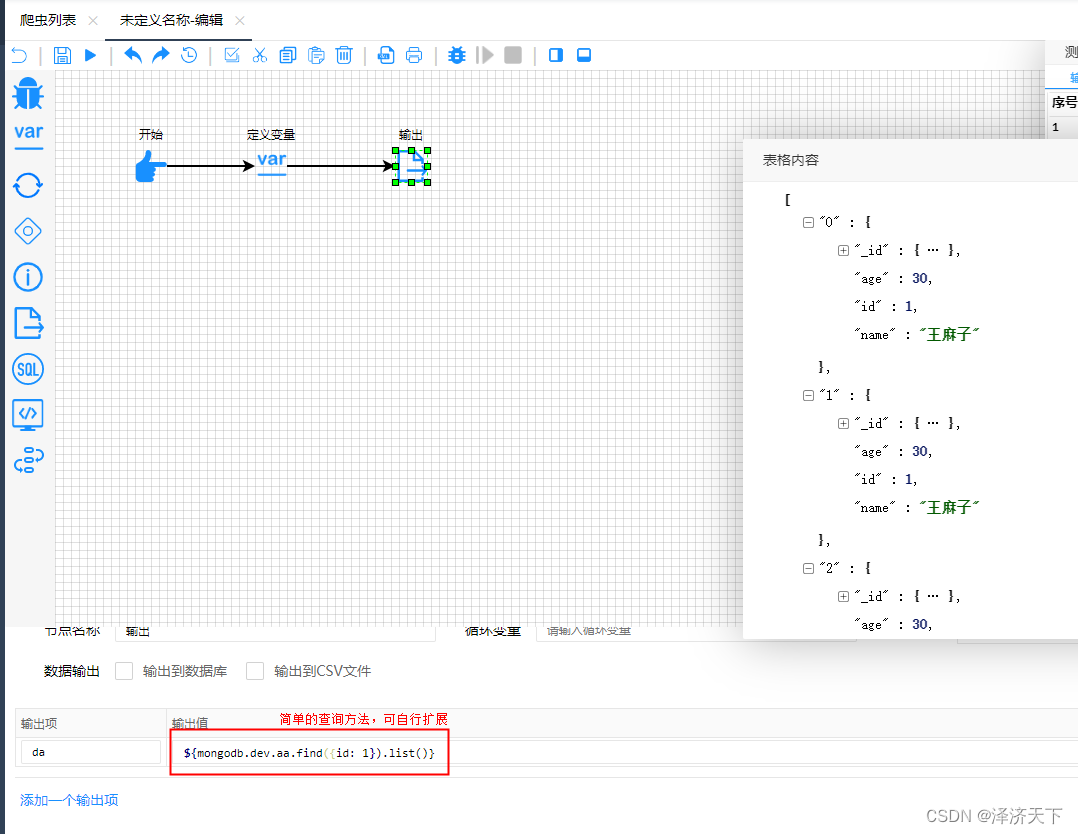
2. 新增、查询测试

6. 插件已提供的部分语法说明
| 功能 | 语法示例 |
|---|---|
| 新增 | ${mongodb.aliasName.collectionName.insert({key : value})} |
| 新增多条 | ${mongodb.aliasName.collectionName.insert([{key : value},{key : value}])} |
| 编辑 | ${mongodb.aliasName.collectionName.update({key : oldValue},{key : newValue})} |
| 编辑多条 | ${mongodb.aliasName.collectionName.updateMany({key : oldValue},{key : newValue})} |
| 删除 | ${mongodb.aliasName.collectionName.remove({key : value})} |
| 查询 | ${mongodb.aliasName.collectionName.find({key : value}).list()} |
源码简说
spiderflow的插件机制设计还是非常优秀的,扩展插件也非常容易。
对应文中mongodb插件代码结构如下:
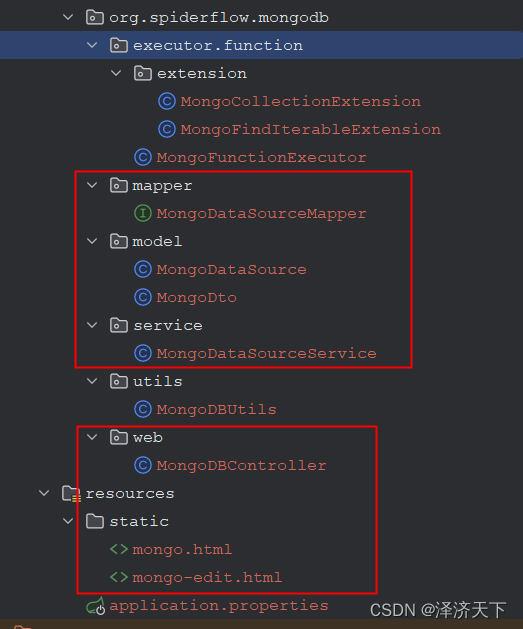
图中红色框起来的部分是为了完成mongodb数据源的增删改查操作的
其余的executor和extension结尾的类才是真正完成功能的。
其中MongoFunctionExecutor.java实现了FunctionExecutor接口,完成的是具体连接mongodb和对mongodb数据进行增删改查的方法,而MongoCollectionExtension.java实现了FunctionExtension接口,完成的是对外也就是爬虫页面上使用到的相关方法。
如果查看过其他插件源码的话,可以发现基本插件实现逻辑都是一致的,关键的接口也就是上面提到的FunctionExecutor接口 和 FunctionExtension接口,有兴趣的可以多研究研究源码,
如果有其他插件开发需求,也可以一起讨论完成,欢迎评论区留言。
总结
整体来说,拆件的使用流程还是非常清晰流畅的,引入依赖->添加相关配置->部署、应用、测试。
作为记录的同时也希望能帮助到需要的朋友。
针对以上内容有任何疑问或者建议,欢迎评论区留言讨论。
创作不易,欢迎一键三连。

















 6380
6380











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











